DDR5’s On-Chip ECC
DDR5 has on-chip ECC. This is one that is often misunderstood. Make no mistake, this is a good step, but it does not mean that all DIMMs have the same ECC and RAS functionality as server RDIMMs have traditionally had.
One can think of this ECC as protecting against a bit on the DDR5 chip flipping as a standard feature. The sideband functionality to ensure end-to-end data protection is what is the benefit of the server RDIMM.

While many are at first touting this as a feature, it also serves a practical purpose. As DRAM density increases and clock speeds increase as well, the folks designing the DDR5 spec realized that the combination has the potential to lead to more on-die errors. For those more familiar with flash technology, NAND has been going through this for years, and now we have higher bit density but also more error correction throughout the SSD. Still, the inherent on-chip ECC benefit is that issues that may not have been caught previously on consumer UDIMMs can potentially be caught.

In addition to this, there is actually more ECC happening between the DIMM and the host DDR5 controller. This is because we went from a 72-bit (64+8) to an 80-bit (two 32+8) channel architecture for most DDR5. There are some specialty applications that will still use 72-bit to save some cost, but that will likely be the exception rather than the norm. All told, we go from ~11% to 20% of the channel bits being used for ECC.
Practical Examples of Why This Matters
Part of testing servers at STH entails finding which workloads we will use. One of the big challenges is profiling workloads to figure out how they will scale. For example, we often use workloads in our CPU benchmarks that scale mostly with a CPU’s instructions per clock, frequency, and core count. Rendering workloads are usually a great example of this. Other times, we find workloads that are highly memory capacity bound. In a large number of servers, memory capacity is another major challenge. DDR5 allows for larger DIMM sizes, including 128GB UDIMMs. Here is a virtualization workload where we can vary the core counts and see that the performance increases stop when we run out of memory.
Memory bandwidth is another constraint we find. Here is a great example of a workload where we were pushing data so fast through the system that adding cores or even increasing frequency in the same number of cores did not help after we became memory bandwidth limited:
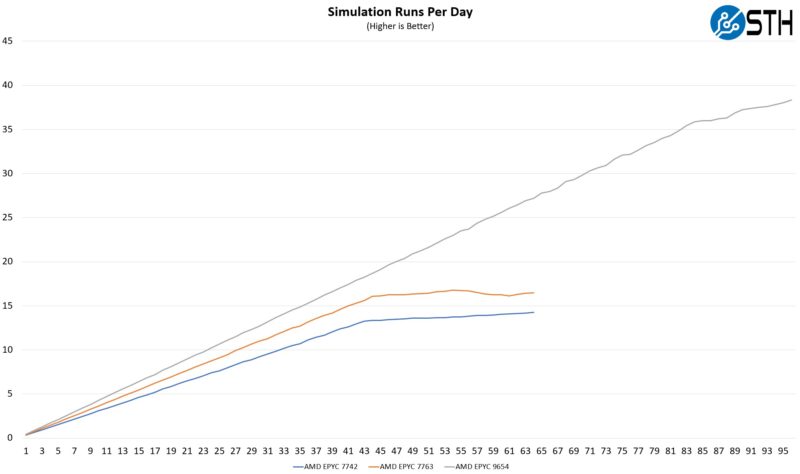
Switching to a newer platform, we can see the impact of DDR5 immediately. A workload that did not respond to increased frequency or core count, is suddenly able to take advantage of more compute resources after transitioning to a newer DDR5 platform.
