
At STH, we are gearing up to do a summer series on Intel QuickAssist. As part of that, we came across something that was just interesting. The Silicom M20E3ISLB is an Intel QuickAssist accelerator in a 2.5″ U.2 drive form factor commonly associated with NVMe SSDs.
Silicom M20E3ISLB is Intel QuickAssist U.2
The M20E3ISLB looks almost like a 2.5″ NVMe SSD without its cover. Instead, the card is utilizing an Intel Lewisburg PCH mounted on a 2.5″ PCB with a SFF-8639 connector. Instead of cooling NAND, DRAM, and a SSD controller, the giant heatsink is dedicated to cooling the onboard PCH. Most Intel QuickAssist accelerators that are not integrated into a package (e.g. the Atom C2000, C3000, C5000/ P5000, and Intel Xeon D-1500, D-1600, D-1700, D-2100, D-2700 series) are actually based off of the PCH.

The newer Lewisburg IP is an upgrade to the Coleto Creek generation. Coleto Creek you may have seen in the Intel 8925, 8926, 8950 accelerators, and so forth. We used this for Intel QuickAssist Technology and OpenSSL – Benchmarks and Setup Tips and Intel QuickAssist at 40GbE Speeds: IPsec VPN Testing in 2016/ 2017.
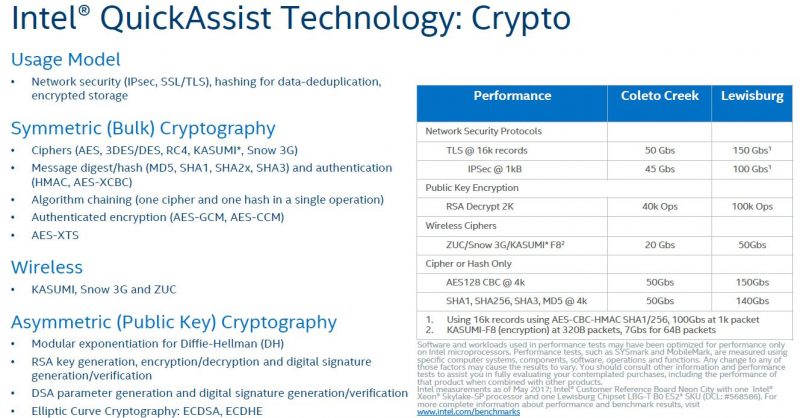
Aside from the original Lewisburg chipsets, there were also the refresh versions that came out to support 3rd Generation Intel Xeon Scalable Cooper Lake and Ice Lake CPUs.
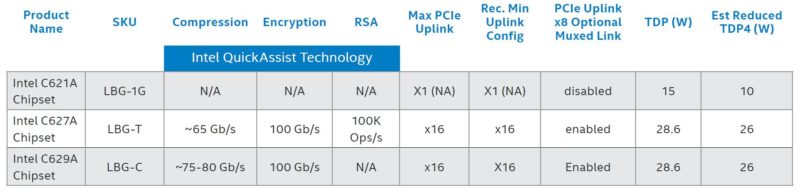
The key to making this work was shown during the Skylake launch piece (linked above) in the PCIe Endpoint Mode from that launch’s slide below. The Lewisburg PCHs are designed to allow additional connectivity beyond just the normal DMI G3x4 link with PCIe Gen3 x8 and x16 options. The Silicom card is using just x4 because of the U.2 form factor. Fewer links also helps to lower power consumption to the 25W connector limit.
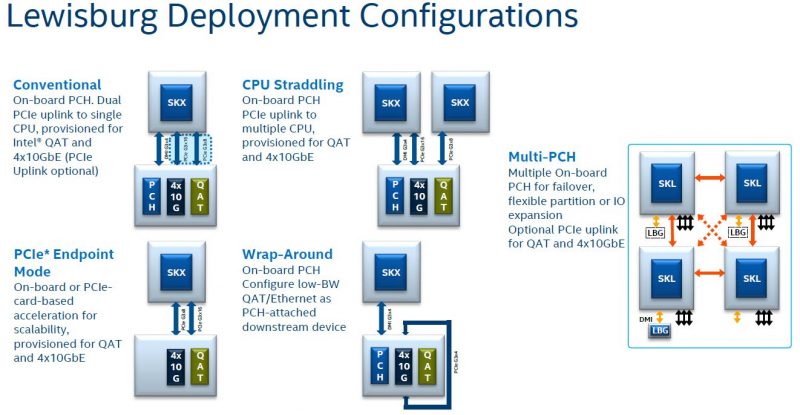
Another fun aspect of the Silicom M20E3ISLB is that its specs say it supports hot-swap capabilities.
Here are the specs from Silicom in terms of the performance based on each of the four versions of the Lewisburg PCH.
