Tyan Thunder HX FT83A-B7129 Management
The Tyan web management interface uses the newer MegaRAC SP-X solution as a base. This is becoming the industry standard management solution that many vendors are adopting and adapting for their platforms. We have gone over this a number of times, so here is a look at the Tyan management system.

Tyan’s version has a number of customizations. One item that we surprisingly liked was the simple dashboard. Many vendors use overly complex dashboards with many status indicators but the performance of the dashboard is much worse in those implementations. Tyan’s implementation is relatively fast among SP-X implementations we have used.
One can see features such as sensor readings with temperatures, voltages, fan speeds, power consumption, and other metrics. These sensor readings are displayed on the web interface but are really designed to be consumed by data center monitoring and management packages.
Changing various settings is relatively straightforward. The new HTML5 interface is even easy to navigate on phones and tablets. This is an enormous ease-of-use upgrade versus the last time we looked at the interface in our 2011-era Tyan IPMI 2.0 Remote Management WebGUI Tour.
Remote iKVM features are included with this solution. That is something that vendors such as Dell EMC, HPE, and Lenovo offer at an additional cost on their servers. Tyan still offers the Java iKVM but now has a HTML5 version in their solution. The HTML5 version we tested does not have remote image mounting enabled, but not all vendors (e.g. Supermicro) have that feature parity on their new HTML5 iKVM suites.
Based on comments in our previous articles, many of our readers have not used a Tyan server and therefore have not seen the management interface. We have a 7-minute video clicking through the interface and doing a quick tour of the Tyan management interface:
It is certainly not the most entertaining subject, however, if you are considering these systems, you may want to know what the web management interface is on each machine and that tour can be helpful.
Tyan Thunder HX FT83A-B7129 Performance
In terms of performance, we were focused on how well the system was able to perform under load. In these GPU systems, there are two main areas to look at. First, whether the CPUs can be cooled to their rated level. Second the GPUs.
Looking first to the CPUs, we are utilizing the Intel Xeon Platinum 8380 to represent the high-end 270W TDP CPU that Tyan says the system is capable of handling. We also had a 32-core option just to provide some variation.
