
At Hot Chips 2023 (35) Samsung is talking about its processing-in-memory (PIM) again with new research and a new twist. We have covered this previously, for example in our Hot Chips 33 Samsung HBM2-PIM and Aquabolt-XL. Now, Samsung is showing this in the context of AI.
Since these are being done live from the auditorium, please excuse typos. Hot Chips is a crazy pace.
Samsung Processing in Memory Technology at Hot Chips 2023
One of the biggest costs in computing is moving data from different storage and memory locations to the actual compute engines.
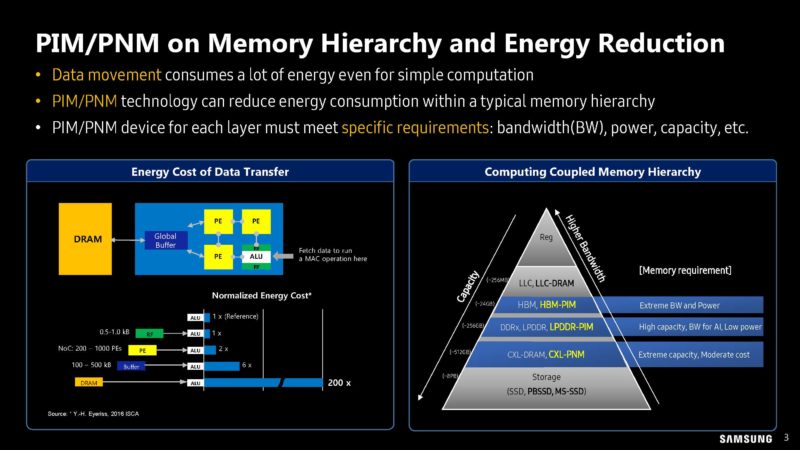
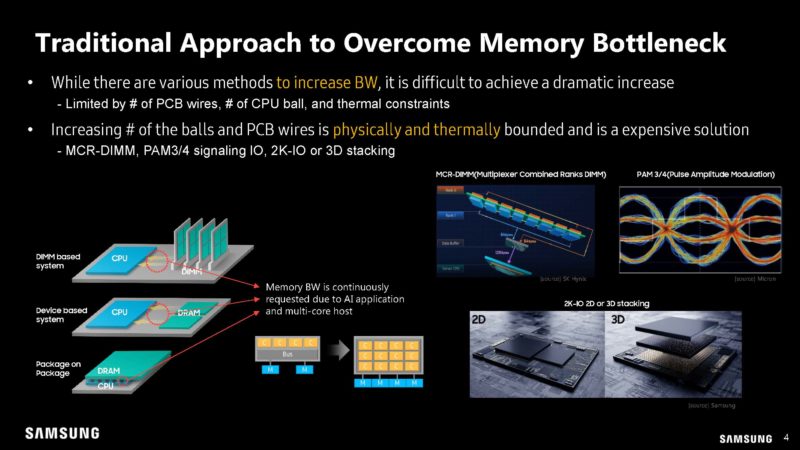
Currently, companies try to add more lanes or channels for different types of memory. That has its limits.
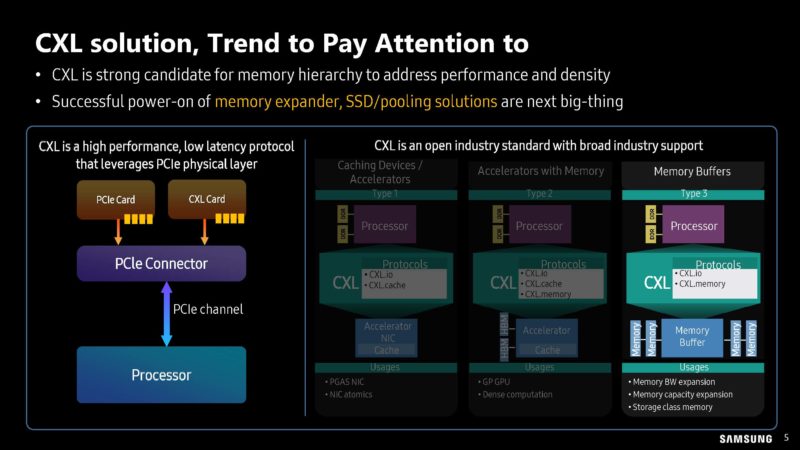
Samsung is discussing CXL. CXL helps because it allows for things like re-purposing wires for PCIe to provide more memory bandwidth. We are going to discuss more on CXL Type-3 devices in the future on STH and have covered them a few times.
