ZOTAC RTX 3090 Trinity Deep Learning Benchmarks
Before we begin, we wanted to note that over time we expect performance to improve for these cards as NVIDIA’s drivers and CUDA infrastructure matures.
ResNet-50 Inferencing in TensorRT using Tensor Cores
ImageNet is an image classification database launched in 2007 designed for use in visual object recognition research. Organized by the WordNet hierarchy, hundreds of image examples represent each node (or category of specific nouns).
In our benchmarks for Inferencing, a ResNet50 Model trained in Caffe will be run using the command line as follows.
nvidia-docker run --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -v ~/Downloads/models/:/models -w /opt/tensorrt/bin nvcr.io/nvidia/tensorrt:20.11-py3 trtexec --deploy=/models/ResNet-50-deploy.prototxt --model=/models/ResNet-50-model.caffemodel --output=prob --batch=16 --iterations=500 --fp16
Options are:
–deploy: Path to the Caffe deploy (.prototxt) file used for training the model
–model: Path to the model (.caffemodel)
–output: Output blob name
–batch: Batch size to use for inferencing
–iterations: The number of iterations to run
–int8: Use INT8 precision
–fp16: Use FP16 precision (for Volta or Turing GPUs), no specification will equal FP32
We can change the batch size to 16, 32, 64, 128 and precision to INT8, FP16, and FP32.
The results are Inference Latency (in sec).
If we take the batch size / Latency, that will equal the Throughput (images/sec) which we plot on our charts.
We also found that this benchmark does not use two GPUs; it only runs on a single GPU.
You can, however, run different instances on each GPU using commands like.
“`NV_GPUS=0 nvidia-docker run … &
NV_GPUS=1 nvidia-docker run … &“`
With these commands, a user can scale workloads across many GPUs.
Also one can use the —device=0,1,2,3,4,… a command to select which GPU to run on, more on this later.
We start with INT8 mode.
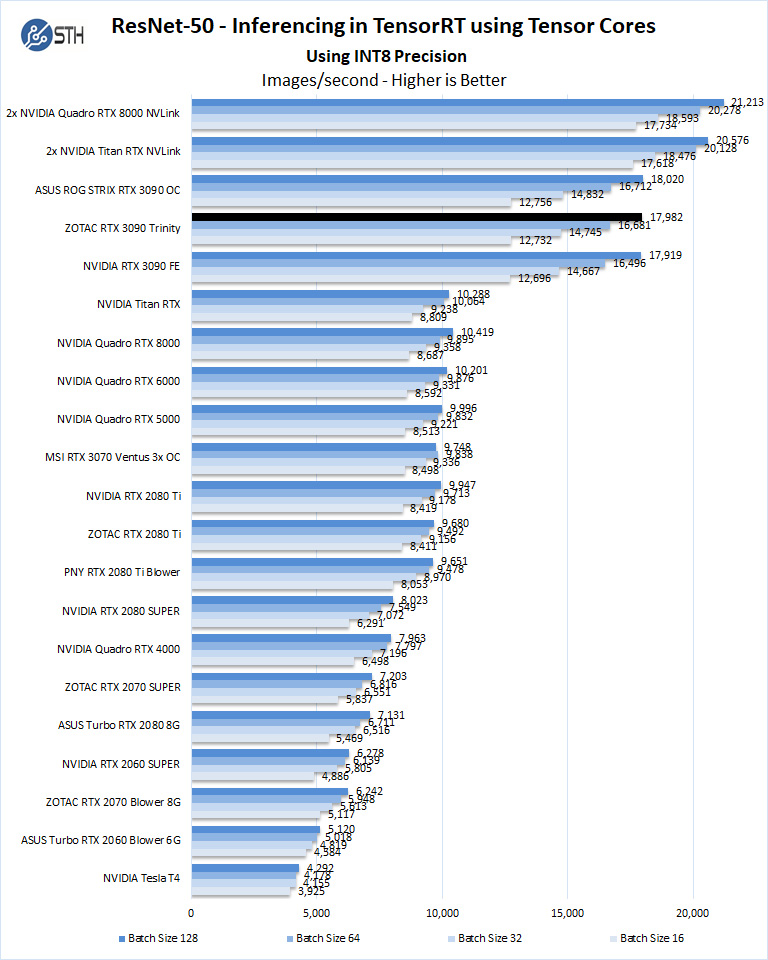
Using the precision of INT8 is by far the fastest inferencing method if at all possible, converting code to INT8 will yield faster runs. Installed memory has one of the most significant impacts on these benchmarks. Inferencing on NVIDIA RTX graphics cards does not tax the GPUs to a great deal. However, additional memory allows for larger batch sizes.
