Diving into the Mesh Interconnect Distributed CHA
The first stop on the mesh interconnect discussion is the Distributed Caching and Home Agent. One of the major performance bottlenecks in the Intel Xeon E5 V4 architecture was a limited number of QPI home agents. With Skylake-SP, each core gets its own UPI caching and home agents.
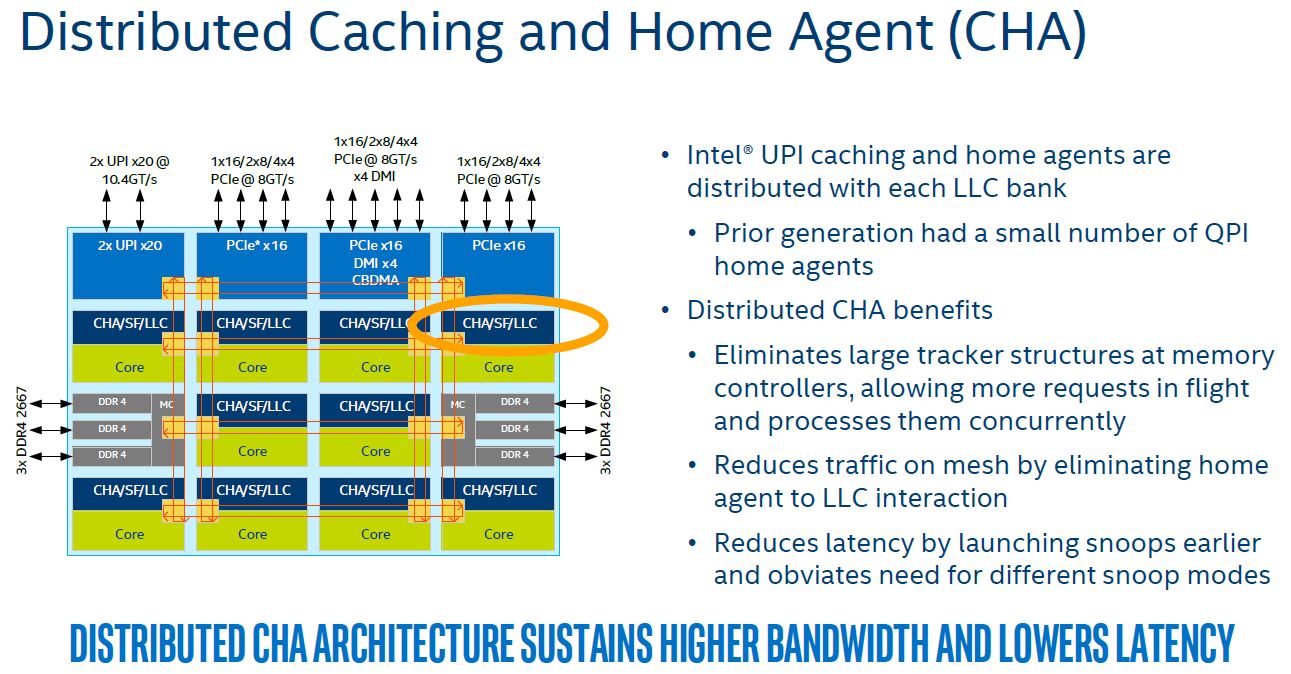
There are a few inter-socket tests where one will see performance figures that look out of line with the simple performance improvement based on the rest of the platform. The new distributed CHA is one of the reasons for this. Intel needed to move to this type of architecture because it is planning for even more cores not just the 28 we have today. Cascade Lake, the next generation, will undoubtedly have more cores so being able to manage mesh traffic will be important.
Intel Mesh Interconnect Memory Implications
Looking at the memory controllers, there are two per die like the Intel Xeon E5 versions. The similarities essentially end there.