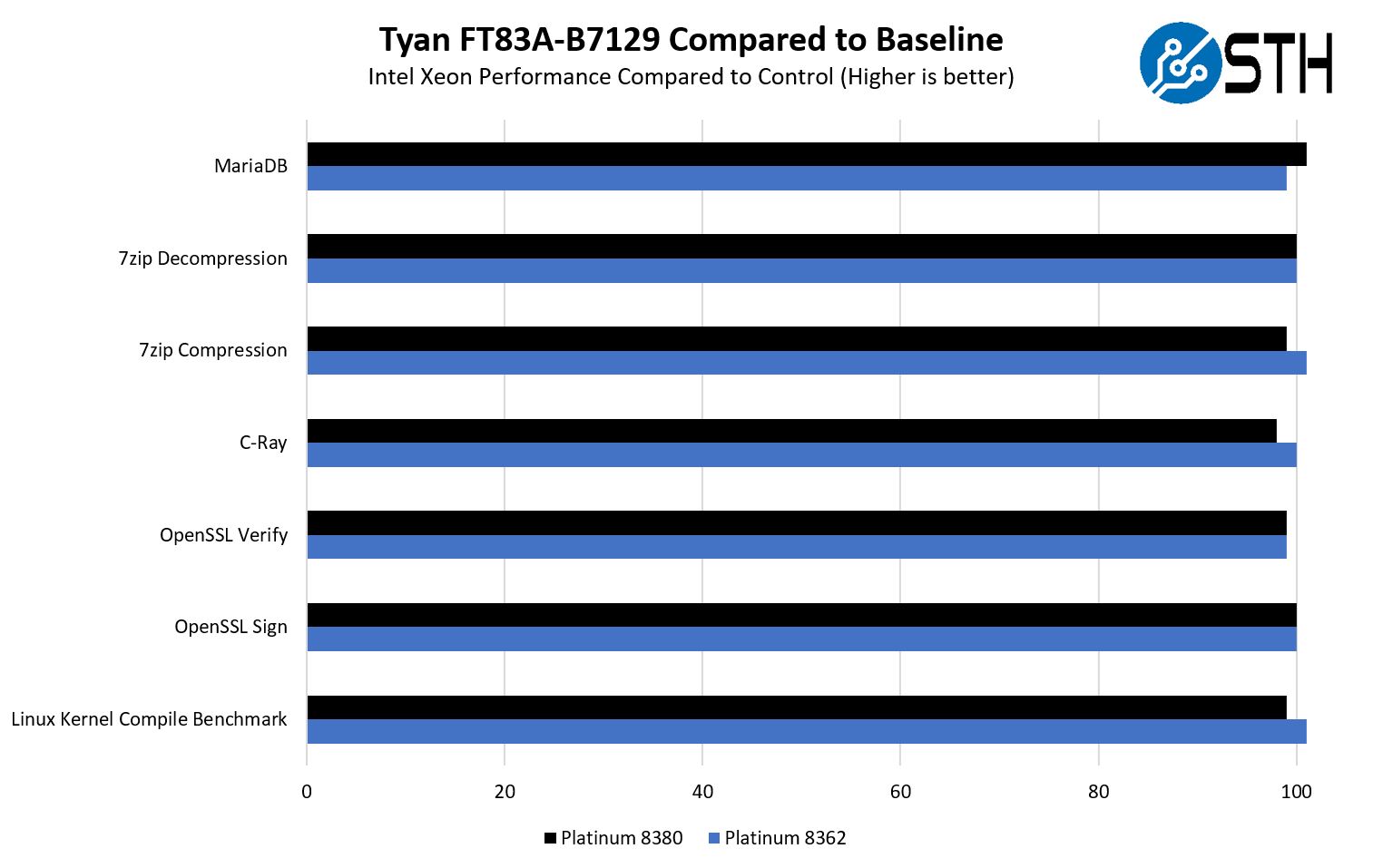
Here we saw performance that was roughly half a percent below our standard 2U test systems. This is still well within a test variation and it seems like Tyan’s metal shroud cooling solution is indeed able to power high-end CPUs.
On the GPU side, we were a bit limited. We did not have 10x 300W GPUs like the NVIDIA A100 80GB PCIe or A40’s. So we were left using 8x NVIDIA A40 GPUs.
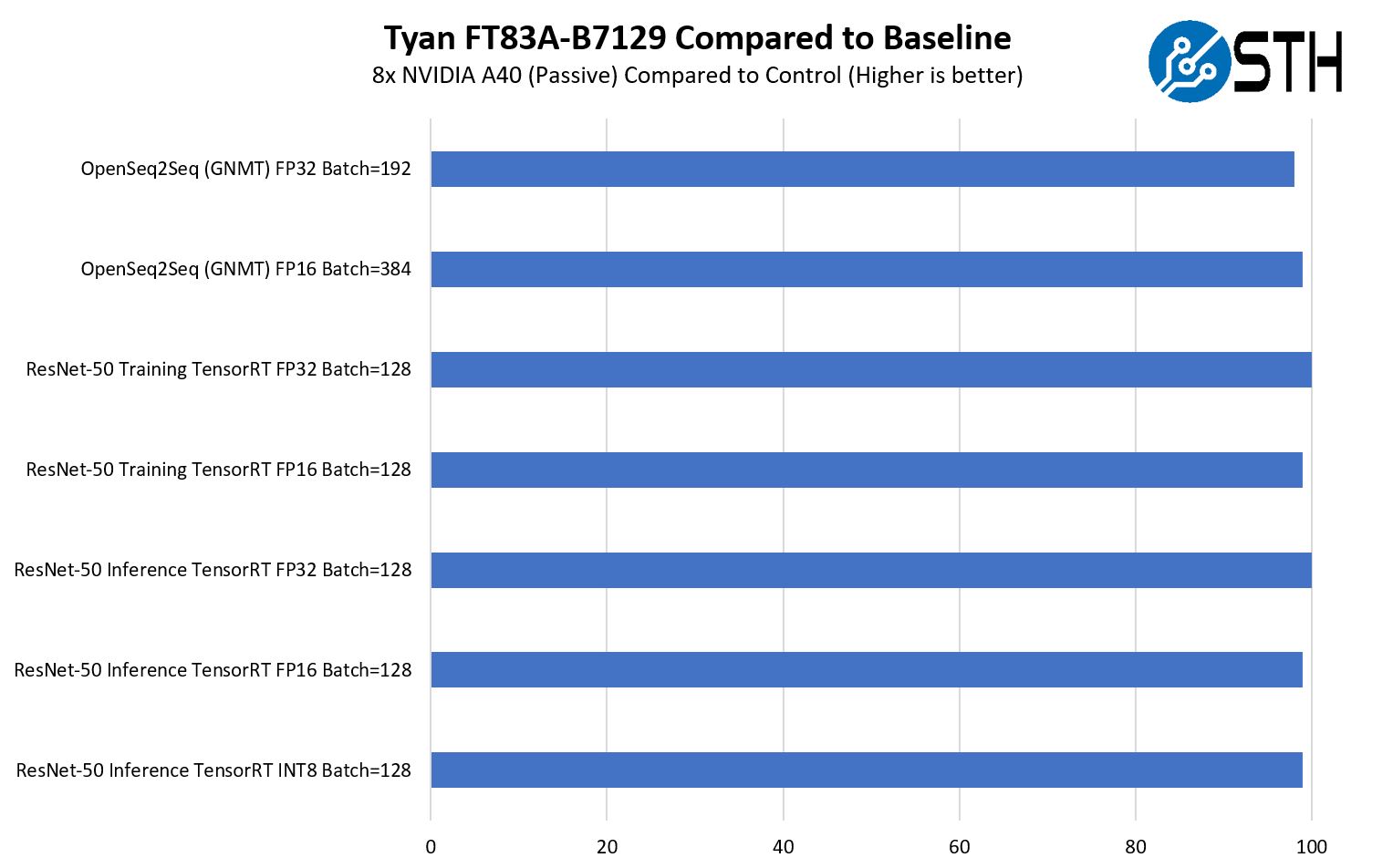
We wanted to quickly note here that the GPUs were cooled relatively well, but we still saw closer to a 1.2% variance. Usually, we use 1%-1.5% as a normal test variance so this was at the higher end of the range. It was also not something like 5-10% that would have us concerned. We also had to block portions of the chassis for the 8x GPU configuration so it may be (and in this class of systems often is) the case where airflow is optimized for 10x GPU configurations. We just did not have a set of 10x GPUs because GPUs are hard to get these days.
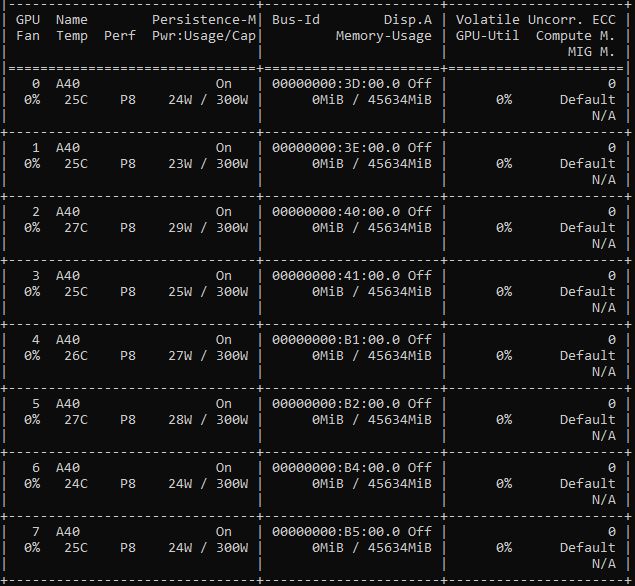
In terms of topology, we can see the PCIe switch topology in full action here. Both sets of four GPUs are connected via a switch. The main benefit here is that the GPUs can sync over the PCIe switch and not have to go back through the CPU complex.
