
Over the past few weeks, we have been working on refreshing some old low-power racks in one of our colocation facilities. The lower power per rack means that to hit minimum cluster sizes, we can no longer utilize the highest-power CPUs. That is why we have our Cloud Native Efficient Computing is the Way in 2024 and Beyond series. We wanted to check out the 5th Gen Intel Xeon “Emerald Rapids” single socket offerings as part of this deployment. When we did, we were quite surprised at the generational power and performance gains to the point that it caused us to go down the rabbit hole of crafting a tuned test bed to double-check our results. The big XCC packages got a lot better with Emerald Rapids. This will impact folks, from those looking to deploy lower-density racks like us today to those looking for lab nodes in the future. Let us get to it.
5th Gen Intel Xeon Single Socket Video Version
As you might imagine, we also have a video version of this article. In the video, we got to go into showing the system a bit more. Here is a link:
Of course, we suggest opening the video in its own browser, tab, or app for the best viewing experience. You can even put it up on your TV if you want.
Before we get too far, we do want to point out that we approached Intel about this idea we had for looking at the single socket options. Intel tends not to market these heavily as AMD does, and so we thought it would be useful to look at. Intel agreed and sent us the two highest-end U-series parts from the 4th Generation and 5th Generation Intel Xeon series. We must disclose that it is, therefore, being sponsored by Intel, but they did not see the article or video before publication. We needed help getting the CPUs to try out, and the hypothesis was that the 5th Gen 1P/UP parts would be better, but nobody had a great way to quantify this. For the record, these are not the highest-performance parts you can put in single-socket servers. We know that Intel has faster SKUs. SPEC CPU2017 will show the AMD EPYC Bergamo parts with 128 cores being faster. The goal was really looking at a generational comparison.

With that, let us take a look at the three CPUs (one we had access to already) we are going to use to test these CPUs.
The 5th Gen Intel Xeon XCC Change
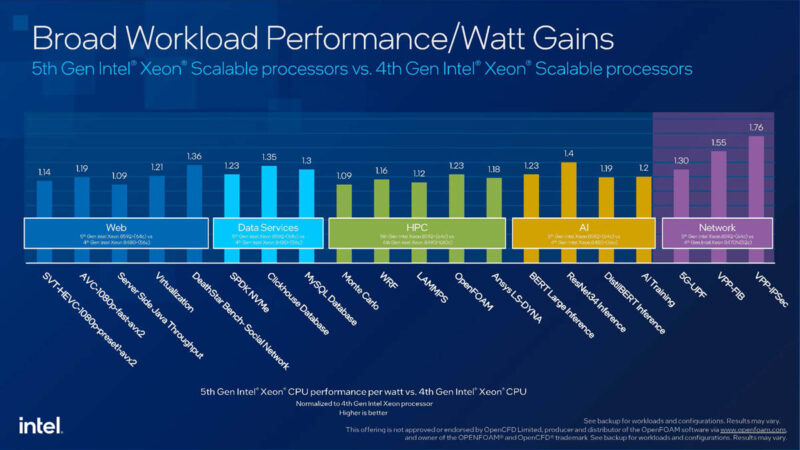
When we looked at the 5th Gen Intel Xeon Processors codenamed “Emerald Rapids” when it was initially released, Intel made a big deal about the power efficiency versus Sapphire Rapids. Keep in mind that both the 4th Gen and 5th Gen Xeon processors were launched in 2024. Both use the same sockets and have similar I/O.

While we got the typical performance per watt slides, something in the above slide around idle power and SoC interconnect power went largely unnoticed.
To understand what is going on here, we need to get into the packaging a bit. With lower core count parts (up to some 32 core SKUs) the Intel MCC die is used for mainstream servers. That is a monolithic die with all of the cores on a single piece of silicon making manufacturing easier. At the higher end, Intel uses multiple compute tiles with fast EMIB bridges between them.