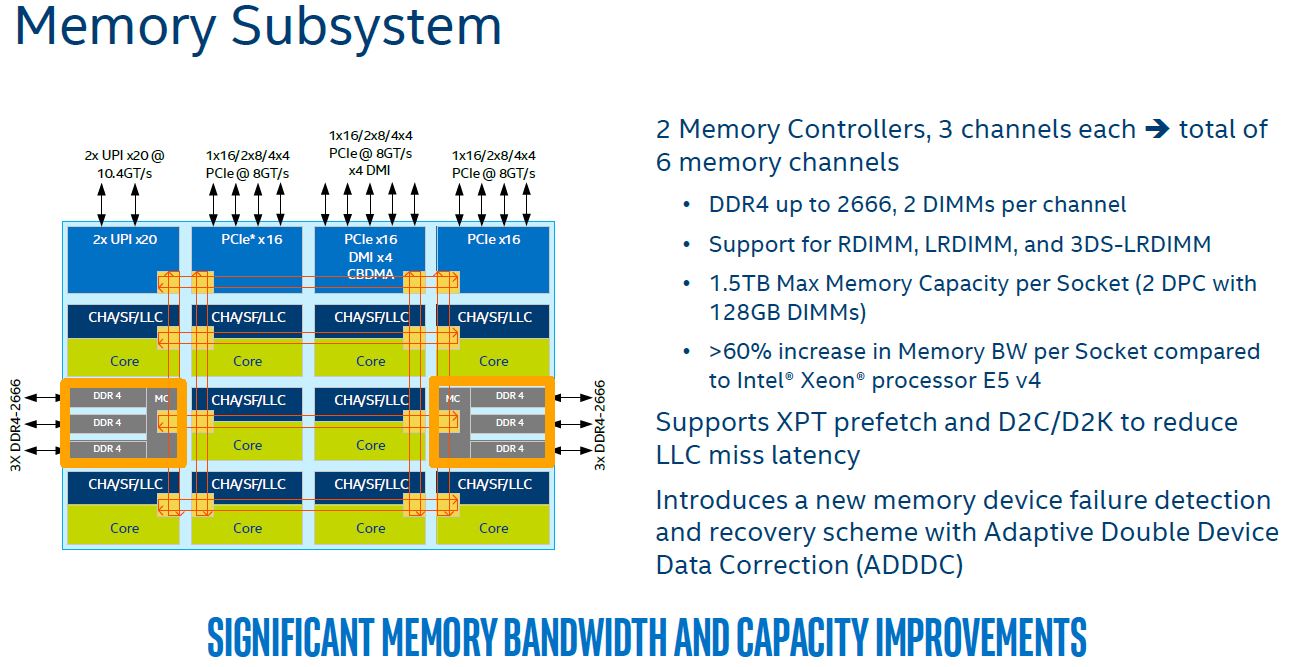
Each memory controller is a three channel controller, up from two on the Xeon E5 series. Each can support up to DDR4-2666 but is limited to 2 DIMMs per channel (down from 3DPC on Xeon E5.) Two controllers, three channels each and two DIMMs per channel give us 12 DIMMs total (2x3x2).
Each controller is on opposite ends of the mesh fabric which allows for RAM to core cache and RAM to PCIe, storage, and networking transfers to happen without hitting the PCIe bridges found in Intel Xeon E5 CPUs.
If we compare this with AMD, AMD does not need as “fancy” of an on-die design. AMD EPYC is using an 8 core silicon die that has access to two DDR4 channels locally. Everything else is over the Infinity Fabric.