Samsung is discussing GPT bottlenecks.
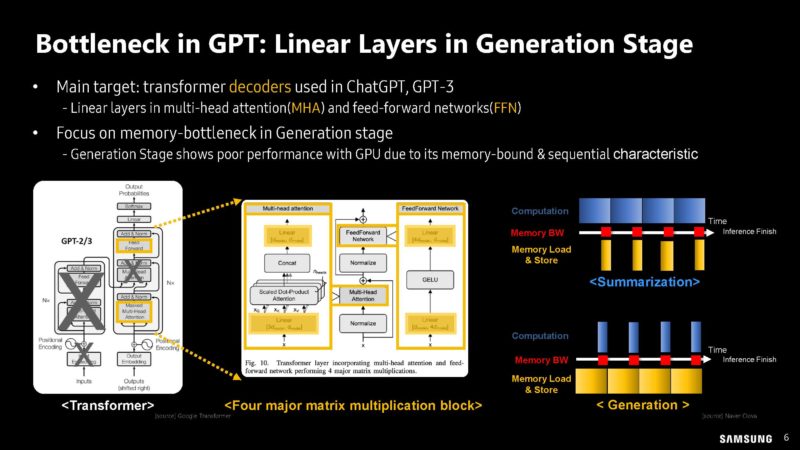
Samsung has profiling GPT’s compute bount and memory bound workloads.
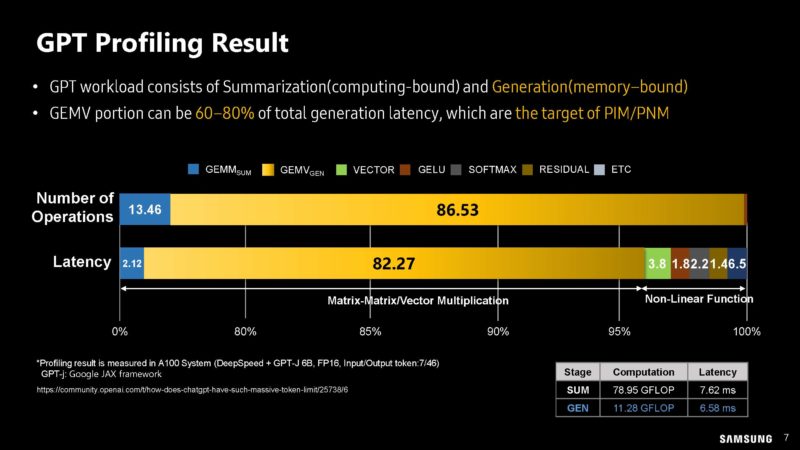
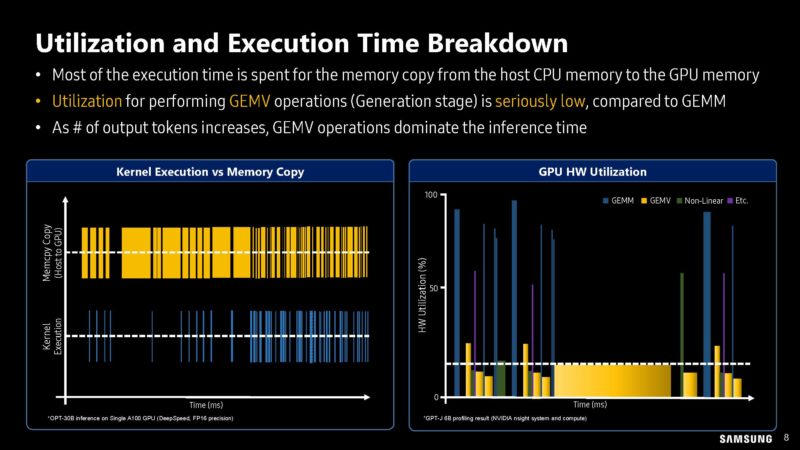
Here is a bit more on the profiling work in terms of utilization and execution time.
