
Xilinx recently held a discussion with Victor Peng, the new CEO of Xilinx. A major thrust of the conversation the company’s data center first approach to the market and how Xilinx is changing is posture focusing on a broader software developer community. We had the opportunity to get a few items answered on this front. The other major area of focus was a new class of product for Xilinx, the project Everest ACAP which is a new 7nm TSMC design due this year with some excellent features.
Xilinx Data Center First Strategy
The first part of the discussion was around how Xilinx is moving beyond the FPGA developer ecosystem and into a broader ecosystem of software developers. This is done through bringing the libraries and tools needed for traditional software developers to easily access Xilinx products.
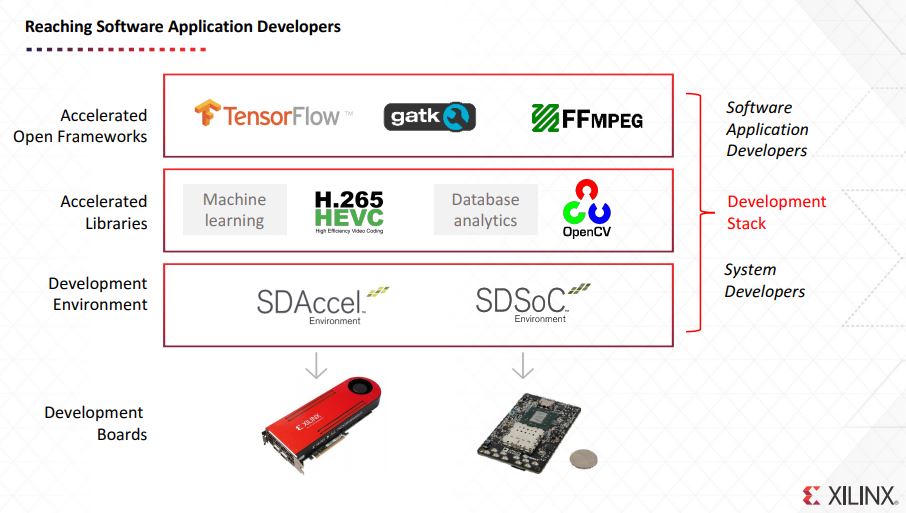
A great example of this is TensorFlow where there are many developers who develop their deep learning / AI applications exclusively for TensorFlow. These same developers are unlikely to also have experience developing FPGA logic. Xilinx has a significant effort underway to bridge the gap so, for example, models using TensorFlow can access Xilinx FPGAs to accelerate inferencing over what is currently done on CPUs and GPUs.
CPUs and GPUs, or more precisely, NVIDIA GPUs, have a major ecosystem that allows developers to specialize in different parts of the stack. NVIDIA CUDA and x86 training and inferencing is widely supported, as is ARM compute. Xilinx has become the “not-Intel” which is significant because there are many parties out there that either desire an alternative to Intel or do not want to use Intel in their stack as Intel (and now by acquisition Altera) is a competitor.

We asked a few questions regarding this software and ecosystem push, along with what it will take to get the ecosystem primed on the next page of this article.
Xilinx is quick to point out that its FPGAs can provide significant speedups for many types of applications while also having the programmability of FPGAs.
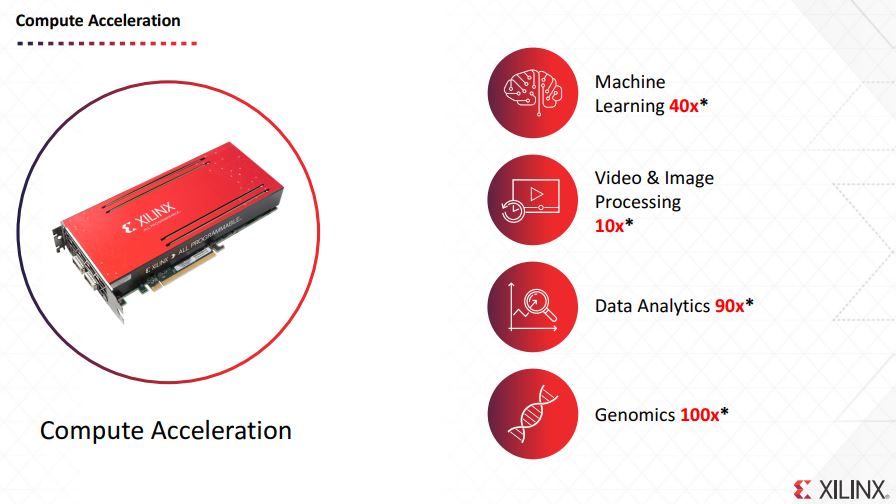
While those numbers may seem compelling, and they are, they may not be the most direct comparison points. For example, the Machine Learning 40x is impressive but the footnotes show the comparison is noted as:
40x Deephi LSTM inference. KU060 vs Xeon Core i7 5930k. Xilinx delivers 43x perf and 40x perf/watt versus Xeon. Perf = Latency reduction.
That does not make the results necessarily less impressive, but it is using two generation old hardware on the Intel side.
