
Today marks a fun day for the world of CPU benchmarking, as the Standard Performance Evaluation Corporation (SPEC) has released a new version of their popular and widely used SPEC CPU benchmark suite. SPEC CPU 2026 is the latest iteration in a long line of CPU benchmark suites from the group, which over time has become the industry leading benchmark for measuring CPU performance thanks to its intense technical rigor and significant vendor buy-in. As a result, the release of a new version of the CPU suite is a major occasion in the world of CPU and system benchmarking, as it is one of the most important benchmark suites that the next decade of CPUs will be measured by.
The first new release of SPEC CPU in 9 years, SPEC CPU 2026, is intended to be a pretty extensive modernization of the CPU benchmarking suite. Most of the benchmarks from the previous version of the suite have been dropped in favor of newer workloads, and even the few that remain. Evergreen software, such as open-source compilers and image processing libraries, has also seen its workloads updated to be more modern. The end result is that, while SPEC CPU 2026 still fulfills the same high-level design goals as its predecessors, the actual code running underneath has changed significantly since the era of Skylake, Zen 1, and Cortex-A75.
Besides its technical rigor, the SPEC CPU suite is also notable for its industry participation; the benchmark continues to be developed by a group that is essentially a who’s who of the CPU world, including AMD, Intel, Arm, and SiFive. The high amount of vendor involvement and subsequent buy-in for the suite helps to contribute to SPEC CPU’s legitimacy and acceptance within the industry, as there is broad agreement that it is a fair benchmark – and perhaps more importantly, no significant claims that it is not. Which is a minor political minefield to navigate at times, but it means the benchmark is extremely well tested and vetted before release, which again dovetails with cementing the benchmark’s legitimacy and utility.
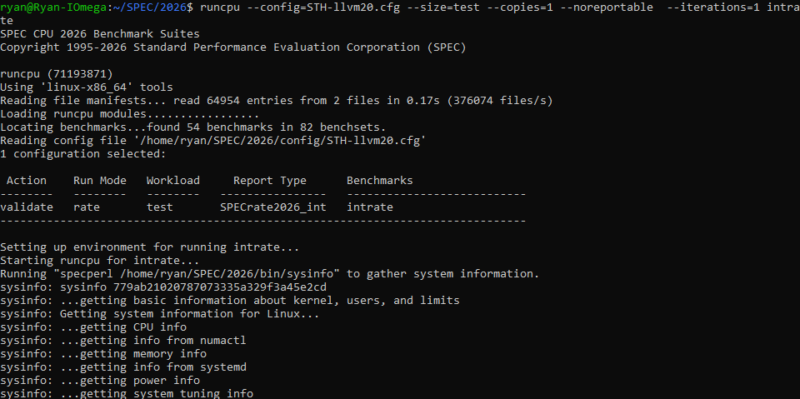
Finally, ahead of today’s initial release of SPEC CPU 2026, the consortium gave us early access to the release version of the benchmark to evaluate its performance. Consequently, alongside today’s high-level announcement, we have quite a bit of fresh data to pore through. So, without further ado, let us get started.
A Quick Recap of SPEC CPU
With an average release cadence over the last two decades of roughly every 10 years, despite how much we use SPEC CPU and other SPEC benchmarks here at STH, we do not get much of a chance to discuss their origins or the design decisions that go into them. So, if this is the first time you have been around for a release of a new SPEC CPU benchmark suite, here is a handy and brief rundown of what SPEC CPU is and why it matters.
The Standard Performance Evaluation Corporation (SPEC) is a group whose mission is right there in the name. It is a non-profit industry consortium that exists to organize the development of industry-standard benchmarks. As with other industry consortia, the purpose of the group is not so much to develop tests on its own, but rather to bring together major players from industry and academia to work together to develop benchmark suites.

Of SPEC’s rather significant collection of benchmark suites, by far the highest-profile is SPEC CPU. This is both because of its vintage, it was SPEC’s first benchmark, released back in 1989, but also because of how widely it is used. Though ostensibly designed for benchmarking servers and other high-performance systems, SPEC CPU has become widely used at multiple levels of devices, including desktop and workstation computers, and most recently, mobile devices, as those processors have become powerful enough (and paired with enough memory) to run the benchmark suite. As a result, SPEC CPU has become one of the primary benchmarks for comparing CPU architectures across the spectrum and is used to evaluate the performance, power efficiency, and architectural efficiency (IPC) of various CPUs.

The benchmark suite’s ubiquity stems from its portability. Rather than being distributed as pre-compiled binaries for specific platforms, the SPEC CPU benchmark suite is distributed entirely as source code. As a result, with a modern compiler toolchain that supports C, C++, and Fortran, it is possible to compile and run SPEC CPU on any system, regardless of CPU architecture, even those that do not yet exist. There is admittedly quite a bit of nuance in that detail (you need standards-compliant compilers, among other things), but it means that the benchmark is not reliant on SPEC supporting a specific platform, and that hardware developers can immediately employ and benchmark new hardware features without needing to wait on newer binaries from upstream.
The corollary is that, rather uniquely, SPEC CPU is as much a benchmark of compilers as it is of hardware. Because the source code is a fully portable, high-level implementation of a program, and thus contains no CPU intrinsics or other architecture-specific code, the benchmark is at the mercy of a good compiler to turn it into fast, efficient machine code. This means that compiler improvements to boost your SPEC CPU scores are fair game (an especially important aspect for hardware vendors who produce their own compilers), but the catch is that those optimizations cannot be for SPEC alone; they need to benefit a wider class of programs.
Ultimately, this is a significant distinction from most other CPU benchmarks, which are distributed as pre-built binaries. In effect, whereas those benchmarks strive to measure how well a given system executes a very specific batch of machine code, SPEC CPU is all about measuring algorithms and workloads. It is a distinction that has little impact on day-to-day usage, but it is important for understanding the benchmark’s design criteria and what SPEC ultimately aims to accomplish.
Speaking of design criteria, it is worth noting that SPEC CPU is designed to be as much a CPU test as possible. Which sounds a bit tautological, but underscores how much work goes into developing benchmarks that are not tests of other aspects of computer design. SPEC CPU is not a whole system benchmark (SPEC has SPECworkstation for that), it is a benchmark of CPU and memory subsystem performance, with design choices that minimize bottlenecking elsewhere.

