5th Gen Intel Xeon v. 4th Gen Xeon XCC Performance
When it comes to performance, we are going to focus mostly on the three SKUs that we are testing in the exact same system and configuration. The goal of this was really to look at the generational performance increase between the 4th and 5th gen top-end U SKUs.
SPEC CPU2017 Estimated Results
SPEC CPU2017 is perhaps the most widely known and used benchmark in server RFPs. We do our own SPEC CPU2017 testing, and our results are usually a few percentage points lower than what OEMs submit as official results. Since the Intel Xeon Platinum 8458P seems to only have officially submitted 2P results, we are using our test runs for this, not official scores, thus “estimated.” We will simply note that for the Gold 6414U and Platinum 8558U, our figures aligned with published results, so our assumption is that if the Platinum 8458P had an official 1P result, it would be similar to what we saw.
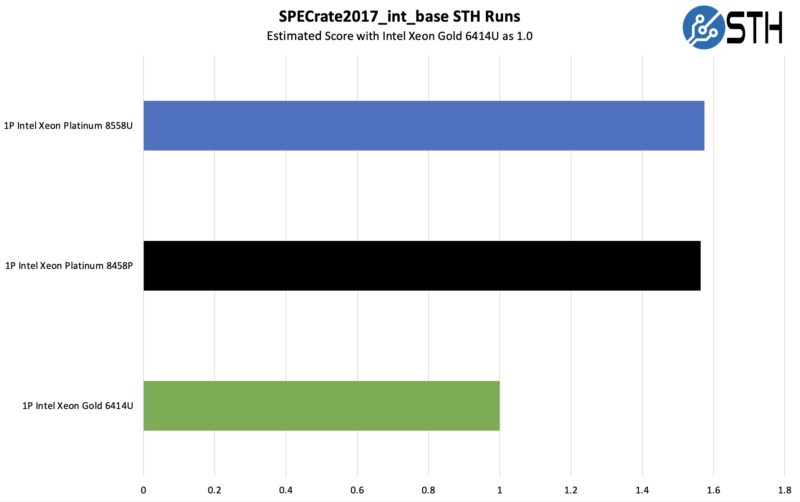
First, we are going to show the most commonly used enterprise and cloud benchmark, SPEC CPU2017’s integer rate performance.
Here is the SPEC CPU2017’s floating point rate performance.
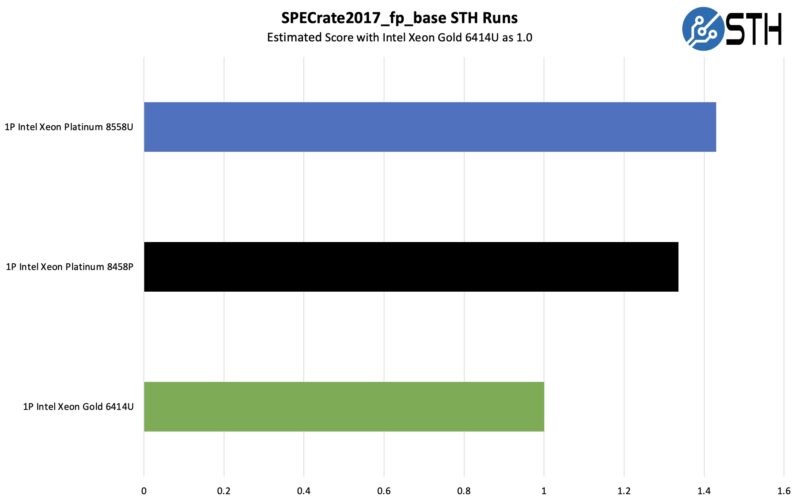
Overall, this is a very strong showing from the U series part. Having more cores is helping here, even to overcome a TDP deficit versus the Platinum 8458P. That is a very cool result.
STH nginx CDN Performance
On the nginx CDN test, we are using an old snapshot and access patterns from the STH website. We will note that we had to add back a high-speed NIC for this one since it is being tested over the network so it is not the full barebones configuration we used on the local tests.