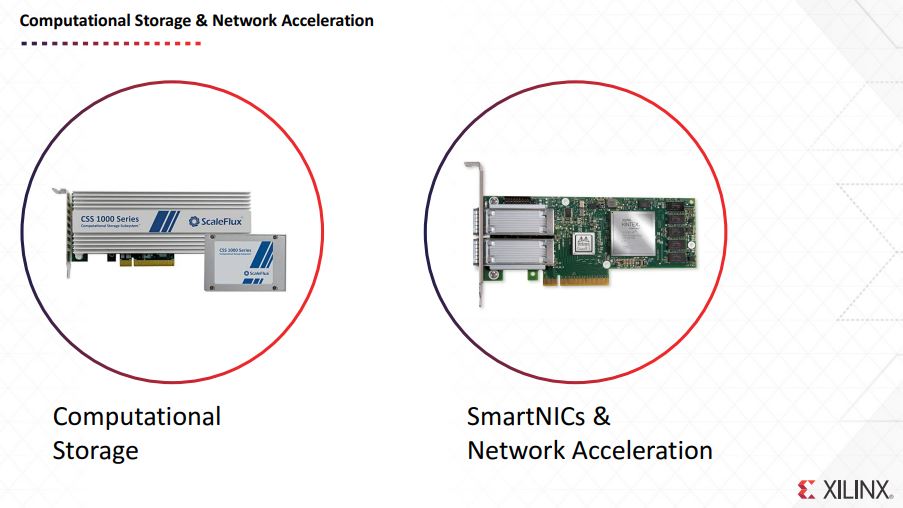
Xilinx also shows off its computational storage and network acceleration. At STH, we touched on the Mellanox and Xilinx FPGA NIC solution in late 2017.
A major thrust of the discussion is the ACAP which stands for Adaptive Compute Acceleration Platform. Essentially, if you are thinking about using heterogeneous compute resources in your architecture, this is the next step where there are specific acceleration blocks.
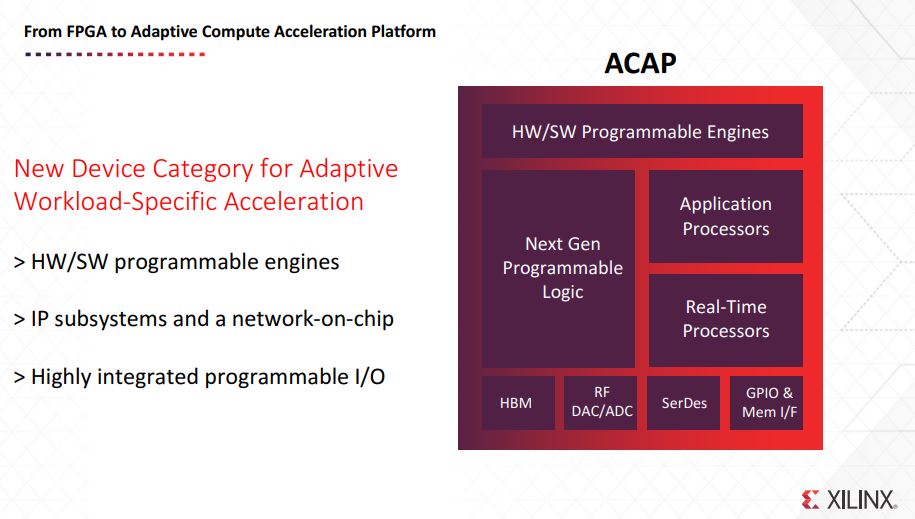
Having these application processors along with programmable logic, high-speed HBM(2) memory, SerDes, and a high speed interconnect mean that Xilinx believes it has cracked the code for next-generation acceleration.
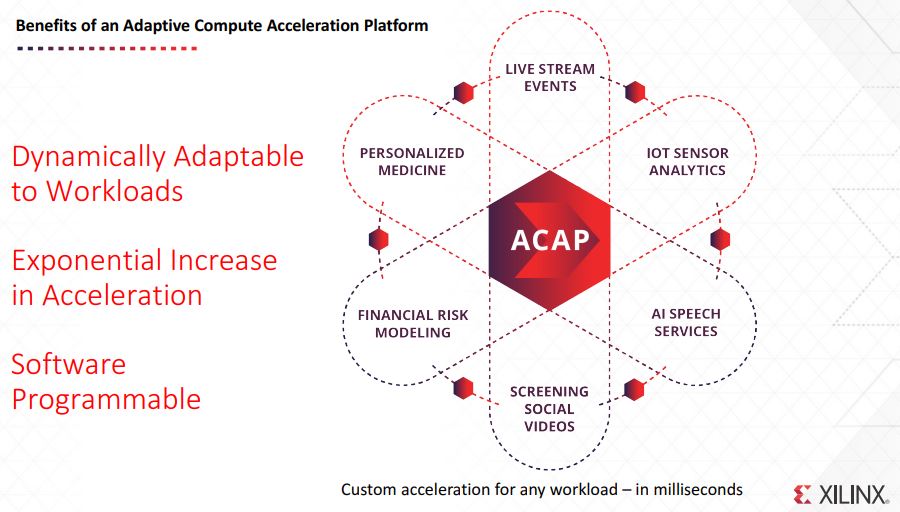
Looking ahead, the company is announcing Project “Everest” as its first 7nm ACAP product family coming later this year and in 2019.



{kind=link}