We were trying to make a diagram of this, then we remembered this slide. One can see the four compute tiles for the 4th Gen XCC die with EMIB bridges between them. There is also a diagram of the two 5th Gen Intel Xeon tiles that make up a XCC die with EMIB bridges between them.

At the launch, Intel told us that the cores were effectively the same between the two parts. The newer 5th Gen XCC parts would have more cache, and, importantly the design was lower power at idle than the 4th Gen 4-tile design. Here is an example of the 5th Gen Xeon XCC compute tile in the event that you want to see what one of the tiles looks like.

That was one of the aspects that we wanted to get into. The other was the performance. Intel made a big move by increasing the maximum core count of the UP parts from 32 cores with the Intel Xeon Gold 6414U to 48 cores with the Intel Xeon Platinum 8558U. Note, here U means Uni-Processor, so these are single-socket-only CPUs without active UPI links. That is roughly analogous to the AMD EPYC “P” naming of single-socket-only parts. Intel also has a U suffix for its ultra-low-power mobile chips. It is the same letter, but a different meaning at Intel depending on if it is a data center or consumer part.

Since we had the Intel Xeon Platinum 8458P dual-socket 8×58 part, we decided to use that as another data point. That gave us a 32-core 250W and a 44-core 350W part from the 4th Gen, and a 48-core 300W part from the 5th Gen. That 5th Gen Xeon also has 260MB of L3 cache, a whopping 200MB more than the previous top-of-the-UP-line Gold 6414U. Adding 50% more cores, 20% more TDP, and over 3.3x the cache is certainly a way to get more performance, but the question was, did the new XCC design make a difference other than adding cache. It did.
Let us next get to performance.