Let us look at FP16 and FP32 results.
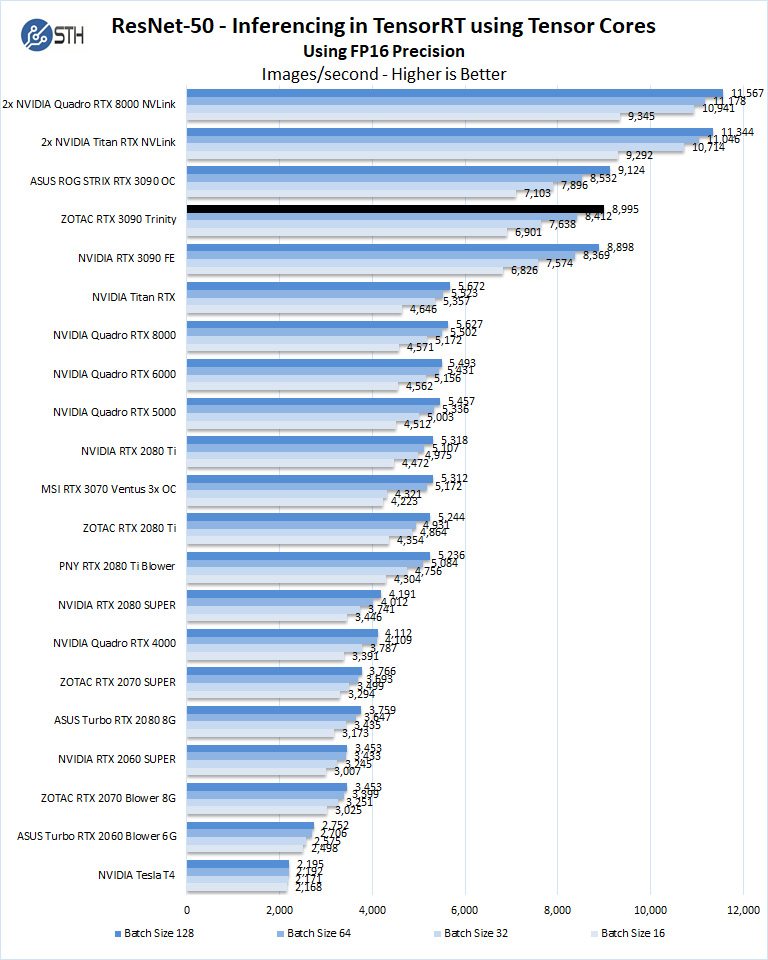
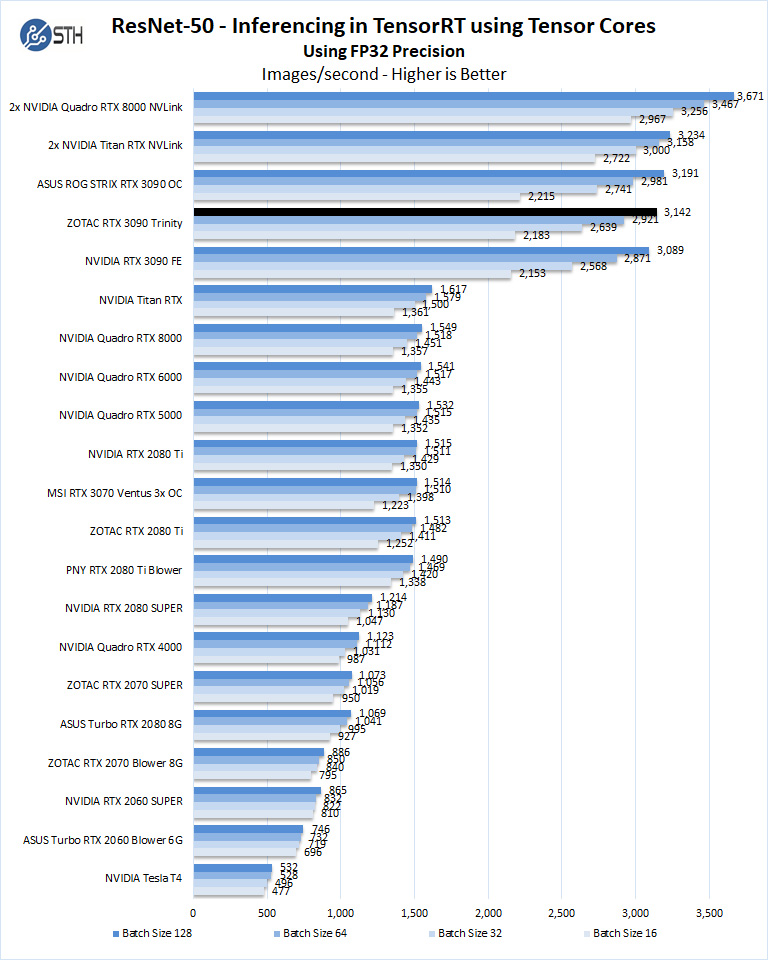
Looking beyond the immediate RTX 3090 competition, here the GeForce RTX 3090 opens a huge gap between it and the Turing-based RTX 2000 series.