That is a prime example of why the transition to DDR5 matters. To illustrate this in another way, here are the new systems added to the Top 500 list in November 2022:
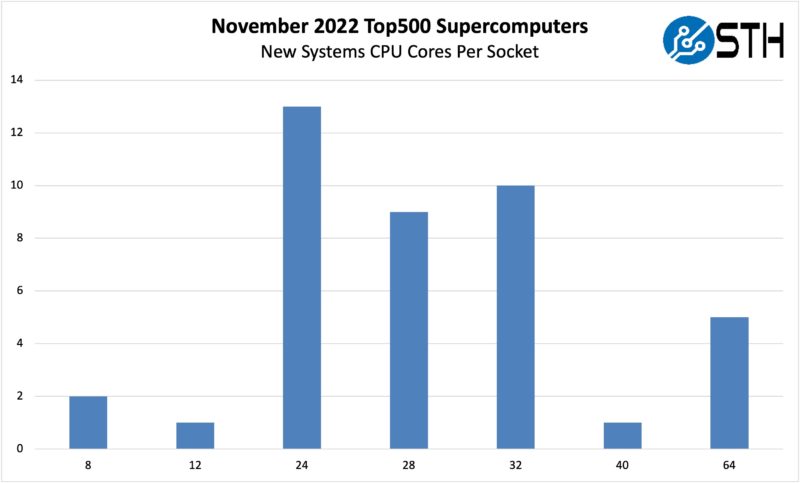
One will quickly notice that the systems deployed were not all using the maximum core count parts. That is because memory bandwidth is often the limiting factor in HPC applications. We have seen a number of novel approaches such as the larger caches of Milan-X to the co-packaging of GDDR memory and HBM memory to address this challenge. For the general-purpose market, transitioning to DDR5 is a big step in the right direction.
CXL Type-3 Devices and DDR5
Let us, for a moment, discuss CXL or Compute Express Link. CXL allows for load/store operations to occur over PCIe Gen5 physical links using the alternative CXL protocol. This new generation of servers supports CXL 1.1, the first time we are getting that functionality in servers. Type-3 devices are effectively memory expansion devices. Here is an Astera Labs Leo CXL memory expansion device.

As one can see, there are four DDR5 DIMM slots onboard and a PCIe Gen5 x16 connector on the bottom of the board. Using this device in a server yields bandwidth roughly comparable to two channels of DDR5 memory through the x16 slot. Latency is roughly the same as accessing memory across a coherent processor-to-processor link (e.g. CPU1 accessing memory attached to CPU2.) In systems, this shows up as another NUMA node without CPU cores attached but with memory attached. We are going to do a more in-depth piece on this.
In this generation, AMD EPYC 9004 “Genoa” officially supports CXL 1.1 Type-3 devices. Intel’s Sapphire Rapids Xeons support all of the underlying protocols, and the card shown above works in Sapphire Rapids servers, we have seen demos for some time. Intel is just not supporting Type-3 devices at launch.
Still, the big takeaway should be that DDR5 is not just going to be limited to DIMMs directly next to CPU sockets. Instead, as we get further into 2023 and beyond, many of the CXL Type-3 devices are being designed to support DDR5 memory.
Final Words
Many memory vendors come up with elaborate marketing materials explaining the benefits of DDR5 and why you should switch. At STH, we have a simple answer: At some point, you do not have a choice.

Both the AMD EPYC 9004 Genoa and 4th Generation Intel Xeon Scalable Sapphire Rapids parts only support DDR5. If you purchase servers and you want a new generation x86 server, DDR5 is your only option (save for the Xeon Max installations utilizing only onboard HBM2e.)

Overall, between increased performance per core and increased core counts, DDR5 memory is needed to move the server industry forward.



{kind=link}
If you’re reading this, page 2 is where it’s at. I learned more in 5 minutes reading through that then everything I’ve seen on Reg DIMMs before.
Thanks to STH for this article +1
This is sooooooooooooo gooood. I’d +1 Uzman77’s rep on the 2nd page. That’s the best explanation I’ve ever seen. I’m usually only on STH to troll comments, but that was useful
I find it disappointing that a new higher-bandwidth higher-capacity higher-latency memory standard has been developed and people are still considering non-ECC DIMMs.
At the frequencies and densities where DDR5 makes sense, I think allowing the CPU to verify RAM integrity using ECC is important. Even if rowhammer and other ways of inducing memory errors through code didn’t exist, the tradeoff between reliability, the associated costs of memory corruption and adding two more chips per DIMM favours ECC, at least in my opinion.
