
The Xilinx Alveo U55C marks a new push by the company to get into the HPC accelerator market, and with a fairly unique angle. Specifically, Xilinx has a device with networking, FPGA logic space, and HBM designed to accelerate some high-performance workloads. Let us get into this announcement.
Xilinx Alveo U55C Brings HBM FPGAs to the HPC Market
The Xilinx Alveo U55C is in some ways a way for Xilinx to uniquely enter a market currently dominated by NVIDIA. What Xilinx has here, is basically a smaller version of NVIDIA’s vision for Grace. While that may seem far fetched at first, the Alveo U55C has high-speed network fabric, its own control processor, the ability to accelerate workloads using programmable acceleration, and high-bandwidth memory all in a single card. NVIDIA’s Grace is still years out, but this vision is here today with the Xilinx Alveo U55C (note NVIDIA has the BlueField-2 A100 that is its offering today, yet it is not as generally available.)

The basic idea here is that Xilinx allows one to create customized accelerator logic on the card attached to 16GB of HBM2. If data comes in off of a network interface, it does not need to go through to the host system. The acceleration can be pipelined directly on card.
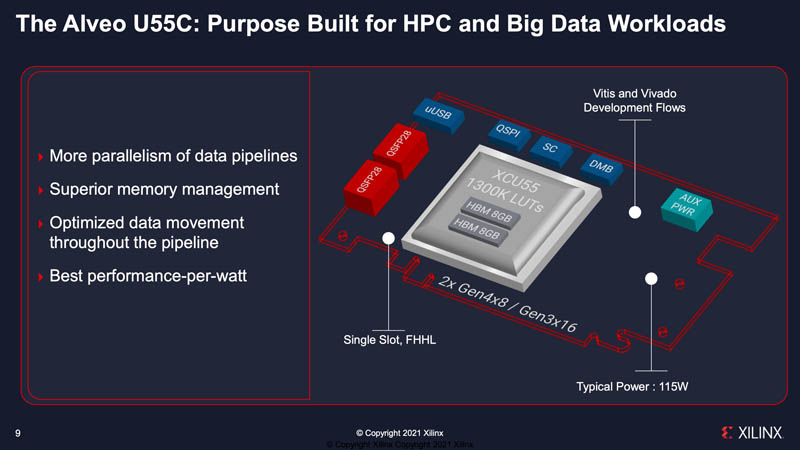
Here are the key specs for the U55C. There are a few points worth noting. First, Xilinx is comparing this to the Alveo U280, but there are some major differences. The U55C doubles the HBM2 memory, but it loses the DDR4 memory. The other key difference is the card is now a single slot solution instead of a dual slot solution. It also supports DDR4. One other interesting item is that the typical power is up from 100W to 115W but the maximum power is only 150W instead of 225W. That makes it much easier to integrate into systems, especially in constrained power deployments.

A bit of context here is also important. While one often thinks of HPC accelerators as the big 500W+ GPUs that sit in centralized supercomputers, there are a lot of workloads that are more distributed.
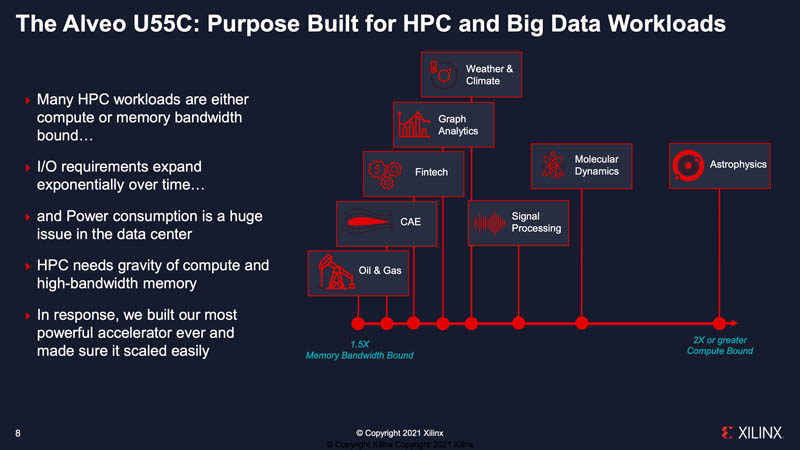
A great example of this is the CSIRO case study. The way to think about this one is that these cards are deployed across a vast radio astronomy antenna array. The IT equipment is all solar powered meaning that there are real power constraints, so these cards use less than the 115W/150W ratings and can only use 90W. Here, having the cards means that data can be ingested, and processed via a custom pipeline in the FPGA fabric leveraging HBM2. Cards like the NVIDIA T4 and NVIDIA A2 do not have HBM onboard nor do they have networking. So a single slot means fewer boxes and lower overall power consumption.