ResNet-50 Training, using Tensor Cores
We also wanted to train the venerable ResNet-50 using Tensorflow. During training, the neural network is learning features of images, (e.g., objects, animals, etc.) and determining what features are important. Periodically (every 1000 iterations), the neural network will test itself against the test set to determine training loss, which affects the accuracy of training the network. Accuracy can be increased through repetition (or running a higher number of epochs.)
The command line we will use is.
nvidia-docker run --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v ~/Downloads/imagenet12tf:/imagenet --rm -w /workspace/nvidia-examples/cnn/ nvcr.io/nvidia/tensorflow:20.11-tf2-py3 python resnet.py --data_dir=/imagenet --batch_size=128 --iter_unit=batch --num_iter=500 --display_every=20 --precision=fp16
Parameters for resnet.py:
–layers: The number of neural network layers to use, i.e. 50.
–batch_size or -b: The number of ImageNet sample images to use for training the network per iteration. Increasing the batch size will typically increase training performance.
–iter_unit or -u: Specify whether to run batches or epochs.
–num_iter or -i: The number of batches or iterations to run, i.e. 500.
–display_every: How frequently training performance will be displayed, i.e. every 20 batches.
–precision: Specify FP32 or FP16 precision, which also enables TensorCore math for Volta, Turing and AmpereGPUs.
While this script TensorFlow cannot specify individual GPUs to use, they can be specified by
setting export CUDA_VISIBLE_DEVICES= separated by commas (i.e. 0,1,2,3) within the Docker container workspace.
