Dual AMD EPYC 9965 Server Running Deepseek-R1 671B FP16 Performance
For those hoping to run a giant model at 100 tokens per second, this is not that. Still, we commonly saw out-of-the-box performance in the 1.4 tokens/ second range using completely default settings. That is not fast by any means, but it is acceptable if you are going to task the model and then walk away coming back for a response a few minutes later. Also remember that this is a reasoning model, so the number of tokens generated is higher because there is a “thinking” phase. More tokens generated to get to an answer means more work needs to be done. By default, Ollama will use all of the cores in a system and load the model into memory.
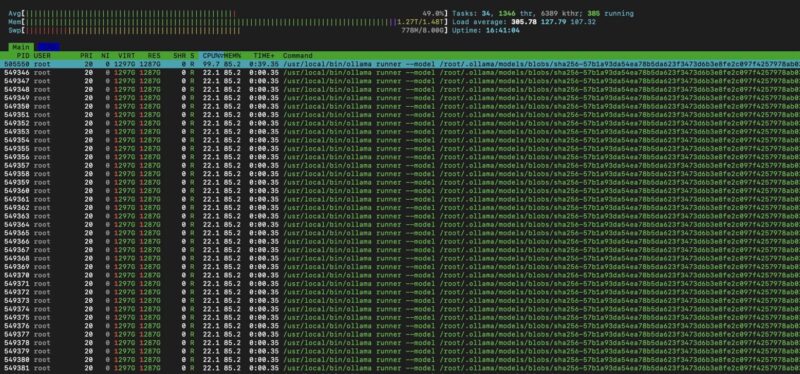
The first time you load a model, or change the default tuning settings, the model will reload itself into ollama and for a 1.27TB model that can actually take a few minutes.
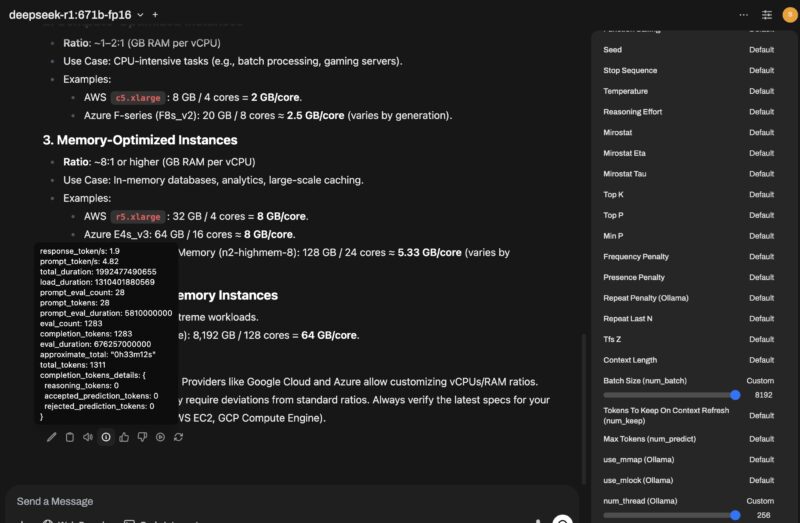
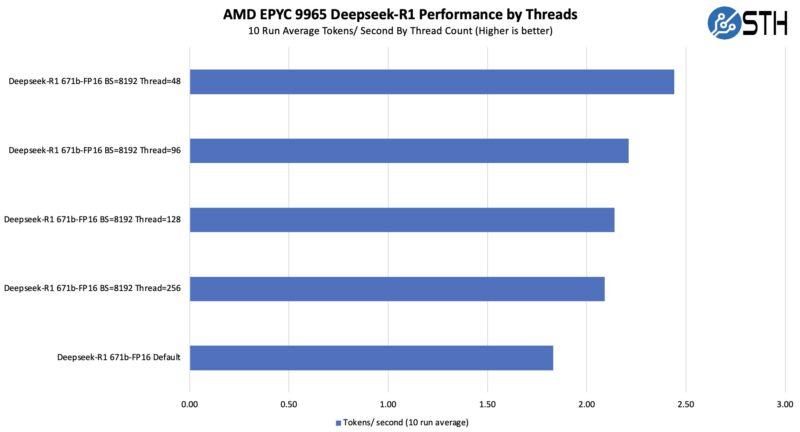
Something we noticed here, was that even a tiny bit of tuning could get a lot of additional performance. For example, we swapped the default 512 batch size with 1024 and set the number of CPU threads to 256, which is not a lot for a 784 thread server, and the performance jumped to around 1.9 tokens per second.