{kind=link}
It isn’t just the idle that’s big. It’s also that you’re getting much better performance per watt at the CPU and server
In isolation this finding is marginally interesting but if you could add a comparison of performance/watt to future system tests and have a larger dataset to compare between AMD and Intel this becomes much more useful. Most systems in the wild have average loads between 20 and 40% so having idle, baseline, full load data would be very interesting.
Anecdotally I’m seeing lower idle and full load power consumption with Bergamo systems that are not stripped down (~115W/350W)
“Intel tends not to market these heavily as AMD does”
Since AMD “server” CPUs are only 1 or 2 sockets – a single socket it most of AMD’s business. And with the boneheaded way they connect 2 CPUs (64 PCIe lanes PER CPU) – with a single socket you get 128 PCIe lanes – with dual socket you get ..wait for it.. 128 PCIe lanes.
“In isolation, this finding is marginally interesting but if you could add a comparison of performance/watt to future system tests and have a larger dataset to compare between AMD and Intel this becomes much more useful.”
LOL. how about the ability to feed cores? AMD is terribad at that. But it is just a desktop CPU masquerading as a server CPU. There is a reason AMD has little to no exposure in the data center outside of AWS type systems (where Intel still outnumbers AMD 10:1)…
My current setup is all SPR – I did buy another storage server and am running EMR on that server – not sure there is enough of an uplift to replace ~40 or so SPR CPUs in the storage system/SAN.
“Most systems in the wild have average loads between 20 and 40%”
No. Pre virtualization, yes – now No. Maybe AMD can only get 20-40% due to the lack of ability to feed cores, poor memory subsystems and all those “extra” cores that do next to nothing. That which cannot eat cannot perform.
More interested in Granite Rapids than upgrading nearly new servers. PCIe5 is a major limitation at this point – and with PCIe6 being short term and with PCIe7 likely to be the next longer term (unlike PCIe4 which was a single-gen) bus – can’t come soon enough.
@Truth+Teller:
Emerald Rapids is limited to 1S or 2S. There are only 5 SKUs of Sapphire Rapids that are capable of 8S operation. If this was so important why did Intel remove it from EMR?
You’ve got it backwards: AMD’s desktop CPUs have server cores masquerading as desktop ones, and it was always the case for Zen. Intel’s P-cores are server cores as well, just without additional cache and AVX-512/AMX units.
I’m not sure where you got the AMD’s weak memory subsystem from when it outperforms Intel designs. How can Intel’s 8-channel design beat EPYC’s 12-channels? Not to mention that Intel still segregates memory speed by SKUs – SPR goes from 4000MT/s to 4800MT/s while every AMD SP5 CPU has the same speed – 4800MT/s. EMR brings the max to 5600, but it is still segmented. Even at that increased speed it still falls short in raw bandwidth.
Thanks for the article. Well done. Its good to hear that Intel is still producing advanced chips and staying in the hunt with AMD and the other Chip OEMs.
@Truth+Teller:
“Since AMD “server” CPUs are only 1 or 2 sockets – a single socket it most of AMD’s business. And with the boneheaded way they connect 2 CPUs (64 PCIe lanes PER CPU) – with a single socket you get 128 PCIe lanes – with dual socket you get ..wait for it.. 128 PCIe lanes.”
In a dual socket you can get up to 160 PCIe lanes with AMD. This is done by only using 3 connections between CPUs instead of 4. Multiple server companies allow this setup option. Oh and this has been an option since at least Milan.
“No. Pre virtualization, yes – now No. Maybe AMD can only get 20-40% due to the lack of ability to feed cores, poor memory subsystems and all those “extra” cores that do next to nothing. That which cannot eat cannot perform.”
This is just pure lies on your side. Even in a virtualized environment you won’t see overall usage much about 40-50% most of the time. You cannot have a cluster running at 100% across all servers all the time. If a server were to go down you don’t have the required at minimum N+1 to run everything. That will mean some VM or most VMs will crash.
“More interested in Granite Rapids than upgrading nearly new servers. PCIe5 is a major limitation at this point – and with PCIe6 being short term and with PCIe7 likely to be the next longer term (unlike PCIe4 which was a single-gen) bus – can’t come soon enough.”
How is PCIe 5 a major limitation right now? PCIe 5 was released in 2019 and not implemented until 2022. PCIe 6 specification wasn’t released until January 2022. As is normal the PCIe generation on servers is from a few years before that. It takes time to validate these new generations on the server hardware. Not to mention that CPUs being released now were beginning their designs back in 2020, you know when PCIe 6 wasn’t an official spec. We will probably get PCIe 6 in 2026 and PCIe 7 isn’t expected to be released until 2025 so look to 2028/29 for server CPUs running that. Overall a PCIe generation will run probably about 3-4 years now for a while.
“In a dual socket you can get up to 160 PCIe lanes with AMD. This is done by only using 3 connections between CPUs instead of 4.”
A couple extra PCIe lanes in exchange for crippling inter-socket bandwidth! Now that’s a patently AMD solution if I’ve ever heard one.
“A couple extra PCIe lanes in exchange for crippling inter-socket bandwidth! Now that’s a patently AMD solution if I’ve ever heard one.”
That isn’t true at all. A Milan (3rd Gen) based Epyc with 96 lanes of inter-socket bandwidth has 50% more inter-socket bandwidth than Naples (1st Gen) based Epyc. A Genoa (4th Gen) with 96 lanes has 50% more inter-socket bandwidth than Milan with all 128 lanes.
TruthTeller sounds like an Intel shill.
@Enrique Polazo, don’t forget his alter ego, GoofyGamer either! Also looking forward to follow-up posts from TinyTom, PerfectProphet and AllofyouareAmdumbs.
AI is where these CPUs shine. A100 80GB still go for 16k+ on ebay. Instead you can grab 2×8592 and a future proof amount of DDR5 and get probably 1/3~1/2 the tokens/s. Hopefully Granite Rapids could bring parity.
Yes you can divide the weights onto multiple GPUs and do pipeline parallelism to achieve good utilization. But when you start to go beyond transformers, into transformer-CNN hybrids or something very different, the software is not there.