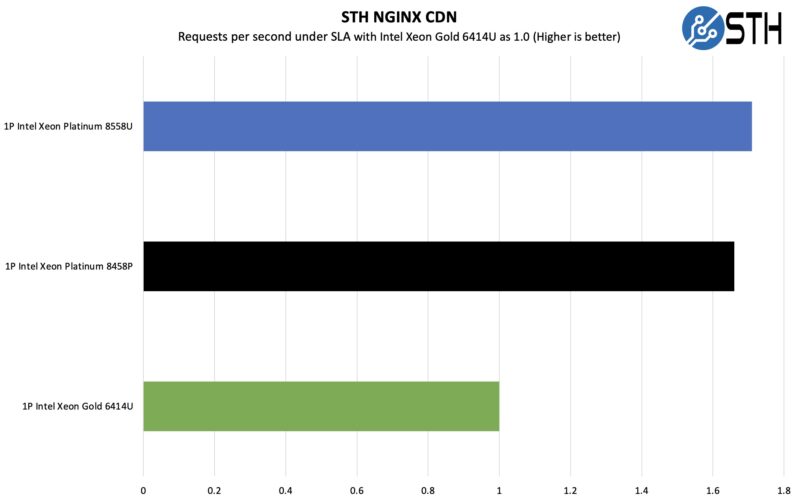
Again, lots of cores and cache are really helping the Intel Xeon Platinum 8558U here. Especially since one of the markets that single socket CPUs are targeted at is the web hosting market, this is a neat result.
GROMACS AVX-512
GROMACS is a popular molecular dynamics code. We just wanted to see what we got when we ran this on the three CPUs.
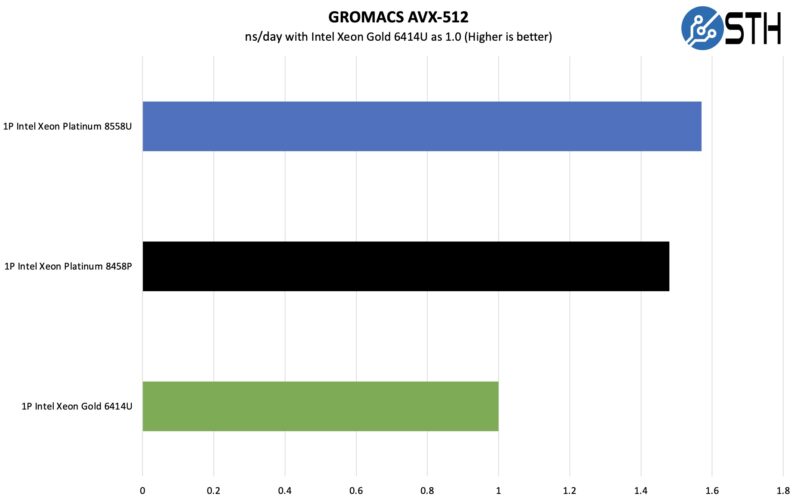
This one feels a bit more muted than the other results we have seen but still shows a solid uplift from the new generation of single-socket processors.
MariaDB Pricing Analytics
This is a very interesting one for me personally. The origin of this test is that we have a workload that runs deal management pricing analytics on a set of data that has been anonymized from a major data center OEM. The application effectively looks for pricing trends across product lines, regions, and channels to determine good deal/ bad deal guidance based on market trends to inform real-time BOM configurations. If this seems very specific, the big difference between this and something deployed at a major vendor is the data we are using. This is the kind of application that has moved to AI inference methodologies, but it is a great real-world example of something a business may run in the cloud.

Again, this is a really good result. Having more cores and more cache and the 4.0GHz burst turbo clock is helping a lot in this one.
Overall, the key takeaway should be that there was an enormous single-socket uplift in performance. At the same time, we wanted to see if the new CPUs were simply consuming more power to get this level of performance, so let us get to that next.



{kind=link}
It isn’t just the idle that’s big. It’s also that you’re getting much better performance per watt at the CPU and server
In isolation this finding is marginally interesting but if you could add a comparison of performance/watt to future system tests and have a larger dataset to compare between AMD and Intel this becomes much more useful. Most systems in the wild have average loads between 20 and 40% so having idle, baseline, full load data would be very interesting.
Anecdotally I’m seeing lower idle and full load power consumption with Bergamo systems that are not stripped down (~115W/350W)
“Intel tends not to market these heavily as AMD does”
Since AMD “server” CPUs are only 1 or 2 sockets – a single socket it most of AMD’s business. And with the boneheaded way they connect 2 CPUs (64 PCIe lanes PER CPU) – with a single socket you get 128 PCIe lanes – with dual socket you get ..wait for it.. 128 PCIe lanes.
“In isolation, this finding is marginally interesting but if you could add a comparison of performance/watt to future system tests and have a larger dataset to compare between AMD and Intel this becomes much more useful.”
LOL. how about the ability to feed cores? AMD is terribad at that. But it is just a desktop CPU masquerading as a server CPU. There is a reason AMD has little to no exposure in the data center outside of AWS type systems (where Intel still outnumbers AMD 10:1)…
My current setup is all SPR – I did buy another storage server and am running EMR on that server – not sure there is enough of an uplift to replace ~40 or so SPR CPUs in the storage system/SAN.