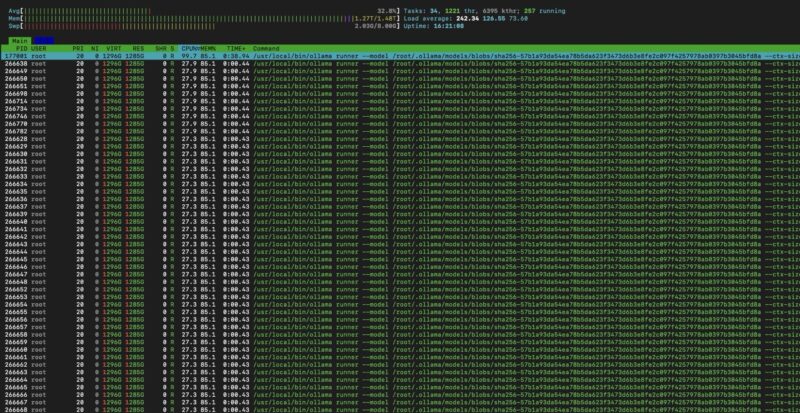
When we did this, however, we noticed that we were capped at around 33% CPU utilization and had around 200GB of memory free in the system. That was in-line, and better than some runs we did with the default 384 thread cap to match the number of CPU cores. We reduced the thread count by 128, and often saw 2.0-2.1 tokens/ second.
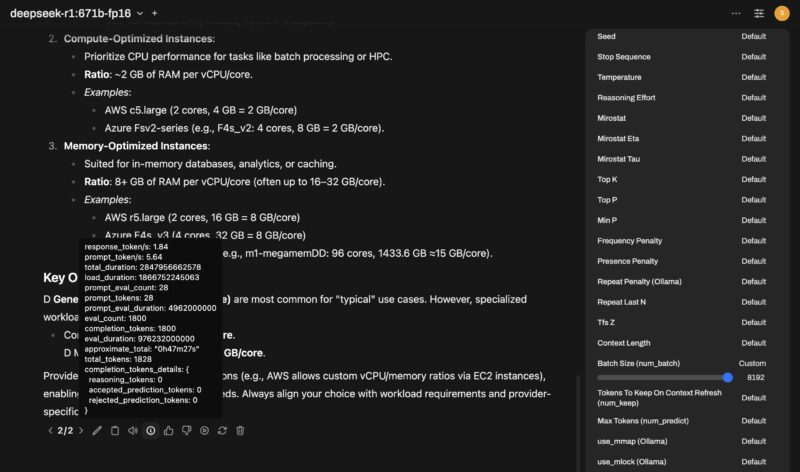
We were originally going to leave this as a completely using defaults guide, but altering the batch size and threads in the Open WebUI interface got us 33% better performance with ten seconds of settings changes. When we say the default is unoptimized, this is a great example of why.
If you are trying to run a virtualized cluster with AI inference running in the cluster, then freeing up cores from running at 100% is a wise goal, especially if you are not getting extra performance from them. There was clearly more we could do, so it was time to see what would happen if we then virtualized this setup.
We recreated this setup in a KVM virtual machine, and let it run. We only had around a 3-6% loss in performance. Companies like Microsoft can get the virtualization loss on HPC applications to be much lower on its AMD EPYC servers, but we are doing this in a largely untuned “easy” setup.