The net impact is better performance and lower latency at a given bandwidth figure:
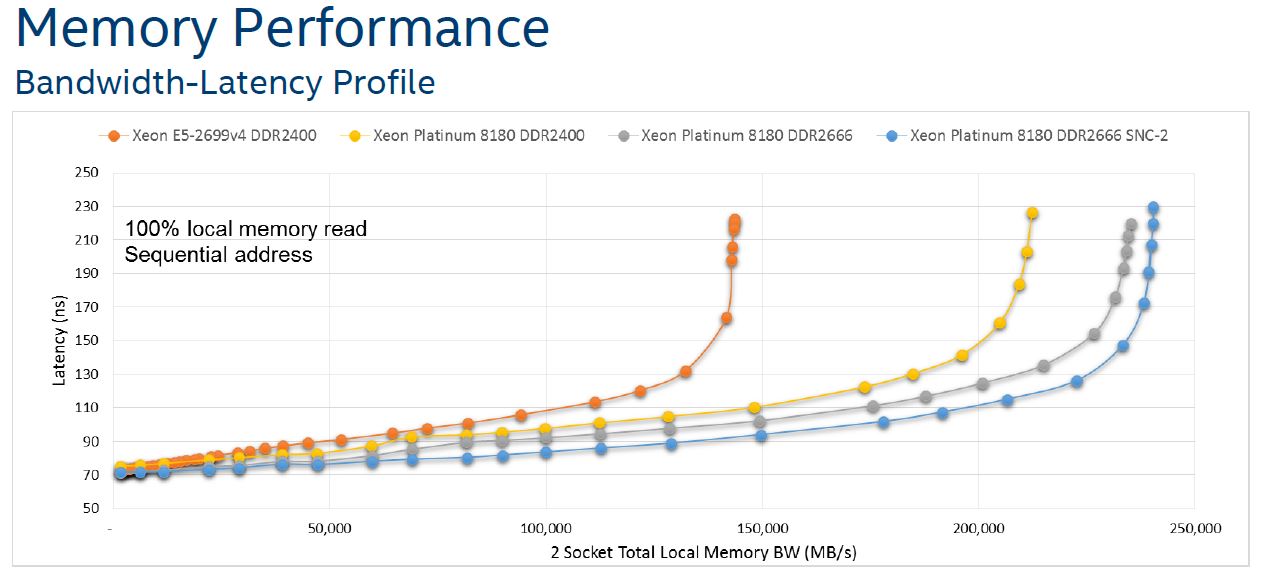
With more cores, latencies usually go up. Here we can see that core latency remain relatively similar to what we saw in the previous generation 24 core parts.
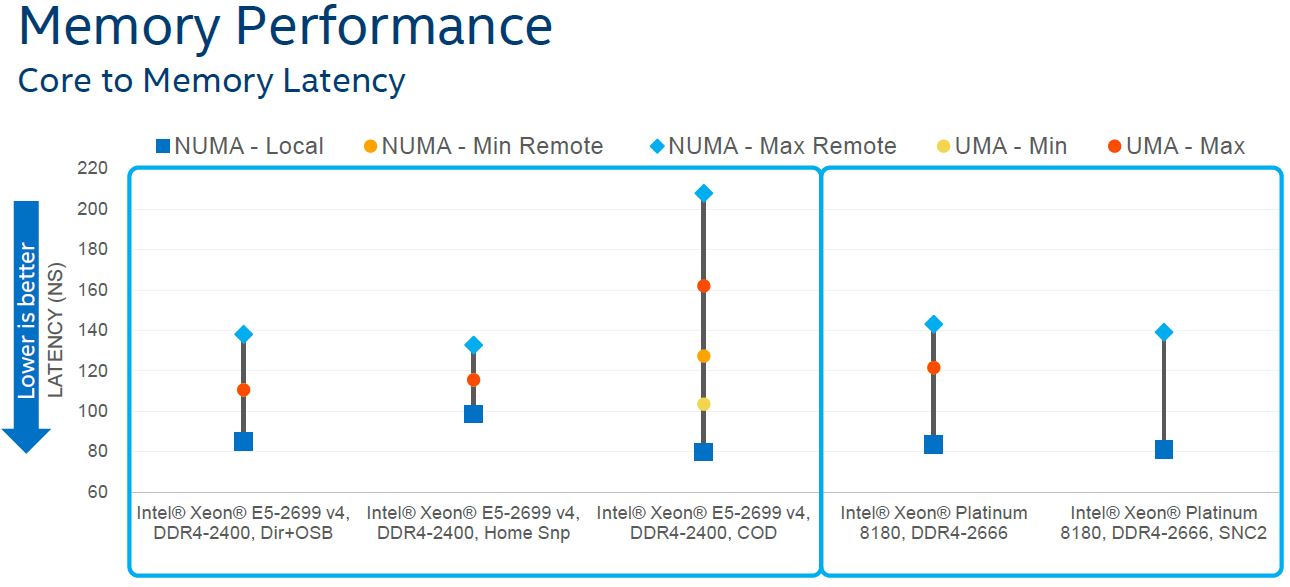
If you are looking at this and wondering how this compares to AMD EPYC, here is a key designation. The blue squares are local NUMA while the light blue dots are maximum remote NUMA hops. Intel has half of its resources on each NUMA node (each chip) in a two socket configuration. With AMD, only 12.5% of system RAM will be a local NUMA node in a two socket configuration. While the latency may be different, that is an important distinction on why Intel’s design is a higher performance piece of silicon.