“Most systems in the wild have average loads between 20 and 40%”
No. Pre virtualization, yes – now No. Maybe AMD can only get 20-40% due to the lack of ability to feed cores, poor memory subsystems and all those “extra” cores that do next to nothing. That which cannot eat cannot perform.
More interested in Granite Rapids than upgrading nearly new servers. PCIe5 is a major limitation at this point – and with PCIe6 being short term and with PCIe7 likely to be the next longer term (unlike PCIe4 which was a single-gen) bus – can’t come soon enough.
@Truth+Teller:
Emerald Rapids is limited to 1S or 2S. There are only 5 SKUs of Sapphire Rapids that are capable of 8S operation. If this was so important why did Intel remove it from EMR?
You’ve got it backwards: AMD’s desktop CPUs have server cores masquerading as desktop ones, and it was always the case for Zen. Intel’s P-cores are server cores as well, just without additional cache and AVX-512/AMX units.
I’m not sure where you got the AMD’s weak memory subsystem from when it outperforms Intel designs. How can Intel’s 8-channel design beat EPYC’s 12-channels? Not to mention that Intel still segregates memory speed by SKUs – SPR goes from 4000MT/s to 4800MT/s while every AMD SP5 CPU has the same speed – 4800MT/s. EMR brings the max to 5600, but it is still segmented. Even at that increased speed it still falls short in raw bandwidth.
Thanks for the article. Well done. Its good to hear that Intel is still producing advanced chips and staying in the hunt with AMD and the other Chip OEMs.
@Truth+Teller:
“Since AMD “server” CPUs are only 1 or 2 sockets – a single socket it most of AMD’s business. And with the boneheaded way they connect 2 CPUs (64 PCIe lanes PER CPU) – with a single socket you get 128 PCIe lanes – with dual socket you get ..wait for it.. 128 PCIe lanes.”
In a dual socket you can get up to 160 PCIe lanes with AMD. This is done by only using 3 connections between CPUs instead of 4. Multiple server companies allow this setup option. Oh and this has been an option since at least Milan.
“No. Pre virtualization, yes – now No. Maybe AMD can only get 20-40% due to the lack of ability to feed cores, poor memory subsystems and all those “extra” cores that do next to nothing. That which cannot eat cannot perform.”
This is just pure lies on your side. Even in a virtualized environment you won’t see overall usage much about 40-50% most of the time. You cannot have a cluster running at 100% across all servers all the time. If a server were to go down you don’t have the required at minimum N+1 to run everything. That will mean some VM or most VMs will crash.
“More interested in Granite Rapids than upgrading nearly new servers. PCIe5 is a major limitation at this point – and with PCIe6 being short term and with PCIe7 likely to be the next longer term (unlike PCIe4 which was a single-gen) bus – can’t come soon enough.”
How is PCIe 5 a major limitation right now? PCIe 5 was released in 2019 and not implemented until 2022. PCIe 6 specification wasn’t released until January 2022. As is normal the PCIe generation on servers is from a few years before that. It takes time to validate these new generations on the server hardware. Not to mention that CPUs being released now were beginning their designs back in 2020, you know when PCIe 6 wasn’t an official spec. We will probably get PCIe 6 in 2026 and PCIe 7 isn’t expected to be released until 2025 so look to 2028/29 for server CPUs running that. Overall a PCIe generation will run probably about 3-4 years now for a while.
“In a dual socket you can get up to 160 PCIe lanes with AMD. This is done by only using 3 connections between CPUs instead of 4.”
A couple extra PCIe lanes in exchange for crippling inter-socket bandwidth! Now that’s a patently AMD solution if I’ve ever heard one.
“A couple extra PCIe lanes in exchange for crippling inter-socket bandwidth! Now that’s a patently AMD solution if I’ve ever heard one.”
That isn’t true at all. A Milan (3rd Gen) based Epyc with 96 lanes of inter-socket bandwidth has 50% more inter-socket bandwidth than Naples (1st Gen) based Epyc. A Genoa (4th Gen) with 96 lanes has 50% more inter-socket bandwidth than Milan with all 128 lanes.
TruthTeller sounds like an Intel shill.
@Enrique Polazo, don’t forget his alter ego, GoofyGamer either! Also looking forward to follow-up posts from TinyTom, PerfectProphet and AllofyouareAmdumbs.
AI is where these CPUs shine. A100 80GB still go for 16k+ on ebay. Instead you can grab 2×8592 and a future proof amount of DDR5 and get probably 1/3~1/2 the tokens/s. Hopefully Granite Rapids could bring parity.
Yes you can divide the weights onto multiple GPUs and do pipeline parallelism to achieve good utilization. But when you start to go beyond transformers, into transformer-CNN hybrids or something very different, the software is not there.