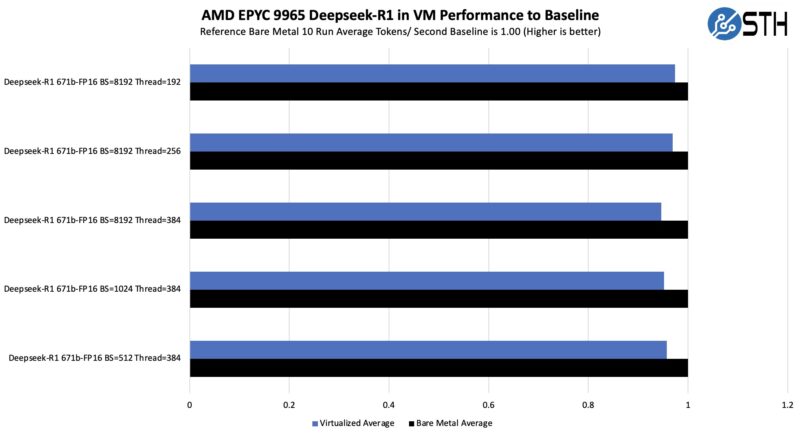
Another way to look at this is that we lost some performance, but the deltas in the test setups above were closer to run-to-run varianaces even over 10 runs of each. Still, you lose some performance by going virtualized, but to me that is very reasonable if it means you can run this alongside other applications.
Once we had that completed the next question was whether we could run VMs alongside the AI model. That turns the system from solely being an AI server to being a virtualization server also running big AI inference. If you have a virtualization cluster, perhaps that you just upgraded to these huge 192-core AMD EPYC 9965 chips, then there is a decent chance you have a few nodes with extra capacity.
The answer of running virtualized workloads alongside the Deepseek-R1 671B FP16 model was fairly messy. High memory bandwidth workloads like HPC applications ran poorly alongside the Deepseek-R1 model because both were contending for memory bandwidth. We had another class of services that worked well alongside the big AI application. Examples could be characterized as the low throughput VMs that need to be on in a business, but are not highly latency sensitive. Application VMs for things like workgroup web services, DHCP servers, and so forth that we fit in that leftover memory pool saw minimal impact to their performance and minimal impact to the AI model performance.
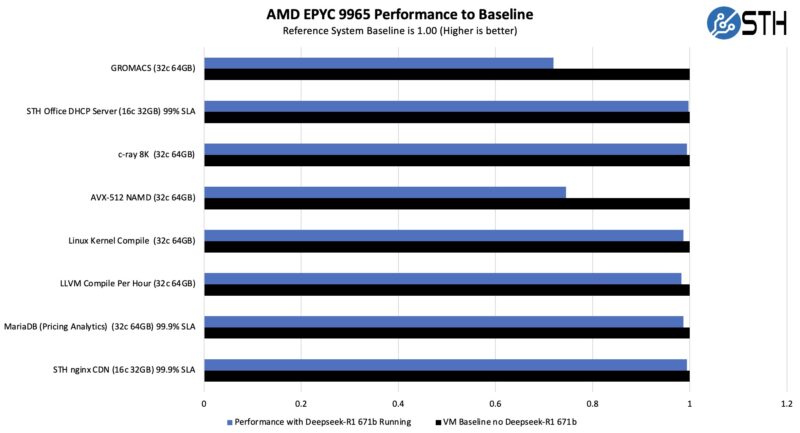
Perhaps the key takeaway here is that if you have a virtualization cluster, with the new CPUs like these AMD EPYC 9965 processors that have plenty of cores, memory bandwidth, and features like VNNI for AI inference, then you can run a large AI model alongside a few applications and get solid performance on both. This is not just an AI server, this is a virtualization host running a big AI model along with other applications. The key, however, is finding VMs to colocate that will not take huge amounts of memory bandwidth resources.
Something worth keeping in mind here is that CPU inference is not overly well-optimized at this point. Also, we are not doing a big project tuning the system for maximum performance from BIOS, to the OS, and into the AI inference software stack. Instead, we are just letting this run. Also, folks may wonder why we are doing this on the AMD EPYC 9965 versus using Intel AMX. We already covered Intel AMX and so the idea behind this setup was really what this would look like on the platform we can get the most virtualization server consolidation on. For that, the 192 core EPYC 9965 is the obvious choice because it has the most cores and threads we can get on a server CPU today. Especially with our 256 thread results, performance is better on the 128 core server CPUs, but then we have fewer cores for virtualized or containerized workloads other than for the AI inference workload.