Samsung shows how parts of the compute pipeline can be offloaded to processing-in-memory (PIM) modules.
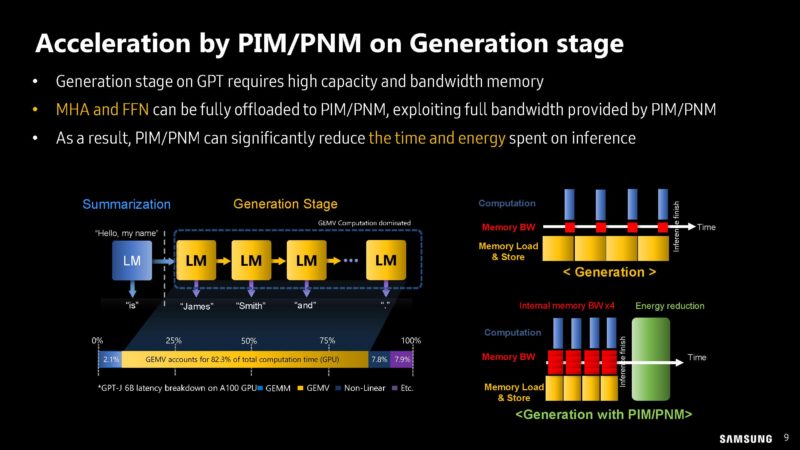
Doing processing at the memory module, instead of the accelerator saves data movement lowering power consumption and interconnect costs.

While SK hynix was talking about GDDR6 for its solution, Samsung is showing its high-bandwidth memory HBM-PIM. We are going to be showing HBM on Intel Xeon MAX CPUs in the next week or so on STH, but that is not using this new memory type.
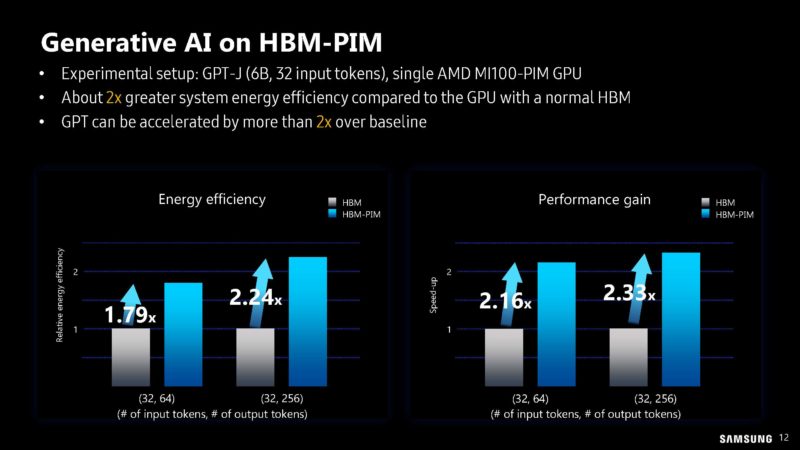
Apparently, Samsung and AMD had MI100’s with HBM-PIM instead of just standard PIM so it could build a cluster so it could have what sounds like a 12-node 8-accelerator cluster to try out the new memory.

Here is how the T5-MoE model uses HBM-PIM in the cluster.
