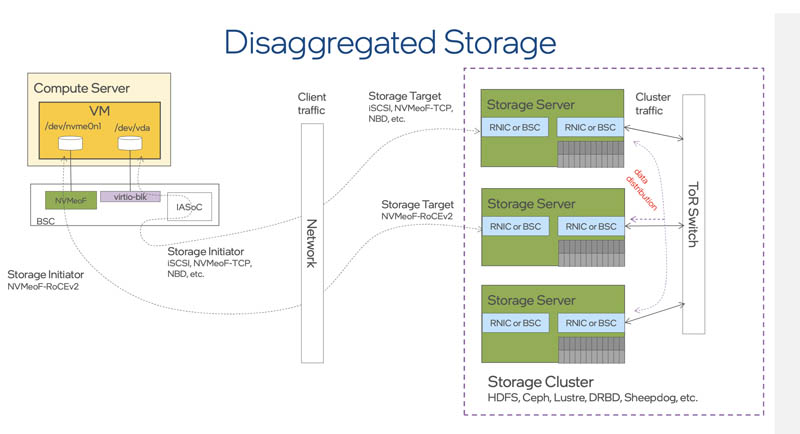
NVMeoF Using the Intel IPU
Using the BSC IPU for NVMeoF using RDMA acceleration the first step was to start VirtIO and initialize the card. We used a script to automate this process that took only a few seconds, but this section is best viewed in the video under the heading “Setting up the Intel IPU”. We had the IPU installed in the rack of 2U Supermicro Ultra servers that were serving as both the IPU host as well as the NVMeoF target systems.

For storage, we had 1.6TB Intel P4610 SSDs (now Solidigm?) installed, and a total of eight in the target system.

With a FPGA you can change your data path by adding new functionality so there is a step where you need to program the FPGA and get it ready. Luckily, we can do this directly from the Intel Xeon D processor. That is the same processor that the infrastructure provider can use to manage the card.