We will run batch sizes of 16, 32, 64, 128, and change from FP16 to FP32.
Some GPU’s like RTX 2060, RTX 2070, RTX 3070, RTX 2080, and RTX 2080 Ti will not show some batch runs because of limited memory.
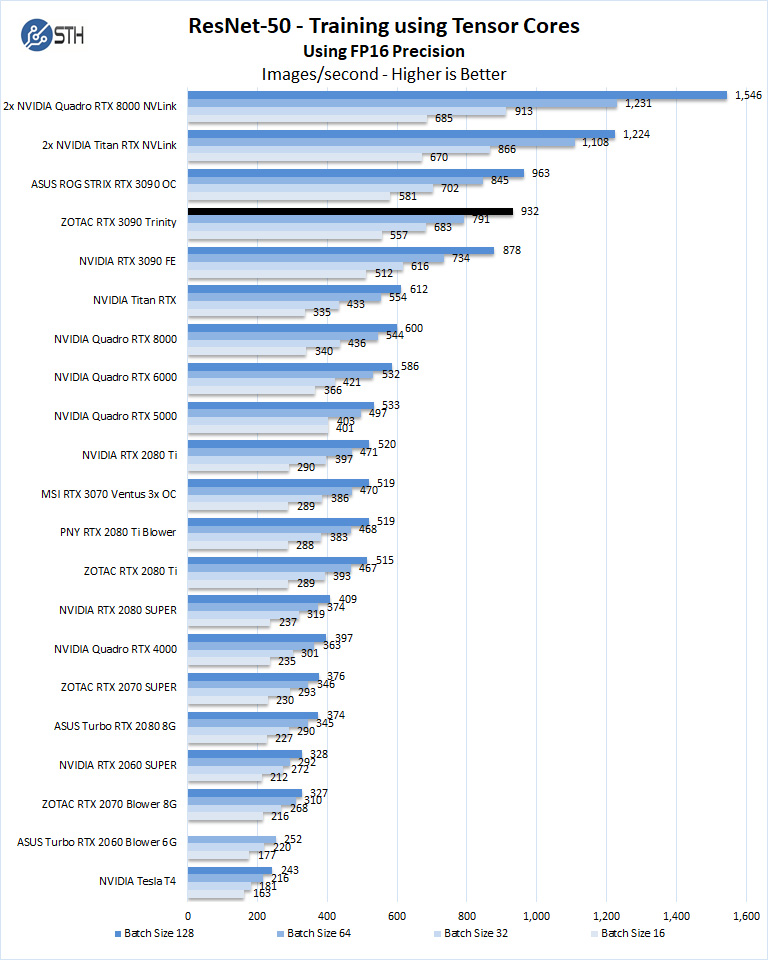
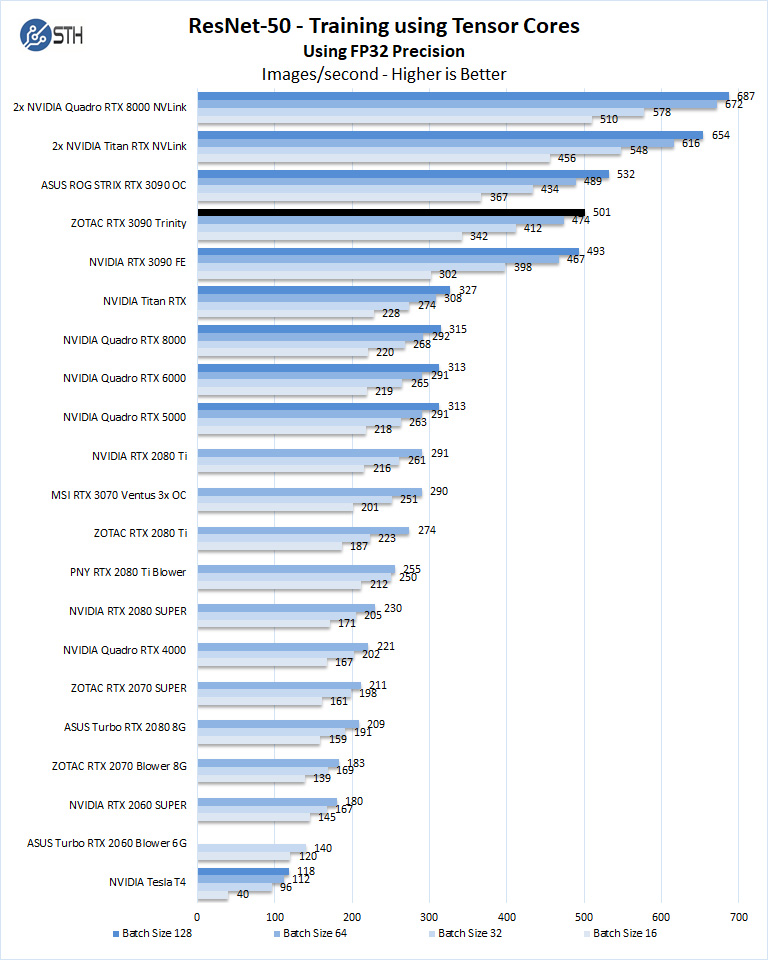
The ZOTAC RTX 3090 Trinity compares well to similar GPUs. If you compare the performance of the GeForce RTX 2080 Ti and Quadro RTX 6000 / Quadro RTX 8000 cards, one can immediately see the benefit of the newer architecture.
Training using OpenSeq2Seq (GNMT)
While Resnet-50 is a Convolutional Neural Network (CNN) that is typically used for image classification, Recurrent Neural Networks (RNN) such as Google Neural Machine Translation (GNMT) are used for applications such as real-time language translations.
The command line we use for OpenSeq2Seq (GNMT) is as follows.
nvidia-docker run -it --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v ~/Downloads/OpenSeq2Seq/wmt16_de_en:/opt/tensorflow/nvidia-examples/OpenSeq2Seq/wmt16_de_en -w /workspace/nvidia-examples/OpenSeq2Seq/ nvcr.io/nvidia/tensorflow:20.11-tf2-py3
We then open the en_de_gnmt-like-4GPUs.py and edit our variables.
vi example_configs/text2text/en-de/en-de-gnmt-like-4GPUs.py
First, edit data_root to point to the below path:
data_root = “/opt/tensorflow/nvidia-examples/OpenSeq2Seq/wmt16_de_en/”
Additionally, edit the num_gpus, max_steps, and batch_size_per_gpu parameters under
base_prams to set the number of GPUs, run a lower number of steps (i.e. 500) for
benchmarking, and also to set the batch size:
base_params = {
...
"num_gpus": 1,
"max_steps": 500,
"batch_size_per_gpu": 128,
...