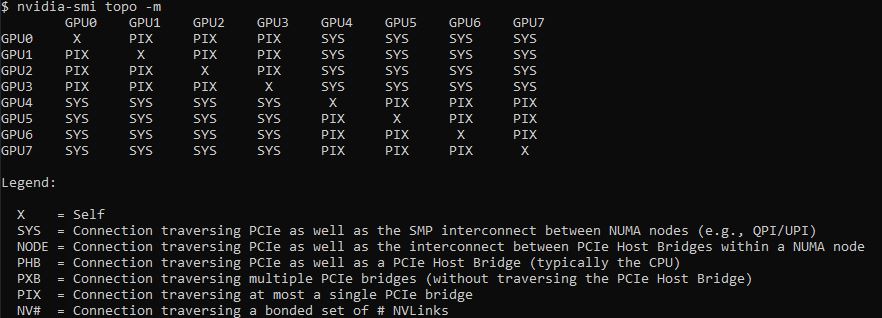
Software has gotten better over the years so we tend to see this dual-root system instead of single-root systems these days. Still, Tyan needed to use PCIe switches here to enable PCIe connectivity to the rest of the system. 11x PCIe x16 devices on the GPU/ accelerator board alone is 176 lanes, and that is without the OCP NIC, the front PCIe slots, or NVMe drives. The 3rd generation Intel Xeon Scalable only has 128x PCIe lanes so it is necessary to use a switched architecture. Since switches have been used for so long, software is usually optimized for these configuraitons.
Next, let us get to power before the STH Server Spider and our final words.



{kind=link}
So many GPU servers latley
Is multi root host supported on this platform? That is a huge and flexible feature of leveraging both the Broadcom PCIe switches and cabling those to the motherboard: each of the PCIe switches can be configured to link to each of the CPU sockets. If the motherboard and GPU platforms support this multi-host topology it will cut out a hop between the CPU sockets to access memory as each card can then go directly to the appropriate socket and normalize memory access latency. Very helpful for some applications. The downside is that per socket socket PCIe bandwidth is halved. As a flexible solution using PCIe switches and cables, this is configurable to optimizes for your use-case.
There is also the obvious options of being able to swap the CPU board with AMD Epyc while re-using the GPU IO board. Good engineering on Tyan’s part. While tied to PCIe 4.0 due to the switches, it would permit rapid deployment of dual socket Intel Sapphire Rapids and AMD Genoa platforms next year with the need to only replace part of the motherboard.
It’d be nice to see a few more options in the front for those two 16x PCIe 4.0 slots. In this system it is clear that they’re targeted for HBA/RAID controller cards but I feel they’d be better off as some OPC 3.0 NIC cards or dedicated to some NVMe drive bay. Everything being cabled does provide tons of options though.
I do think it is a bit of a short coming that there is no onboard networking besides the IPMI port. Granted anyone with this server would likely opt for some higher speed networking (100 Gbit Ethernet etc.) but having a tried and true pair of 1 Gbit ports for tasks like cluster management that is OS application level accessible is nice. Being able to PEX boot without the hassle of going through a 3rd party NIC are advantageous. Granted it is possible to boot the system through the IPMI interface using a remotely mounted drive but that is a scheme that doesn’t lend itself well to automation from my prior experience.
Can we please put an end to junky drive trays. There has to be a better option.
Want to buy!
Please email me for further details.