In particular, SPEC CPU avoids file I/O as much as possible to prevent it from being a bottleneck. The benchmarks are also written and/or modified from their original forms to eliminate non-deterministic inputs and actions (such as hardware random number generators and unstable sorts) and ensure they are deterministic. And ultimately, even the operating system is cut out of the loop as much as possible: SPEC aims for at least 95% of benchmark execution time to be spent on user-land code, so that the benchmarks do not become a proxy test for the OS.
Finally, the workloads themselves are selected to be representative of modern computer use cases, avoiding testing outdated software or algorithms of little interest outside academia. In practice, this means the SPEC CPU benchmark suite ends up looking a bit server- and workstation-focused. It is a portable and headless benchmark, so it does not include UI tasks. Still, the benchmark suite’s overall scope is incredibly broad, with SPEC CPU 2026 being the broadest yet. Among the 52 benchmarks in the latest edition of the suite, there are benchmarks for programming/compiling, media, AI, electronic design, networking, databases, and computational science workloads. The net result is that the benchmark ends up covering a very wide range of algorithms, and by extension, stresses numerous different aspects of the host CPU.



{kind=link}
If I understand the “Scaling, fprate” chart correctly, the “ideal Nx” line is nonsense for the Intel and nVidia systems. The *actual* ideals for those systems is variously 8x, 16x, or 10x for their different core types. And by adding the aggregates from both P and E cores, you have a good number for total system performance, but an utterly useless number for measuring scaling for a particular core type, which is what a first glance at that chart suggests (incorrectly) it’s about. Which is too bad, because there is an interesting idea there.
I mean, really, in what way is it useful to know that 8P+16E cores can achieve 6.68x the performance of a single E core? It would be much more interesting to know how 16 E cores measure up against 1 E core.
Hey, justsomeguy – I had a similar thought. We have updated charts, but they did not make it into this before it went live because it was a bit of a reflection that led to the thought. Hopefully, it makes it into the next set of content. Here is the idea:
Really, the ideal for heterogeneous processors is the maximum performance of each type multiplied by the number of cores in that type, and summing those. That is still not perfect, but it is closer to what you are thinking.
One other one to call out is that on the AMD side, you have 1c/1t and then multiply it by the number of threads, so 16 cores, but 32 threads. I do not think anyone expects SMT to be the same performance as a physical core, so saying 32 times that 1c/1t result is also a bit odd for “ideal” if you start going down a weighted ideal for heterogeneous cores. Is the base then the 1c/2t number? Is it then 1c/2t minus 1c/1t for an ideal SMT thread and calling that a “core” for our weighting?
All good thoughts and feedback. Another very valid point is that we are running these at lower compiler optimization levels than in the official runs. That is actually by design, but there is always a fair question of whether we should do more optimization.
Patrick – My first message originally had some thoughts about threads vs. cores but I removed them before posting as I wanted my main point to be clear and unelaborated. But since you bring it up…
I like your notion of 1c2t-1c1t as a base, but I think that you need to take a step back first and ask, what are you actually trying to do? Do you want to understand an architecture and maybe learn something about whether the choices made in it were good ones? Or do you want to build as good a picture as you reasonably can of what a machine’s performance profile is? These are two not entirely compatible goals, though there is clearly a lot of overlap. Once you decide, that answers some of these questions, or at least narrows down the answers.
In particular, in the second case, it really doesn’t matter what those computations come out to. All that really matters is what you actually measure.
Hey justsomeguy and Patrick, I think in the end what matters is what performance one should expect from a processor and also what one expects from a certain architecture. And here one should add with really bold letters – at what price and at what power level. Considering the last remark, the scores depicted here should also account for the fact that you tested thermally constrained systems – you didn’t test open air systems with an unrestricted thermal solution. Therefore you also test the capabilities of an overall system manufacturing and its cooling solution. To go back to the conversation of the performance expectations, one should also consider why we have p and e cores and of course multithreading. The concept of heterogeneity is to better handle some aspects indirectly related to performance – it is all about efficiency. If you take efficiency (perf/watt) out of the scope, then I find the expected scaling basically wrong. If you take a workload that has the characteristics mostly suited for a p-core and then use it in multiple cores, it does not make real sense to me to consider the scaling beyond the maximum of p-cores – what you may gain from a number of e-cores running alongside is just an added bonus (which may also not be ideal in certain use cases). In the same context, multithreading is used to exploit certain characteristics of the workloads to use the same underutilised resources for multiple processes/threads. In that context, I would consider the 1c/1t as the baseline, the theoritical maximum to be the number of cores and if a workload manages to achieve performance above that level, then this is to be a welcome bonus. Anyway, since you provide the raw data, anyone can make his/her own readings and take your analysis as one aspect that he/she may accept or not. In the end, taking out the dell laptop from the equation, I find that the other two platforms are generally not…. general purpose. So one may focus on the exact applications that they are intended for and not look at the overall results to make what the numbers mean. For example, I would not expect anyone to buy an nVidia Spark system to run gem5 or use it as a database server, although I would expect that the performance of Python and AI related stuff are very important.