},
Also, edit lines 44 and below as shown to enable FP16 precision:
#”dtype”: tf.float32, # to enable mixed precision, comment this
line and uncomment two below lines
“dtype”: “mixed”,
“loss_scaling”: “Backoff”,
We then run the benchmarks as follows.
python run.py –config_file example_configs/text2text/en-de/en-de-gnmt-like-4GPUs.py –mode train
The results will be Avg. Objects per second trained which we plot.
We should note that other GPU’s we used to, like the RTX 2060, RTX 2070, RTX 2080, and RTX2080 Ti could not complete this benchmark due to the lack of installed memory. To enable this benchmark to finish on these GPU’s one might need to lower the batch size to smaller values like 32, 16, 8. We tried this but had no luck. Using a batch size four could be run but it was decided that this was not a very usable size.
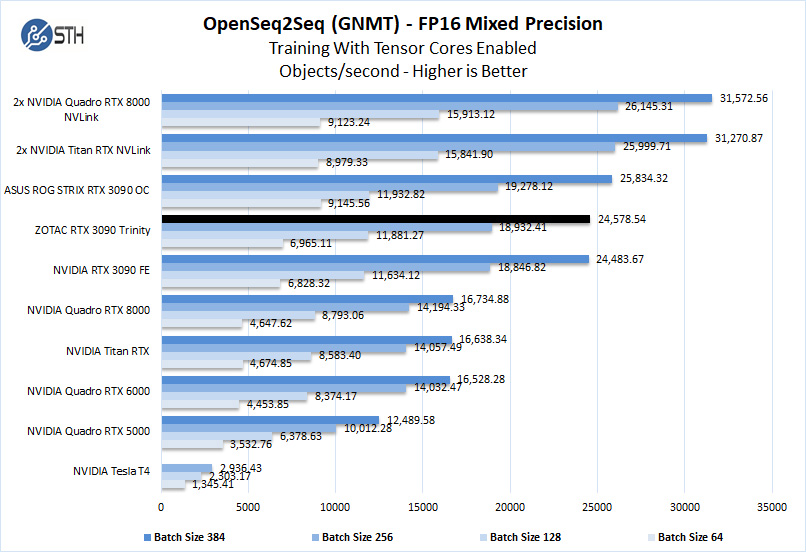
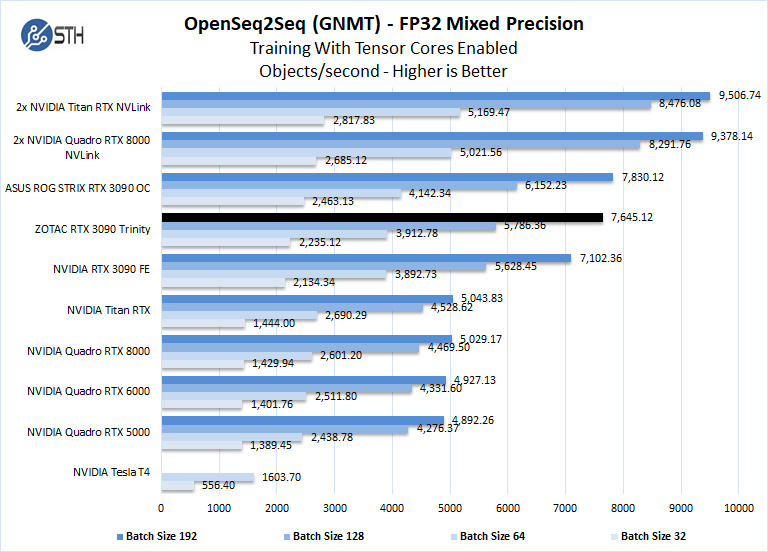
The ZOTAC RTX 3090 Trinity has 24GB of installed memory, equal to that of the Titan RTX. The Quadro RTX 8000 includes 48GB of installed memory, which can train larger models than what we have here while keeping within the card’s memory footprint. Still, we see the RTX 3090 GPUs are very powerful in deep learning workloads. Here the ZOTAC RTX 3090 Trinity compares well to the other RTX 3090 GPUs.
Next, we will look at the ZOTAC RTX 3090 Trinity power and temperature tests and then give our final words.



{kind=link}
Really bugs me that these things are getting wider, wider, and wider. As if taking up two slots wasn’t bad enough–now it won’t even fit into two? I mean seriously, who’s got THREE slots to spare in a case these days? And “2.5” isn’t any better than “3” as it’s still going to block two otherwise usable slots.
William, what dataset do you use for the Caffe tests, and what are the image dimensions? Thanks!
Estás placas vêem com defeito de fábrica. Não duram um ano. São poços resistente, a umidade e não o desempenho tão bom assim.