Intel Mesh Interconnect PCIe Performance
PCIe bandwidth is likewise important. Whereas with the Intel Xeon E5 generation PCIe connectivity was on a single ring, with the Skylake mesh there are three full stops. One also will carry the DMI data.
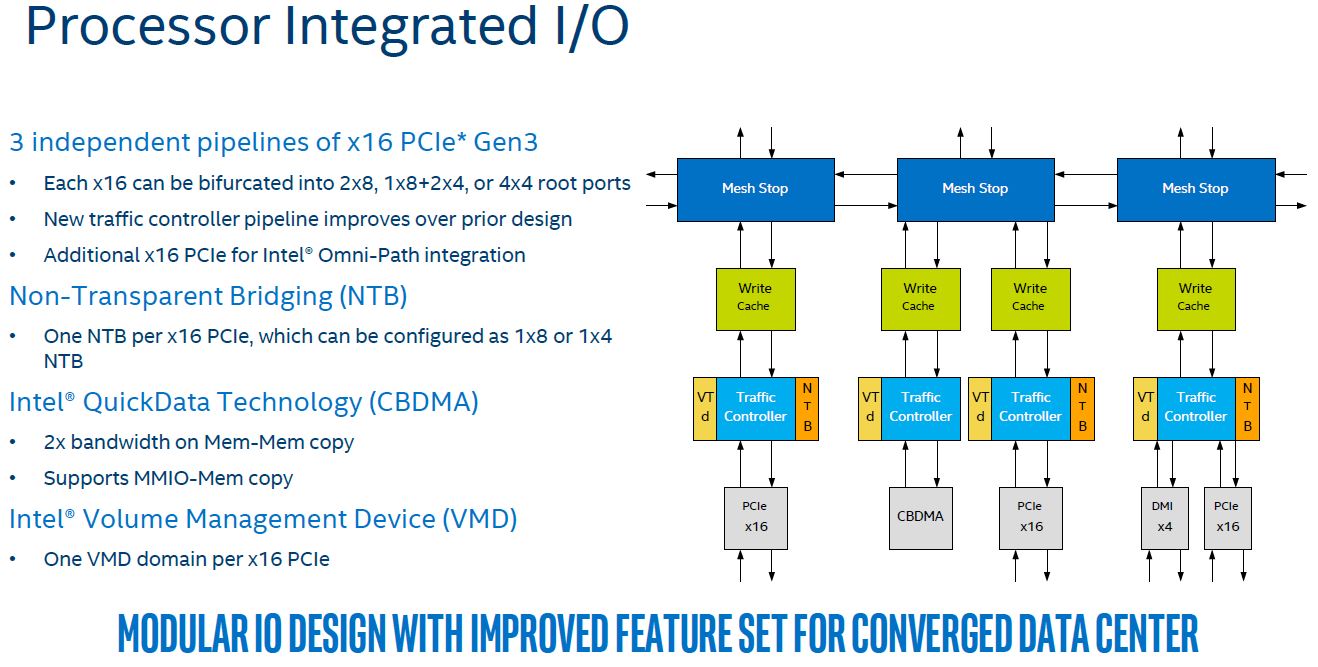
The completely odd part of the PCIe complex of Skylake is that each PCIe controller can only bifurcate down to a PCIe 3.0 x2 lane. We double-checked this at an Intel tech day and it was confirmed. The implication is huge:
Intel Skylake-SP PCIe controllers cannot bifurcate down to PCIe 3.0 x2 to support twice the number of Intel DC D-series dual port NVMe drives.