| LBG-L / LBG-T | LBG-M | LBG-E | |
| SSL/IPSec | 27Gbps (PCIe BW) | 27Gbps (PCIe BW) | 20Gbps |
| Compression Deflate | 27Gbps (PCIe BW) | 27Gbps (PCIe BW) | 20Gbps |
| Decompression Deflate | 27Gbps (PCIe BW) | 27Gbps (PCIe BW) | 27Gbps (PCIe BW) |
| RSA Decrypt 1k-bit | 550K Ops/sec | 550K Ops/sec | 550K Ops/sec |
| RSA Decrypt 2k-bit | 100 Ops/Sec | 40 Ops/Sec | 20 Ops/Sec |
| TLS Handshakes ECDH_RSA2K: | 440K Ops/sec | ||
| TLS Handshakes EDHE+ECDSA | 51K Ops/sec | ||
| SSL/IPSec + Compression + PKE | Total 120 Gbps + 100K Ops/sec |
In the spec table, LBG is Lewisburg, and the trailing letter is the model. We will notice that all but the LBG-E model can be limited by the PCIe bandwidth for compression and SSL/ IPSec workloads. Even the LBG-E runs into the PCIe bandwidth limit on compression. If you found yourself asking, which Lewisburg generations are possible in U.2, apparently Silicom has four different flavors:
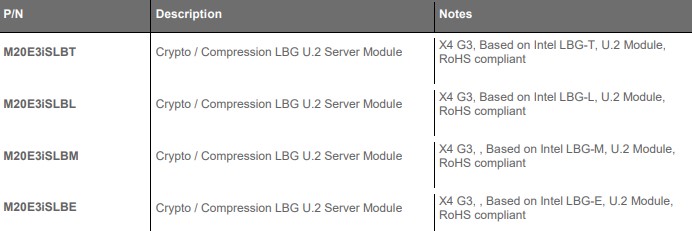
Different SKUs offer different performance so that is why, even though they may seem similar, we get different SKUs here.
Final Words
We had no idea that this even existed and just came across it while working on the summer series. For a holiday weekend, we thought it may be interesting to share with our readers. This is an example of an accelerator being placed into a SSD form factor. If you saw our E1 and E3 EDSFF to Take Over from M.2 and 2.5 in SSDs piece, the transition to the newer EDSFF form factors that can support higher power and cooling in a hot-swappable form factor will make more sense. U.2 was designed to fit alongside lower-performance SAS/ SATA, so there are thermal limits that this Silicom card pushes up against. Still, when we came across the M20E3ISLB we thought it was an interesting solution to add crypto and compression offload to a server and figured it would be a fun one to share.



{kind=link}
I can understand this in the context of a compression workload; but are there circumstances where you’d be inclined to add a Lewisburg-based part that doesn’t take advantage of the integrated NICs to handle things like TLS and IPSec acceleration rather than just using a Lewisburg-based NIC that has the same capabilities while also handling NIC duties?
Is there a population of existing systems with fast but minimally accelerated NICs that this is intended as an upgrade for; or is there a scenario where going with this unit is more sensible than just going with the accelerated NIC instead?
Very Cool. Does this work on EPYC Servers?
In Linux, the driver would probably see it hanging off of 4x of EPYC’s PCIe lanes and the code path would probably enable Cryptography offloading and pfsense acceleration, etc.
Quite interesting thing. Lots of telcos that are standardizing around 1U commodity servers might be interested in checking this over.
There are very few servers that are equipped with QAT enabled LB chipset, and in 1U most of the PCIe slots are utilized by NICs anyway. This U2 accelerator might be something that is godsend for such niche.
Regarding the systems – there is a Intel O-RAN framework https://www.intel.com/content/www/us/en/communications/virtualizing-radio-access-network.html
I can see this being quite useful for storage, having an SSD-based ZFS system where enabling encryption tanked the performance, because the CPUs couldn’t keep up with encryption at the bandwidth the SSDs could write at.
I suppose the only issue there is that if your SSDs are already maxing out multiple PCIe lanes, then funnelling all the traffic through a PCIe x4 connector to do the encryption will still be somewhat of a bottleneck.
Or one could put it in a ThunderBolt enclosure to use with a Laptop ;)
I’m wondering what the use-case is, encryption / compression for either disk writes or network is going to be seriously hamstrung by the PCIe bandwidth. Is it possible to use this to encrypt data and the devices DMAs to an NVMe disk without going through the CPU?
in the table it should be RSA Decrypt 2k-bit 100k Ops/Sec, not 100 Ops/Sec.
These devices are fantastic and we have several of them (any 100s of other Silicom PCIe QAT devices) but the specific issue not covered in this article and likely because it was never physically in the hands of the person writing the article is the mechanics of the device. This U.2 device has mounting screws on the bottom of the device and that may not seem like much of a deal but short of Supermicro SAS/SATA drive trays and a PCIe JBOF from serialcables.com no other vendor offer NVMe drive trays that are compatible (HPe/Lenovo/Dell we’ve tried). We have worked with Silicom to address this but as of yet there are no variations with mounting screws on the sides like most/all other NVMe U.2 devices use. Seriously though; great form factor for a great chip and as far as I know globally unique.
Putting such processing so far from the CPU and Memory is a very poor architectural choice. The Intel processors historically have very little uncommitted memory bandwidth. That’s a big reason the AMD parts get the performance they do other things being equal. Putting the QAT processing *in* the CPU avoids tromboning across the PCIe connection and makes it fight for bandwidth the other PCIe devices, esp the NIC. The aggregate of all this is that the data being processed by an external QAT helper is dragging the data across the memory channels at least 3 times, probably doing some cache wiping in the process, and across the PCIe controller and PCIe interconnect at least 3 times (ignoring the transactions required to setup the NIC and the QAT to do their requisite transfers (assuming streaming rates). If the NIC and QAT have the right PCIe hardware (and the device driver author is mad enough), it might be possible to scatter-gather an inbound packet so the right stuff goes directly to the QAT, assuming the NIC isn’t overrunning it thereby needing a packet queue in main memory. I’ll leave the sums as to what it could look like if the QAT is in the CPU and doesn’t require pumping bytes across the PCIe beyond that required by the NIC. Also note that this is pretty tricky to use well with the usual network stack structure. Going fast usually requires special-casing the whizz outa things, but that’s usually the cost of serious go-fast: dedicated paths highly tuned.