Tyan Thunder HX FT83A-B7129 Power Consumption
In terms of power consumption, we have 4x 80Plus Platinum 1.6kW power supplies. We were able to use the higher wattage rating since we are using 208V data center power. One item that we hope Tyan looks into in the future is adding Titanium power supplies that are slightly more efficient. That slight efficiency gain is nice for larger systems like this.

In this system, we hit just under 3.5kW with two Intel Xeon Platinum 8380’s and eight NVIDIA A40 GPUs. That is quite a bit, but there is certainly room to increase that by adding higher-power NICs/ DPUs, adding more drives and other components to the system.
It is fairly clear that a system like this one needs to be on higher-power racks. Even a standard North American 208V 30A rack that has been used for years will likely only be able to handle one of these systems. Even in our configuration, we would be using around 35kW in 40U of space. That is a big reason we have been focusing on liquid cooling at STH.
STH Server Spider: Tyan Thunder HX FT83A-B7129
In the second half of 2018, we introduced the STH Server Spider as a quick reference to where a server system’s aptitude lies. Our goal is to start giving a quick visual depiction of the types of parameters that a server is targeted at.
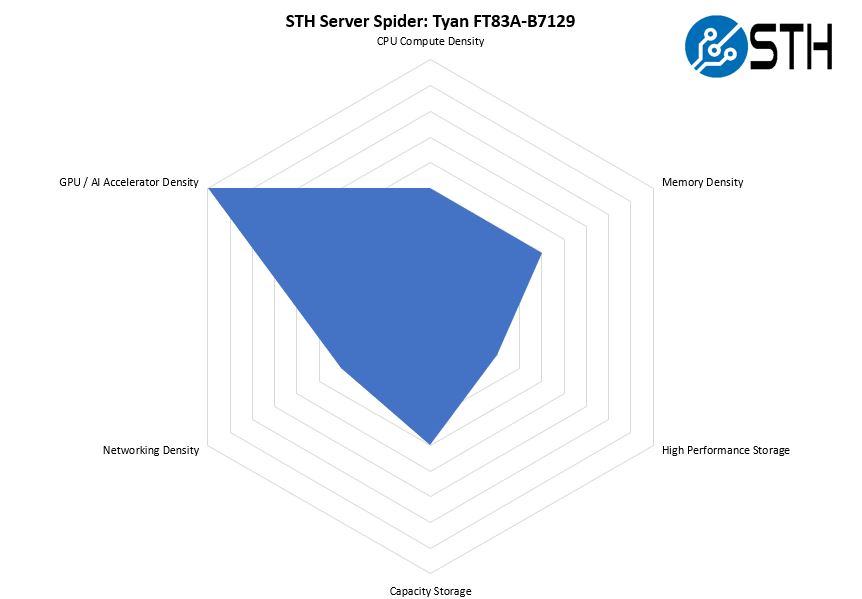
As a 10x GPU server, this is effectively the most GPUs one can put in a single 4U node today. Tyan also balances that extreme optimization around having many GPUs with having features like storage and networking as well. That is a benefit of the switched PCIe architecture.
The advantage for a system like this is simple. Having 25% more GPUs in a single server versus an 8x GPU system means that one needs fewer servers. That leads to cost savings since one needs fewer CPUs, DIMMs, NICs, chassis, drives, and so forth. While this may seem like extreme optimization, these systems are not inexpensive when configured (the NVIDIA A40’s we used each has a street price of around $6000 these days.) That optimization can lead to large cost savings.
Final Words
Overall, this is an awesome system. We have been reviewing systems like these for years, and they have certainly become more refined with each generation. We are going to quickly note that we rushed this review a bit. You will see on Tyan’s website that this server is listed as “Coming Soon”. This system is going to be a centerpiece at Tyan’s SC21 virtual exhibition so the company asked us to get this review done fast before sending the unit back.

Having the newer generation of processors also means that there are a lot fewer trade-offs over the previous generations of servers. Thinking back to the Xeon E5 era when we started reviewing these servers, the increased PCIe Gen4 capacity is a welcome change.

One nice aspect of systems like this is that they are flexible. One can use GPUs and other accelerators (AI or FPGAs as examples) and keep a common platform for accelerated computing. That is a big difference and why many still prefer these PCIe solutions over SXM/ OAM servers. Still, we are reaching the limits of what these systems can practically cool so one has to wonder if the market will start shifting more towards OAM in future generations.

Overall, this system worked well for us. After many memories of rough early GPU compute servers, this certainly feels like it is a better solution. In this article, hopefully, you learned a bit about what those generational enhancements are.



{kind=link}
So many GPU servers latley
Is multi root host supported on this platform? That is a huge and flexible feature of leveraging both the Broadcom PCIe switches and cabling those to the motherboard: each of the PCIe switches can be configured to link to each of the CPU sockets. If the motherboard and GPU platforms support this multi-host topology it will cut out a hop between the CPU sockets to access memory as each card can then go directly to the appropriate socket and normalize memory access latency. Very helpful for some applications. The downside is that per socket socket PCIe bandwidth is halved. As a flexible solution using PCIe switches and cables, this is configurable to optimizes for your use-case.
There is also the obvious options of being able to swap the CPU board with AMD Epyc while re-using the GPU IO board. Good engineering on Tyan’s part. While tied to PCIe 4.0 due to the switches, it would permit rapid deployment of dual socket Intel Sapphire Rapids and AMD Genoa platforms next year with the need to only replace part of the motherboard.
It’d be nice to see a few more options in the front for those two 16x PCIe 4.0 slots. In this system it is clear that they’re targeted for HBA/RAID controller cards but I feel they’d be better off as some OPC 3.0 NIC cards or dedicated to some NVMe drive bay. Everything being cabled does provide tons of options though.
I do think it is a bit of a short coming that there is no onboard networking besides the IPMI port. Granted anyone with this server would likely opt for some higher speed networking (100 Gbit Ethernet etc.) but having a tried and true pair of 1 Gbit ports for tasks like cluster management that is OS application level accessible is nice. Being able to PEX boot without the hassle of going through a 3rd party NIC are advantageous. Granted it is possible to boot the system through the IPMI interface using a remotely mounted drive but that is a scheme that doesn’t lend itself well to automation from my prior experience.
Can we please put an end to junky drive trays. There has to be a better option.
Want to buy!
Please email me for further details.