
Supermicro and Scality have a new solution that is being announced today. The new Supermicro Scality RING solution brings file and object storage. The solutions can start with as few as 3-node deployments which makes them relatively low-effort to deploy. These solutions provide native AWS S3 compatible object interfaces as well as NFS and SMB storage with a POSIX-style file system. With Scality RING, the company says it can support 14x 9’s of durability while running on standard x86 Linux servers without requiring kernel modifications. As a result, it can run on a wide variety of hardware. At STH, we have been planning for this launch for a few weeks.
Supermicro Scality RING Launched
Supermicro has some sizing guides in terms of its nodes designed with this Scality RING solution. Here are the key offerings:
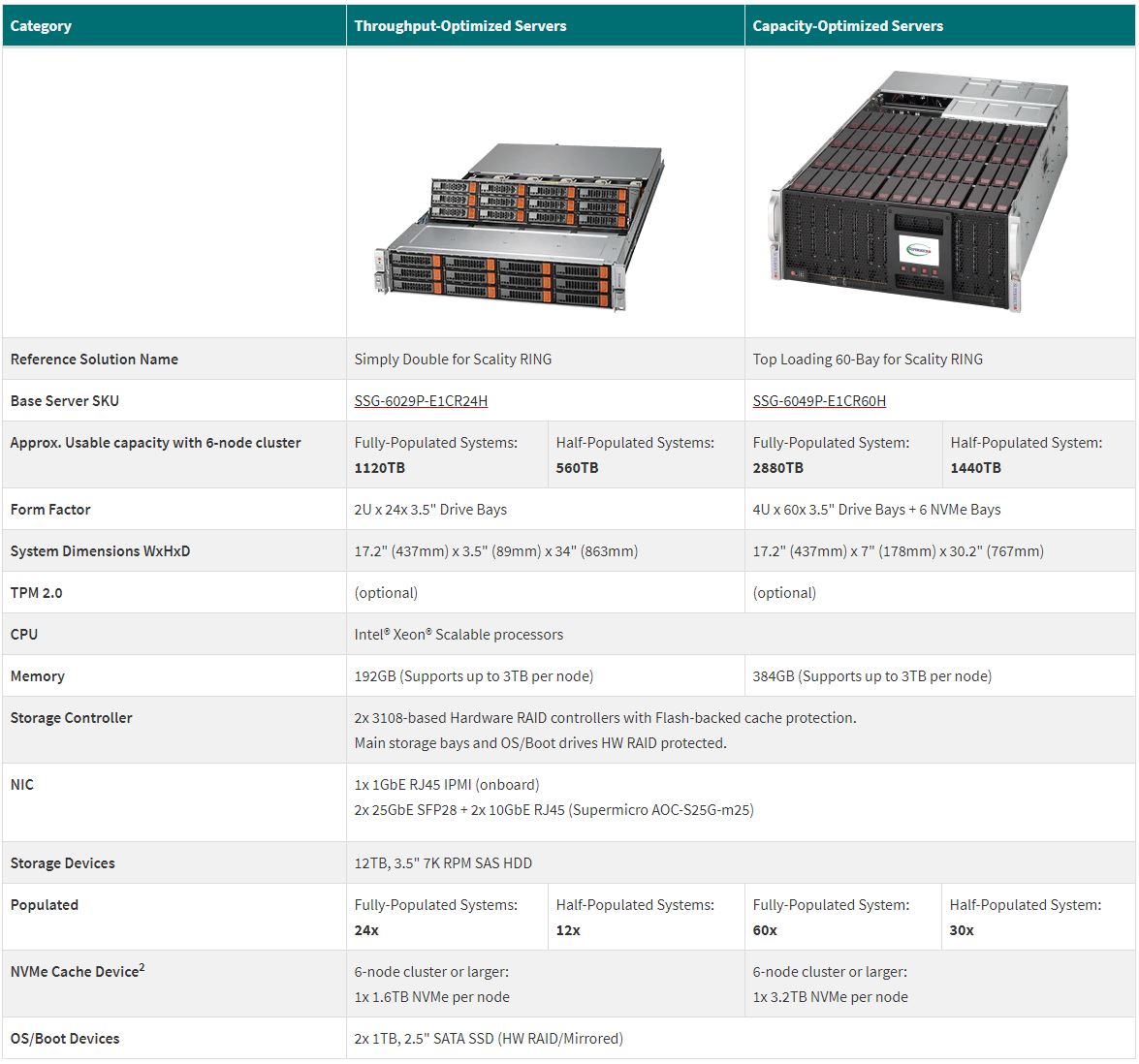
You may notice that these two solutions have been featured on STH recently. If you want to learn more about the first node, check out our Hands-on Look at the Supermicro Simply Double.