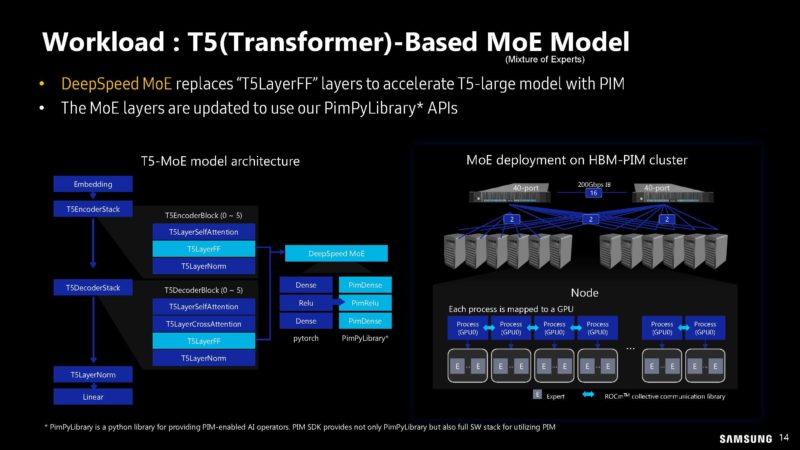
Here are the performance and energy efficiency gains.
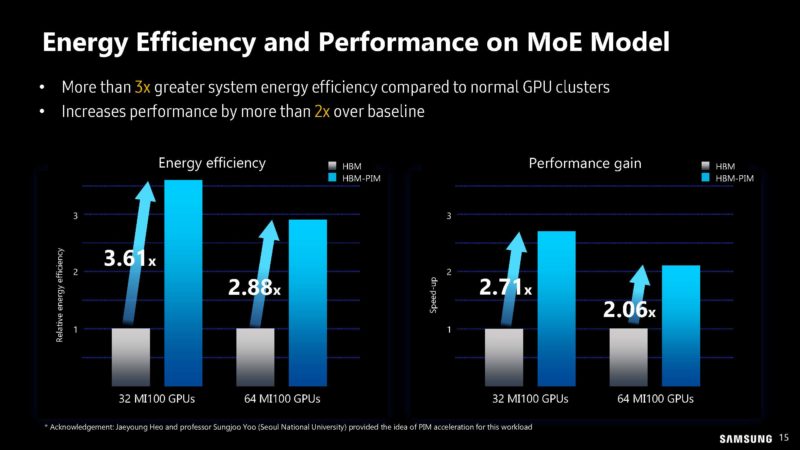
A big part of this is also how to get the PIM modules to do useful work. That requires software work to program and utilize the PIM modules.
Samsung hopes to get this built-into standard programming modules.

Here is the OneMCC for memory-coupled computing to-be state, but this sounds like a future, rather than a current, state.

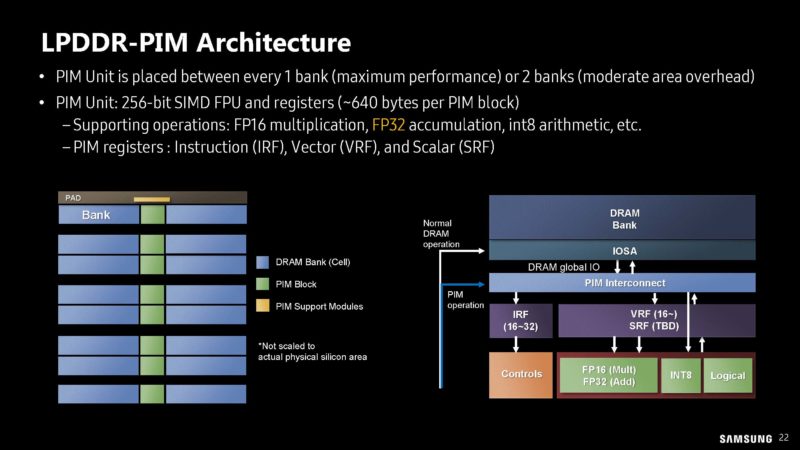
It looks like Samsung is showing off not just the HBM-PIM, but also a LPDDR-PIM. As with everything today, it needs a Generative AI label.

