
The posse finally got together to go after NVIDIA, and they need to. Many look at NVIDIA’s AI system’s dominance and think it is just because of the company’s GPUs or software. NVIDIA also has a host of technologies for scaling out workloads across many GPUs and systems. That includes its on-chip and on-package interconnect, NVLink for GPU-to-GPU communication in servers or pods, Infiniband for scaling beyond pods, and Ethernet to connect to the broader infrastructure. Now, the rest of the industry is trying to fight back with open standards to go after those segments. Last year, we saw Ultra Ethernet for using an enhanced Ethernet to provide an alternative to InfiniBand. This year, we are getting the Ultra Accelerator Link or UALink to target NVLink.
UALink will be the Open NVLink Competitor
First off, this call was put together by AMD, but it was also attended by folks from companies like Intel and Broadcom. As part of the promoter group, Cisco, Google, HPE, Meta, and Microsoft were also onboard.

The idea is that this is a memory semantic fabric that will scale to 1024 endpoints in its first spec. Assuming 8-way accelerator platforms this would be roughly equivalent to 128 of today’s UBB or HGX-size platforms. Realistically, it will scale from in boxes to a smaller number of accelerators than 1024 in most cases.

One of the big benefits to UALink is that it gives everyone else in the industry a chance to keep pace with NVIDIA. NVIDIA now has the scale to do things like make NVSwitch boxes and put those NVSwitch trays into things like the NVIDIA DGX GB200 NVL72. Intel is selling a few hundred million dollars of AI accelerators this year, which likely means it only sells in tens of thousands of accelerators. AMD will sell several billion dollars of MI300X this year, but that is still nowhere near NVIDIA’s AI scale. Having UALink allows a company, like Broadcom, to make UALink switches to help other companies scale up and then use those switches across accelerators from multiple companies. We already covered the Broadcom Atlas switches plans with AMD Infinity Fabric AFL Scale Up Competitor to NVIDIA NVLink Coming to Broadcom Switches in PCIe Gen7. We were told in the briefing that those might implement a V1.0 of UALink. Of course, the UALink V1.0 spec is not out yet.
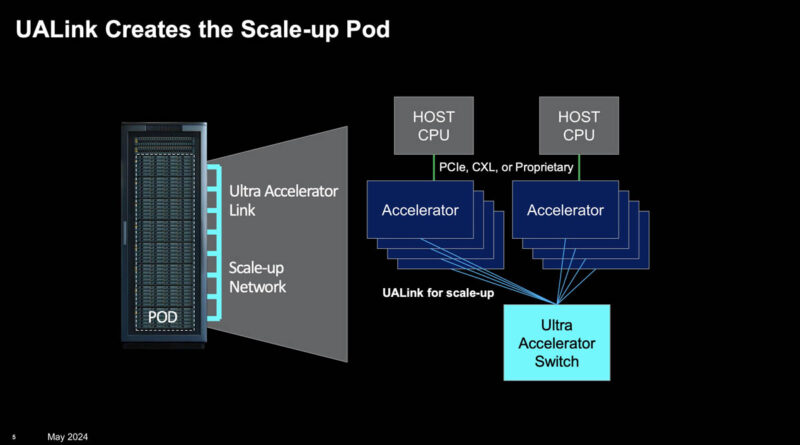
Ultra Ethernet will still be used to scale-out to more nodes. We covered that Broadcom will likely have an early Ultra Ethernet NIC out in its 800Gbps generation of Thor products, but that it might take one more generation to have full UEC support just based on where the spec standardization.

The new working group hopes to have a V1.0 quality spec in Q3 2024. Getting that many companies together quickly means that someone is likely contributing the bulk of a spec that it has already developed. Our guess is AMD here. There will then be a V1.1 spec targeted for Q4 2024. Our sense is that the V1.1 will end up being what considers the specific needs of additional companies.
Final Words
Today, a number of companies are trying to take standard PCIe switches and make a PCIe-based fabric to scale-up to more accelerators. It seems like the big players in the industry see that more as a stop-gap measure. Instead, NVIDIA’s NVLink is more of the gold standard in the industry for scale-up. Now the posse is out to release an open competitor to the proprietary NVLink.
All of this will take time. I asked at the briefing if this was a 2026-ish implementation target. 2024 is too early, and even if it is baked into a product, it is unlikely to be an early 2025 product at this point. If you look at CXL or UCIe it takes a long time for these standards to end up in products. 2026 would be a fast implementation.
For companies like AMD and Intel, this gives a path to replicate NVLink and NVSwitch functionality while sharing the development with others. A company like Broadcom is likely the big winner here as it is positioned to be the connectivity provider to non-NVIDIA systems, whether that is for scale-up or scale-out. Whether AMD or Intel win, Broadcom is selling the connectivity. For hyper-scalers, the ability to invest in standardized fabrics makes a lot of sense, no matter who is making the endpoints.
As an aside, it is not lost on me that in the 2019-2020 timeframe, we were thinking of CXL in-box and Gen-Z as the scale-up solution. Many of the folks who showed us Gen-Z back in the day now work at AMD almost like AMD has been building a team that saw and has been trying to solve the scale-up challenge for years.
Hopefully, we get to see UALink in action sooner rather than later.



{kind=link}
Hmmm one wonders if “The posse” can get UALink products into the marketplace before Nvidia extracts all the computing hardware profit from the AI bubble…It’s hard to compete with a company that is operating on all cylinders in the AI/GPU marketplace and last year added $1T to their market cap as a result.
(“cylinders”: Something cars had before EVs)
Why not use ethernet for scale-out (between nodes) and scale-up (i.e. connect GPUs inside a node)? I can see why PCIE is not used for scale-up but Ethernet switches at 51Tbps are ALOT faster than PCIE switches. It’s puzzling why develop UALink instead of just modify existing Ethernet to fit this purpose. That way they can leverage Ultra Ethernet efforts as well — which is used for scale-out.
Amit, inter-GPU link do not need many requirements that ethernet mandates, a lot simper without them. Also it does not need to wait 7.2Tbps ethernet is standardized
>> As an aside, it is not lost on me that in the 2019-2020 timeframe, we were thinking of CXL in-box and Gen-Z as the scale-up solution..
This is true. The poor gang of Intel and AMD, and the others, they been talking talking but no action.
Using low latency PCIE as a rack level fabric has been an obvious choice for 10+ years but due to various market dynamics programs were not invested in. Nvidia made the right AI bets and they have a 4-5 year advantage. Getting hardware interconnect chips right without breaking legacy software compatibility is quite challenging. Folks at PLX & IDT were best at it … hopefully they catch up and recover lost ground.
.
It still baffles me that market authorities allowed nVidia’s take-over of Mellanox. The result we see here with NVLink.
With today’s architectures, irrespective of protocol (Ethernet, IB etc.) you can either get a couple of hundred 100GB/s ports or tens of terabit ports on a single chip with around 100ns latencies, if you are lucky. Expanding from that base, latency is tripled when Mr Clos is brought in to help expand. Also, these very expensive switch chips still have congestion and interference issues in spite of all the proprietary telegraphy bells and whistles added.
Fix the switch problem and the remaining challenges fade into insignificance.
Don’t hold your breath. All this does is add another interface for each of these companies to support. And none of them have any reason to cooperate beyond fear of nV. This will get hust far enough to start to offer an advantage to one participant and then it will start to lose support.
Why are people no longer considering CXL as a method for scaling up?
Kevin – Future versions of CXL are only scaling to 4096 endpoints. Today’s AI clusters are already 100K+ GPUs.