It would be nice explore the ECC DDR5 options available for desktop computers.
TL;DR
1. We need DDR5 over DDR4 because capacity, more memory channels on server CPUs for DDR5 and higher bandwidth
2. U can’t use UDIMM anymore BC… you can’t use UDIMM anymore.
3. 2-channel DDR5 hack is in no way fundamental. It’s just a hack. But for some reason you have to have it.
Yes DDR5 has bigger burst step, but that was the case at any generation change…
4. On chip ECC – another bullshit fudge, heavilly used by marketing. In reality, DDR5 RAM cell shrinkage has dropped its reliability too low, so that had to be countered on-chip. So, it’s not an improvement but a patch for a cell, that can’t be shrunk without a compromise.
TIL – That you can’t use ECC UDIMMs in an RDIMM server with DDR5
… I have to ask, how much is that half tray of RAM worth in the second to last picture?!?!
Nice little AMD fluff piece.
Is the latest AMD even shipping? I have 13 dual socket Supermicro 1U servers – each with SPR and 2TB DDR5 ECC – not to mention 16 Supermicro dual socket workstations – each with a single SPR and 1TB DDR5 ECC – they will go great with the 16 GPU DGX H100…
“4. On chip ECC – another bullshit fudge, heavilly used by marketing. In reality, DDR5 RAM cell shrinkage has dropped its reliability too low, so that had to be countered on-chip. So, it’s not an improvement but a patch for a cell, that can’t be shrunk without a compromise.”
DDR5 has on chip ECC. It is from Engineering, not Marketing. What is your basis for claiming that reliability is too low? The Gnome living in your nightstand does not count as a source.
So many Desktop kiddies thinking they know something about servers.
How about Dr. Ian Cutress? https://www.youtube.com/watch?v=XGwcPzBJCh0&t=3m33s
Minie was talking about the cell reliability without this correction. The point is that on-die ECC exists because with increasing density the factors causing bit-flips have increased to the point that it’s impossible to get a low enough defect rate without some form of built-in correction.
Ummm….way to ignore CAS latency pretty much entirely. It’s why, to this day, top end DDR4 kits will outperform even up to mid-range DDR5 kits. Hell, they’ll even outperform some of the lower top-end DDR5 kits. CAS latency is supreme. In desktop environments and ESPECIALLY server environments.
Also, this supposed “dual channel” thing they talk about, which is a grossly incorrect term, is reminiscent of the AMD bulldozer days where they’d claim they were splitting up the load between “cores”, but it was still only one pipe going out of the processor, this negating any real world benefit.
The main reason that DDR5 systems perform better is because the platforms and CPU architectures are better. It’s got very little to do with the RAM itself.
Another great article by STH. Bravo lads.
Joe I’m seeing like $168 per so $4k.
Dissident Aggressor. I don’t see how it’s an AMD fluff piece. It is nice that you’ve only got a few servers. The DRAM vendors Samsung, Hynix, and Micron all talk about the bit flips in technical conferences. I can tell you from experience that even DDR4 had massive issues. We’ve got hundreds of thousands of DDR4 modules installed in just the data center I’m responsible for. The newer 1x modules saw an increase in errors. Samsung’s are much worse than they used to be. That’s why they’re doing on chip ECC with DDR5. 29 systems is less than a quarter of a rack for us and we’ve got many thousands of racks. I’m not sure who you’re talking about with the “desktop kiddies” but you sound like one based on your comments. I’ve worked at three different hyperscalers and one large social network over the last 10 years and my colleagues all are on STH because there’s good info here. Anandtech used to be good 7+ years ago.
ChipBoundary with CAS 40 is like 92-93ns on DDR5-4800 and it’s like 90ns on DDR4-3200 IIRC. So it’s like 50% more BW, the dual channel helps a small amount (we’ve measured it so that’ll make it into a paper). Between those two it’s better than DDR4 and it’s much better.