Still, there were a few pitfalls we would recommend avoiding in this.



{kind=link}
With the stock market crash today, I’d wager that there’s lots of us who will only experience high-end AI like this….. at least in the near term
Excellence STH
I don’t think you’re grasping just how big this is. I wish AMD did AMX too, but I followed the same steps just running llama3.3 instead and it took exactly 4m 21s. Now I can say I’ve built an AI tool by using our ESXi virt cluster
count me in for the newly minted dozen vms with 70b models going head2head now
good work
Well done guys!
STH is and has been for a long time my absolute favourite Tech Site!
I love hardware so this is my cup of tea!
Run an FP8 on one CPU and its memory, that would have been interesting to see performance wise.
For a setup like this you one could use QEMU’s ability to map physical characteristics of the underlying CPU including L3, and to pass NUMA structure along. With this the OS in the VM will be able to make sensible decisions with thread placement.
This requires digging into QEMU’s commandline, which can be easily achieved with Proxmox’s VM configuration files (args:).
SMT needs to be correctly mapped by passing in the relevant SMP configuration: -smp 128,sockets=2,cores=64,threads=2,maxcpus=128
The above requires binding each vCPU to the host thread, and it has to be done after the VM starts up. For Proxmox the hookscript: directive can achieve this. Unfortunately it takes quite a bit of digging to get the exact QEMU process ids. Example scripts can be found on Proxmox’s forum.
Topology needs to be translated, together with host CPU physical bits and hugepages, while host should pass all of the relevant flags it needs to be verified in the VM (stuff like mitigations): -cpu host,phys-bits=0,topoext=on,+pdpe1gb
Unfortunately QEMU is not able to directly map NUMA to the guest. Even if presented with a single socket the underlying configuration might still utilize NUMA via NPS or SNC. For this it’s optimal to hard-reserve memory in each NUMA node and bind it to the range of CPUs, for example bind 128GB for first 16 vCPUs: -object memory-backend-ram,id=ram-node0,size=131072M,host-nodes=0,policy=bind,prealloc=on -numa node,nodeid=0,cpus=0-15,memdev=ram-node0
The above has to be repeated and adjusted to the host NUMA configuration. If using multiple sockets the distance between NUMA nodes also has to be specified once per direction: -numa dist,src=0,dst=1,val=11
It’s best to just use what numactl -H shows.
Sadly that’s a lot of manual tuning, which could be theoretically introduced into Proxmox or QEMU itself (but that is a really hard problem to get right for every configuration). There’s also further advanced tuning like moving interrupt handlers, kernel threads and other processes onto dedicated host CPUs that won’t be used by the VM, as to minimize cache thrashing from irrelevant (from the VM’s perspective) uses. QEMU IO threads should also be bound to the NUMA node containing underlying storage. If possible networking should be done with a NIC VF passed directly to the VM, also bound to VM NUMA configuration (via -device pxb for PCI birdge bound to VM NUMA node, and -device vfio-pci for the NIC VF attached to said pxb device).
With this I was able to achieve ~ 95% performance for running huge LLMs in a VM at the price of the VM having a rigid configuration, as scaling resources isn’t trivial and requires recalculating parameters.
Hope this wall of text can be useful for someone to tinker with, or even a more advanced STH article :)
1.9 token/s? Why bother…
DeepSeek is natively trained at 8 bit, 16 or 32 bit versions of the model are just for compatibility in case you accelerator/tools only support that format.By doing so in this case you just waste half the RAM capacity and memory bandwidth for no gain in quality like a natively fp16 trained model would have
I really appreciate the “all CPU” approach, but it’s possible to use LM Studio, FlexLLMGen and Genv with a single consumer graphics card; like a 5090, to get much faster performance.
I’d go with one CPU and 12x96GB RDIMMs (holds 8bit model) or the 12x128GB (holds the 16 bit model) if you can afford it. Dual CPUs slow down a fundamentally sequential inferencing process substantially. Using a relatively small 48GB GPU for kv cache / context buffers and letting the CPU and RAM handle the model layers should improve performance a bit.