This one seems to be more of a concept rather than the HBM-PIM that is being used on AMD MI100’s in a cluster.
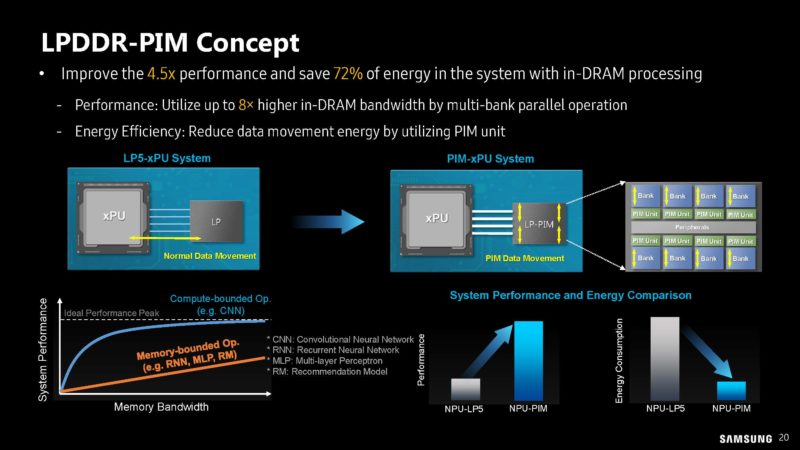
This LPDDR-PIM is only 102.4GB/s of internal bandwidth, but the idea is that keeping compute on the memory module means lower power by not having to transmit the data back to the CPU or xPU.

Here is the architecture with the PIM banks and DRAM banks on the module.
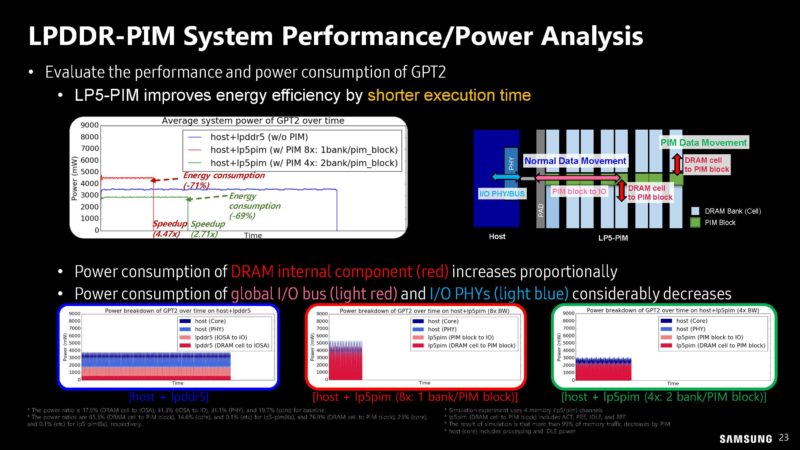
Here is what the performance and power analysis looks like on the possible LP5-PIM modules.
If HBM-PIM and LPDDR-PIM were not enough, Samsung is looking at putting compute onto CXL modules in the PNM-CXL.
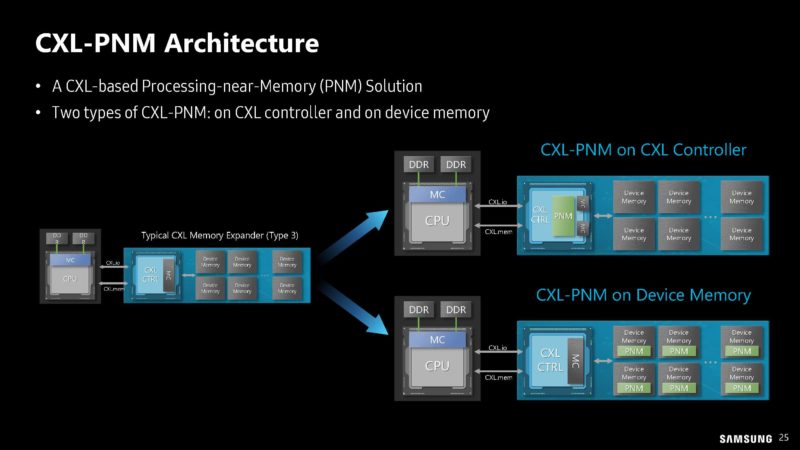
The idea here is to not just put memory on CXL Type-3 modules. Instead, Samsung is proposing to put compute on the CXL module. This can be done either by adding a compute element to the CXL module and using standard memory or by using PIM on the modules and a more standard CXL controller.