Even as far back as Sandy Bridge memory bandwidth was starting to impact some applications. It became particularly noticeable with Haswell’s AVX2 and FMA3: 4 cores were starved by 2 channels of DDR3 1600 memory and it began to make sense to underclock the CPUs.
It would be nice to have a consumer system with 16 cores and 8 sticks and not 2 to restore some balance. AVX512 needs it.
@Minie Marimba, totally agree on your point 2. Why isn’t the voltage the same. AFAIC, stepping down fron higher voltage increases efiiciency. Why are desktop DIMMs designed to be less efficient. Maybe they save 10-20 cents from the PMIC but they butcher any chance for compatibility.
This is especially strange because the industry has been moving towards 12v for everything. So the MB will probably need to have 12V->5V VR to feed the DIMMs, whereas it could just pass through the 12V it receives from the PSU. I must be wrong somewhere because this makes no sense whatsoever. Unless one is inclined to entertain the possibility that this is done specifically for market segmentation..
On point 3 – the dual channel nature is actually counterproductive. It increases the cost of ECC because you are moving from 12.5% redundancy to 25% redundancy (e.g. from 8+1 to 8+2 chips). WTF? DDR5 (as DDR4 by the way) supports in-band ECC. Sure, without a place to store the actual ECC data this can only protect the data in transit over the DDR bus but not in rest in the capacitor array. However, coupled with the internal ECC, that is even necessary at current semiconductor densities, this could have offered full ECC almost for free. Yes, almost because (1) it introduces additional cycle in the burst sequence for the transfer of ECC data and (2) because of the internal ECC overhead. However, the overhead from (1) is not more than 10% (pulled out of my ass – it’s slightly higher than 10% but you can never utilize the bus completely, so it it will not make as much difference; I would argue it’s more like 7-8% in real life situations). And (2) is already used anyway. And when you have the ECC over an entire internal row, istead of 32-bit only, you can have much lower overhead and/or better protection, e.g. correct several errouneous bits.
Again, I’m probably wrong somewhere because the state of affairs does not jive with what the techonologies can provide. One reason might be that memory chips are designed to be as simple as possibly because you need many of them and any overhead can hit hard. But, I would argue, not as hard as an additional chip for every rank in a module.
Just my 22 cents
@Nikolay Mihaylov
“Unless one is inclined to entertain the possibility that this is done specifically for market segmentation..”
Looking at it in any other way indicates a lack of comprehension of how the modern economy works. Interoperability between server and desktop platforms is anathema to the manufacturers/chaebols/cartels whoever you want to blame, and it is specifically allowed to be artificially implemented [through software/firmware/unnecessary physical incompatibilities] to drive margins on “Server” gear and to keep a layer of obfuscation between consumer and pro product lines, even if the difference between a Gaming CPU and a Server CPU doesn’t necessarily warrant it.
It’s only going to get worse as Intel’s scheme to pay to enable hardware features that ship complete on the chip isn’t really getting any serious pushback.
Few correction on the CXL section :
1.
“Latency is roughly the same as accessing memory across a coherent processor-to-processor link”
Should be
“Latency is roughly the same as accessing memory across a coherent socket-to-socket link”
2.
The aim of the CXL consortium is to make the latecney of direct attached CXL in the same ballpark as of socket NUMA hop, however we are not yet there.
3.
CXL/PCIe bandwidth in bidirectional, therefore the eqvivilant raw bandwidth of the suggest card is of *four* DDR5 channels.
Too much e-peen competition in these comments.
Some of you sounds like amazing folks to have to put up with, I feel back for your co-workers.
You didn’t explain why server platforms no longer support consumer-level DIMMs. This is very upsetting, it will make those platforms prohibitively expensive to home enthusiasts even down the line when they flood the second-hand market.
They did explain it. Different operating voltage with the power management onboard. They’re now physically keyed differently.
Hello NLST
Worth reading indeed. Thanks for sharing.