Beyond these scientific HPC pursuits, Xilinx is discussing results of acceleration with LS-DYNA. This is an area where a large portion of the simulations can be performed in a custom logic on the FPGA fabric. Then the constraint becomes memory bandwidth and that is where the HBM2 comes in. We will just quickly note that the comparison here is the Intel Xeon Platinum 8260L a 2019 era processor with 24 cores and 35.75MB of cache. We now have the AMD Milan-X with 64 cores and 0.75GB of L3 cache. That L3 cache is designed to offer a significant speedup by avoiding the need to go to slower DDR4, much like HBM is used although at different latency/ capacity tiers.
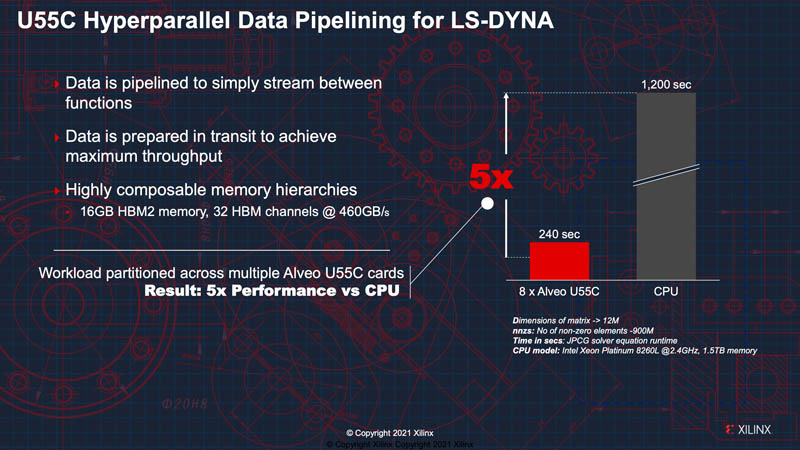
We asked about pricing for the Xilinx accelerated LS-DYNA but did not get an answer as to how it compares.
Beyond a single card, Xilinx is looking at scaling out the architecture to multiple cards so it has features like RoCE v2 and MPI capabilities. These are capabilities required for scale out workloads.

Vitis is Xilinx’s software platform that allows developers to work within familiar frameworks and not have to place logic on FPGAs. Xilinx has been putting a lot of effort into this to make it easier to use its products.
Here is an example of how this translates into HPC-style domains:

Of course, this is a newer entrant into many of these spaces so having easily accessible software tools is very important.
Final Words
It is refreshing to see something different. This is a lot of innovation fitting functionality into a 150W single slot power envelope. At STH we have been reviewing servers with 4x 400W or 8x 300W GPUs over the past few days and then add another several hundred watts for CPUs and NICs. Having an integrated solution, critically with HBM2 is certainly something different.
For those wondering, you can purchase the Xilinx Alveo U55C on Xilinx.com. Xilinx is also working on getting these cards into various partner clouds.

Still, this is one of the more unique and interesting solutions that we are seeing at SC21. There are a ton of domains where next-generation 500-600W accelerators are great, but there are others where they are simply not practical. The big question is really around whether Vitis can unlock the power of the U55C over the next few quarters to help the cards gain adoption.



{kind=link}
One can understand why NVIDIA is desperate to buy ARM.
NVIDIA does not give a [expletive] about the future of ARM in cell phones, appliances, consoles, SBCs, industrial boxes, etc. NVIDIA just wants to own a CPU architecture to fight for data center, hyperscaling, exascaling and enterprise domination against INTEL and AMD.
NVIDIA is still ahead of INTEL and AMD for compute with CUDA. But AMD is progressively catching up with ROCm + Xilinx and INTEL with oneAPI and its multiple acquisitions in this domain.
This puts NVIDIA in a difficult position for the future: not having an in-house CPU architecture is a big no-no in this war.
“The U55C doubles the HBM2 memory, but it loses the DDR4 memory. […] It also supports DDR4.” Something is weird with context here or there is an error.
I think it was very wise of AMD to bring Xilinx in house. They are a very tightly ran engineering shop and can only help further AMD’s processes and future development.