Once that is done, we can then go to the host server, the terminals on the top of the screen, and start finding our SSDs. We go from no SSDs to six installed since that is how many we brought up on the Big Spring Canyon IPU. You will notice that to the host system here, these drives look exactly like the drives on the target server. The host server thinks it has standard NVMe devices and does not know that they are being delivered over the 100GbE fabric using NVMeoF and the IPU.
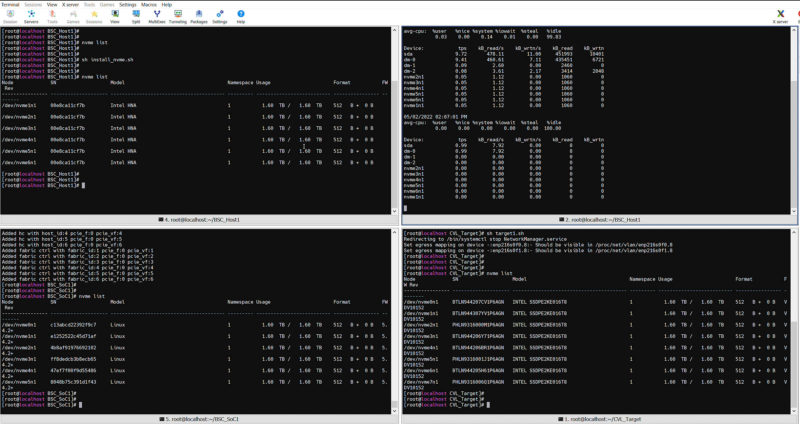
You may need to click this one to see it in more detail. The target server is on the top two terminals with six drives connected through the IPU on top with iostat showing on the right. The bottom left is the IPU’s Xeon D-1612. The right is the host server that has the physical 8x Intel P4610 1.6TB NVMe SSDs. All of this works because the IPU’s Stratix 10 FPGA is connecting to the target and presenting the NVMeoF drives to the host as standard NVMe block devices.
Now that we have those drives installed on our system, the next question is in terms of performance.
Intel IPU NVMeoF Performance
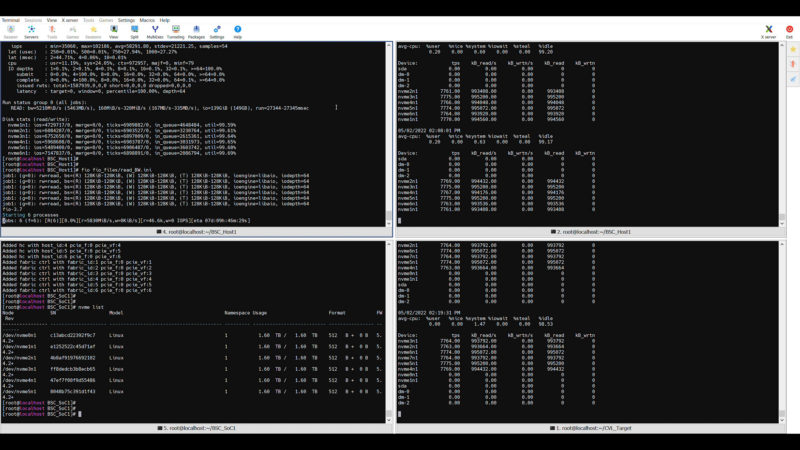
For these, again the orientation is the host system has the top two terminals. The left will be the fio test the right is the iostat monitor. The bottom left is the Xeon D on the IPU card. The bottom right is the iostat on the target. Also since there is so much going on in each screenshot, you may want to click through for more detail in larger versions.
First, we are going to run a 4K Random read script and you will see we are in the 1.2M to 1.4M 4K random read IOPS range. You can also see the iostat figures on both the host and target to the right.
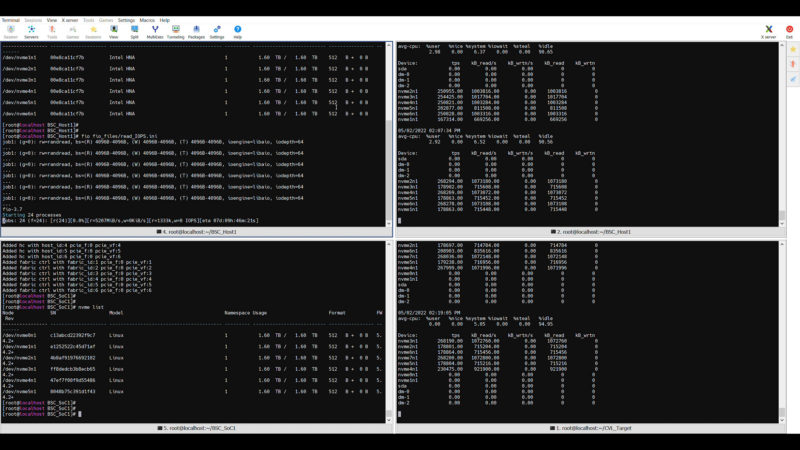
We can also run a sequential read test and you can see that we are getting in that 5.5-6GB/s range. This is not delivering the full performance of each NVMe device, but it is approaching 8Gbps per device.
In terms of write IOPS we are in the 1.3-1.4M range just like we were previously getting on the read side. This is huge IOPS for Ethernet solutions.
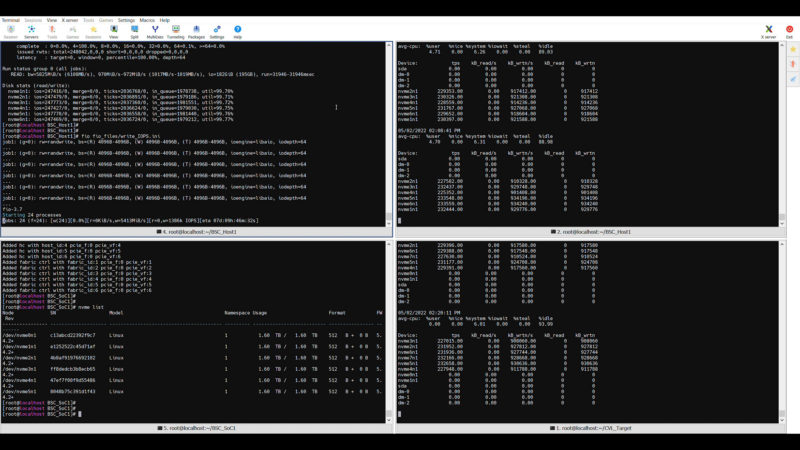
And sequential writes in the 5.5-6GB/s range again.

Taking a quick note also on the iostats, the CPU utilization was still super low in the <3% range for sequential and ~10% range for the random, but also remember we are running fio from the target node so that includes the fio traffic generation.
One item to remember here is that we also have Ethernet and NVMeoF overheads. Solutions like these are often tuned for high IOPS rather than the highest sequential bandwidth, so the ~1.2M to ~1.4M 4K random numbers are the big ones here.
Overall, this was solid performance. Not too long ago, it was a big deal when a 24x SATA SSD system could locally hit 1M 4K random read IOPS. This is more and over a network.
Intel IPU Impact
This particular IPU Intel already has large customers, and it is fairly easy to understand why. We are showing just the basic NVMe demo, but there is more FPGA logic area available to add more services beyond what we are showing in this demo. Perhaps one way to look at this is that for a cloud provider, one can add one of these IPUs and skip having local NVMe storage as well as a high-speed NIC.