For the higher-density 60-bay top loader that STH brought you when it was first off the assembly line, and formally launched today, check out our New Supermicro 60-Bay Top Loading Storage Server Hands-on.
Using Scality, one can get access to a parallel file system that supports a large number of workloads that one can continue to add nodes and capacity to. Networking is provided by 10/25/40/50/100GbE standard networking making the back-end fabric relatively simple to manage. The solution also has features such as multi-site replication and scalability to hundreds of petabytes even if the initial installation is only a few hundred TB.
Final Words
Overall, this is something very cool. STH has been working over the past two months to bring you some more hands-on with the building blocks behind the Supermicro Scality RING solution. Let us know if you want to see more content such as looking at Scality on STH in the future.



{kind=link}
14 9s? No. That’s 1 microsecond of downtime per 5 years. It’s 1000x better than Backblaze’s observed durability level. It’s lower than the odds of your datacenter being destroyed by a tornado over any interesting timeframe. It’s lower than the lowest possible latency for any useful failover mechanism using modern networking. Heck, if you’re claiming 1 usec per 5 years, then presumably a 1 usec latency spike would count as an outage; system-management interrupts happen all the time and cause multi-millisecond latency hits.
14 9’s, lol, now there’s some whimsey. That’s a system that’s available all but 1.38 milliseconds per year. Nobody can actually provide such an SLA since the odds of World War 3 breaking out and impacting the power grid are more likely than that.
I just checked their site. That’s what Scality claims here https://www.scality.com/products/ring/ “EXTREME DATA DURABILITY (14x 9s)” How do they get 14x 9’s?
Data durability, not availability. As long as the data is not lost, it counts (i.e. power loss does not count if it comes back up).
Now, I’m still very skeptical that you can get 14x 9s out of a single box considering the big 3 clouds only offer 11x 9s across georeplicated sites. What happens when an earthquake/tornado/giant meteor hits your datacenter?
Ah, so they’re claiming 14 9s of *durability*, not reliability. That’s probably still bogus, but much less so. Like I said earlier, Backblaze is seeing 11 9s of durability, and they’re heavily optimized for cost. I expect that a reasonable design could add another 9 to that, but likely not a whole lot more without years of testing and refinement. You’ll really have to do multi-site replication to do better in the real world, just because there’s so much that can go wrong with singly-homed data. Fires, lightning, freak traffic accidents shunting high-voltage power into your building’s AC, floods, earthquakes, tornados, etc.
Scality does mutli-site.
Still.
Wish to see a fio randrw benchmark number for a single / multiple VMs :-)
No Epyc options?
Probably analogues to the way Wasabi calculates their reliability:
https://assets.wasabi.com/wp-content/uploads/2019/10/Durability-Tech-Brief-2019.pdf
Note: In the above paper, Wasabi only calculates the probability of a specific set of redundancy disks failing, if you properly compensate for the number of ways a set of redundancy disks can fail, they lose a few nines.
“analogues” needs to be “analogous” of course…
I don’t understand why there is no Epyc options on the storage side @Supermicro. It’s been a long time now.
I don’t get why they use Intel with the rather limited PCIe lanes.
“Our Scality RING system is designed to be 100 percent available and now with Scality HALO we have the cloud monitoring assurance for customers to guarantee 100 percent uptime for their Scality RING and S3 environments,” said Daniel Binsfeld, VP of DevOps and Global Support at Scality.
Source: https://www.scality.com/press-releases/scality-guarantees-100-percent-uptime-for-private-cloud-storage-environments/
It is their “guarantee” (what you are insured for), and may not reflect actual performance. Like a triple redundant power supply with 3 UPSes, and three gas powered generators, at multiple sites – if there’s a war and you can’t get gasoline it won’t be 100%.
If they have to pay out on a lot of claims they won’t be successful.