That revelation is shocking as we have been hearing a push for dual port NVMe this generation. If each controller could handle down to 8×2 then Intel could attach significantly more NVMe drives.
From a storage perspective, that is why AMD EPYC single CPU configurations are hot with OEMs right now and that is an early frontrunner for storage arrays. This is a spec that Intel just whiffed on which is doubly strange since Intel sells dual port NVMe SSDs that use PCIe x2 lanes for each host.
Having three stops instead of one per CPU has a significant impact on overall IO performance.
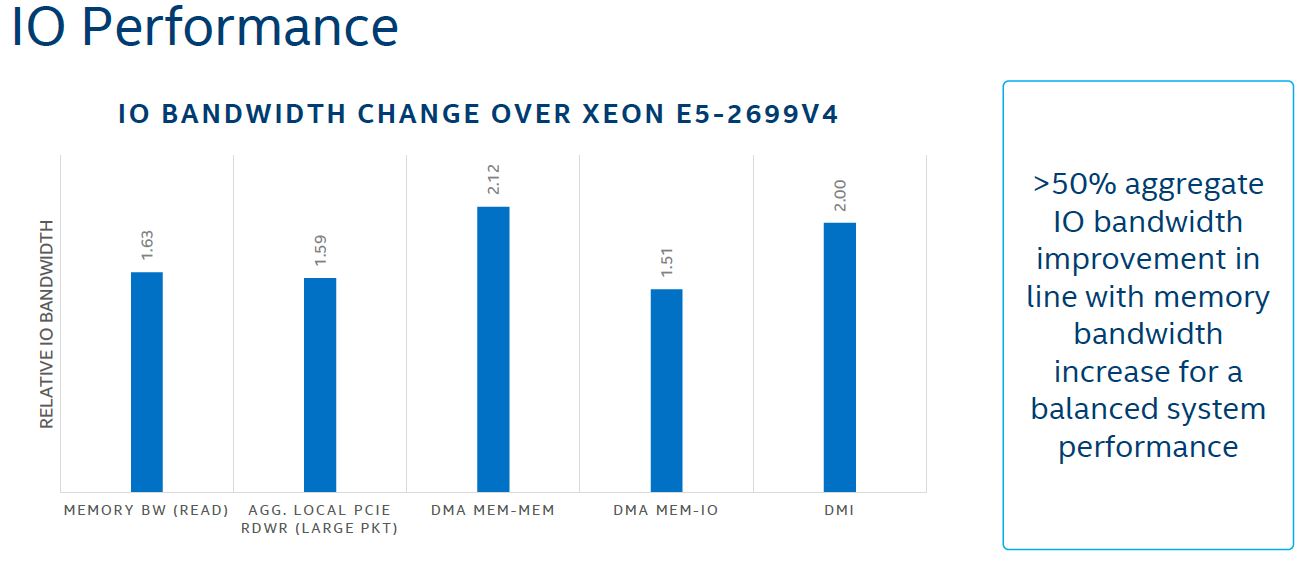
The key here is that with more hops along more mesh paths Intel is able to push more data over the mesh fabric to PCIe devices. That was a major weakness of the Intel Xeon E5 design that has been remedied.



{kind=link}
Thanks for this Series of Articles on the two camp’s newest Server Processors.
Did you see Kevin Houston’s Article: http://bladesmadesimple.com/2017/07/what-you-need-to-know-about-intel-xeon-sp-cpus/ ?
He mentions the lack of Apache Pass (Optane) and the observation that the SKUs with only 2 UPI Links are essentially a Ring Topology; you need to go top shelf for a Mesh.
Those Cables on the Skylake-F look innovative. If you accept a bit of Latency you can wire up a Rack of 8-ways for a SuperSever – 42U x 8 x 28 = 9,408 Cores per Rack (or only half that many if you need 2U per 8-way).
Wish AMD had made a separate SKU for 4-way but I guess they’re counting on the Core doubling that next year’s switch to 7nm will bring.
Thanks again Patrick, for all these Articles.