This storage is important. In a cloud platform, local NVMe storage can be fast, but there is a high probability of stranding unused flash in a node. Using a solution like this, storage can be delivered transparently to bare metal or virtualized hosts. That allows the infrastructure provider to dynamically allocate storage to each client from centralized pools without having to expose the infrastructure’s inner workings to 3rd parties using the platform.
Beyond what we are showing here, the FPGAs can also be used to do things like securing and reducing the data transferred by running encryption and compression in the data path. That helps secure data in transit as well as reduces how much data is transmitted further lowering network pressure.
Intel has other options such as using the card to offload OVS (open virtual switch) and more, but this storage example seems like an easy one to showcase how the IPU works.
Final Words
Overall, this is a really cool solution that clicked for me when I saw it in person. That is the reason I wanted to do this article and also do a video. It is one thing to say that there is a NIC or a FPGA NIC. It is another to get to see it running. While we have seen FPGA-based SmartNICs before, the Intel IPU has the Xeon D CPU that allows an infrastructure provider to manage the IPU as an infrastructure endpoint. It can then provide selective services through the FPGA. The full x86 system in this one is similar to what we are seeing in newer ASIC DPUs, but also much more powerful than what one has in FPGA-based SmartNICs.

Running a NVMeoF solution at 1.2-1.4M IOPS while simultaneously presenting the solution to the host system as just a NVMe block device is really interesting. The FPGA provides a lot of flexibility to present different types of devices to client systems and users. That same FPGA and the Xeon D control plane give the infrastructure provider an easier way to manage complex infrastructure and then present it to systems.
One thing is for sure, Intel has a roadmap for this type of solution out to 800Gbps generations and every vendor we talk to is discussing customer demand for DPUs and IPUs. This class of device is coming and will change networking, storage, and how infrastructure is provisioned going forward. That is exactly what makes it an exciting technology.

Also, as a quick aside, this one took an extraordinary effort by folks at Intel to even get me into the lab to get to show this. That included even clearing a special bench to use and erecting a small wall behind the demo so this could be filmed without showing off other items in the lab. I just wanted to say thank you for all of those efforts. Hopefully, this will help many STH readers understand the IPU.



{kind=link}
At 22W for the Xeon D-1612 this seems quite a bit more power hungry than the ARM equivalents, any thoughts on that?
Also as this CPU doesn’t support PCIe3.0 it would be interesting to read what the capacity limits are for this DPU, from the face of it it looks like a more power hungry, less performance solution.
Also there’s a likely error in the article stating it has 4 cores 16 threads which should be 8 threads
Has Intel commented on their strategy for encouraging development for the FPGAs?
They are undoubtedly more versatile; but more costly and power hungry than fixed-function equivalents; and writing FPGA implementations, especially good ones, is not baby’s first software project; so this offering seems like it could end up being squeezed between hyperscalers who just revise their fixed-function chips periodically, as events warrant, because they operate so many that the savings cover the engineering costs; while smaller customers will find the flexibility of FPGAs mostly theoretical unless they have access to someone else’s development expertise.
Is Intel the one planning on building and offering a variety of accellerated functions? Are they going to offer a basic library and some sort of 3rd party development program open to very-fabless semicoductor designers who will sell their features and capabilities? A more tightly curated 3rd party program focusing on partnerships with specific interested parties(like hypervisor vendors and makers of various network-disaggregated storage and other peripherals; or high speed packet inspection and modification?
It’s certainly a neat looking part; but the FPGA just seems like something that really needs a software strategy behind it in order to realize its potential.
Sponsored or not, this is a very interesting article! Thanks Patrick!
I don’t know. Sometimes I think STH sponsored is better than other sites non-spons. I’d say this is the best content Intel has for it’s IPUs anywhere that’s public. Maybe it’s also because we’ve seen STH use other tech too. It’s rare to get content like this. I can imagine how the convo on the article went.
Intel: “Hey we need you to have an article like Moore Insights.”
STH: “No. I want lstopo.”
@Kiko Lee: At a bare minimum STH sponsored is usually quite detailed; rather than just a thin press release regurgitation, which is always dreadfully disappointing.
At a lot of sites ‘sponsored’ basically means ‘you’d learn exactly as much just by checking PRNewswire’; rather than ‘we poke around as much as possible and add commentary on capabilities and market position and the like; even if we don’t have the opportunity to really get our hand dirty and do some aggressive benchmarking and such’.
That’s a massive virtue right there.
Patrick, thanks a lot for detailed article about Intel IPU!
Been working on BSC for a while, really good introduction!