Of course, we have our showing of how this helps generative AI with the GPT side.
Samsung has a concept 512GB CXL-PNM card with up to 1.1TB/s of bandwidth.

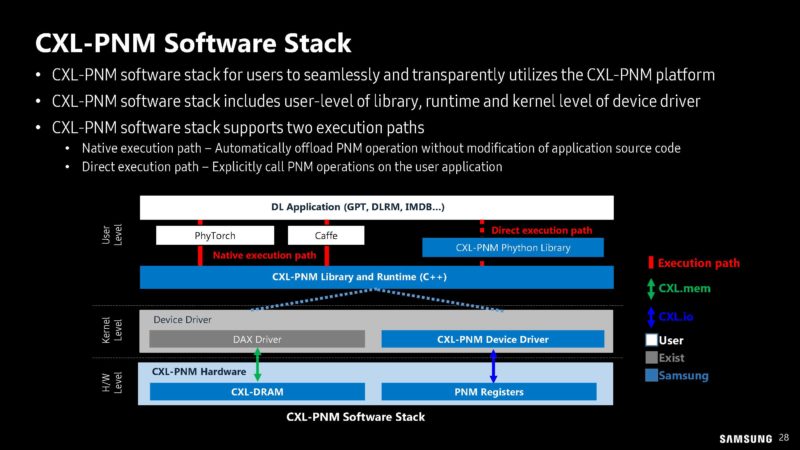
Here is Samsung’s proposed CXL-PNM software stack.
Here are the expected energy savings and throughput for large-scale LLM workloads. CXL is usually going over wires also used for PCIe, so energy costs for transmitting data are very high. As a result, there are large gains by being able to avoid that data transfer.
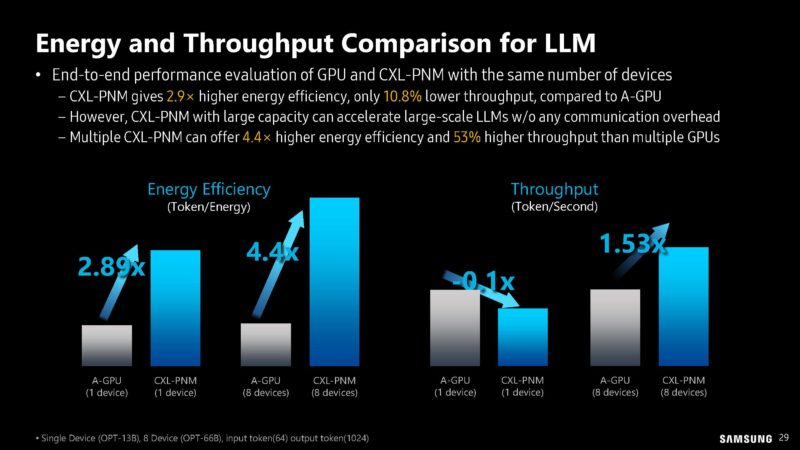
Samsung is also focused on the emissions reductions as a result of the above.

Google earlier today gave a big talk about CO2 emissions in AI computing. We plan to cover that later this week on STH.
Final Words
Samsung has been pushing PIM for years, but PIM/ PNM seems to be moving from purely a research concept to the company actually looking to productize it. Hopefully, we get to see more of this in the future. The CXL-PNM might end up being a ripe area for this type of compute.



{kind=link}
So is this commercially available or not?