
When it comes to the new Intel Xeon Scalable Processor Family SKUs, the Xeon Platinum 8180 is top dog at the moment. Its 205W TDP can be too much for some dense air-cooled configurations so Intel has another 28 core, 38.5MB L3 cache behemoth that sits one notch below the 8180 in the SKU stack, the Intel Xeon Platinum 8176. The Intel Xeon Platinum 8176 has the same maximum turbo clock yet a lower base clock in exchange for a 165W TDP. We already published our initial Quad Intel Xeon Platinum 8180 benchmarks, so we now wanted to publish one notch below and show the biggest difference.
Before delving into performance numbers, we wanted to show a chart that explains the difference between the chips more succinctly. The two chips both have 3.8GHz max turbo speeds with the 8180 having a base clock of 2.5GHz while the 8176 has a base clock of 2.1GHz.
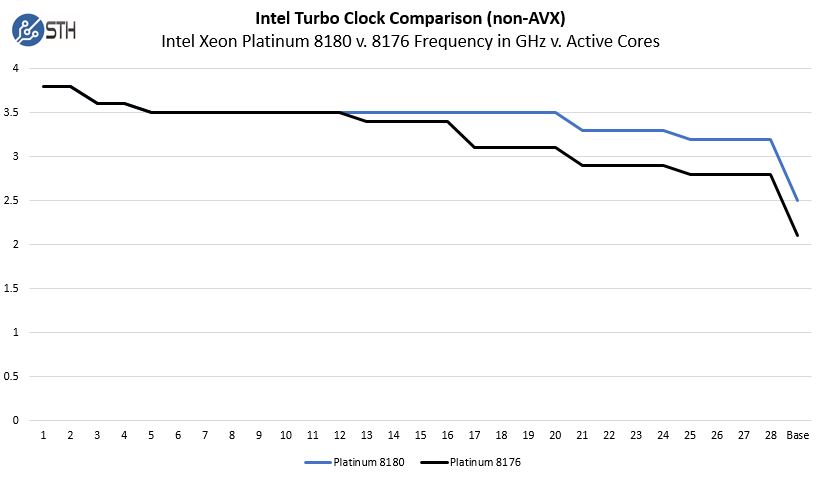
We are using non-AVX turbo numbers since those are most relevant for our figures below. Where you see the real value on the Intel Xeon Platinum 8180 side is in the AVX cocks where that TDP differential helps significantly. Here is an example of a similar chart where we add the AVX-512 Turbo clocks by active cores:
While in non-AVX workloads the Intel Xeon Platinum 8180 and 8176 are similar up to 12 cores, with AVX-512 they only stay equal up to 4 cores. That may not seem like a lot, but for the AVX-512 workloads across all 28 cores, one gets over 30% more base clock frequency and 21% more max turbo frequency. It is also the reason we were slightly surprised to not see an 8180F on the launch SKU list with Omni-Path for the HPC segment. The 8176F is the top bin Omni-Path Fabric SKU.
We have had some questions generated via our Intel Xeon Scalable Processor Family value analysis as to why there is a $1300 premium on the top end 8180 SKU over the 8176 SKU. We suspect the driver is largely found in these AVX performance figures. Our initial benchmark set was designed to provide comparable data from CPUs since 2012 so we are not taking advantage of AVX-512 in the below dataset. We do have new benchmarks with applications like GROMACS and Tensorflow that utilize AVX-512. As we get a larger data set, we will be publishing on STH.
Test Configuration
Our test configuration used an Intel platform.
- CPU(s): 4x Intel Xeon Platinum 8176 28 core/ 56 thread CPUs (112 cores/ 224 threads total) with 2.1GHz base and 3.7GHz turbo clocks, 38.5MB L3 cache each
- Platform: Intel S4PR1SY2B
- RAM: 768GB in 24x SK.Hynix 32GB DDR4-2666 2RX4 DIMMs
- OS SSD(s): 1x Intel DC S3700 400GB
- OSes: Ubuntu 14.04 LTS, Ubuntu 17.04, CentOS 7.2
This is the platform that Intel sent us for review. For those wondering, the max power we saw on this system was 1126W on our 208V lab racks. That is quite a bit lower than the 8180 system which may have to do with the additional power for cooling the 8180’s not being a linear draw.

The numbers we have should be comparable to what you will see with a quad Intel Xeon Platinum 8176M and Platinum 8176F setup as the clock speeds are the same.
Quad Intel Xeon Platinum 8176 Benchmarks
For our testing, we are using Linux-Bench scripts which help us see cross platform “least common denominator” results. We are using gcc due to its ubiquity as a default compiler. One can see details of each benchmark here. We are already testing the next-generation Linux-Bench that can be driven via Docker and uses newer kernels to support newer hardware. The next generation benchmark suite also has an expanded benchmark set that we are running regressions on. For now, we are using the legacy version that now has over 100,000 test runs under its belt.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read.
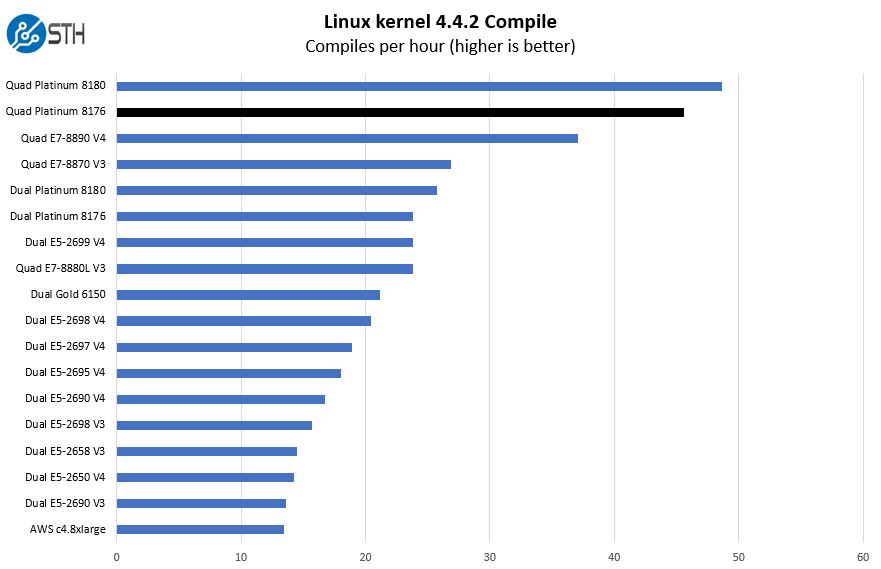
As you can see, the Intel Xeon Platinum 8176 sits slightly below the Intel Xeon Platinum 8180 in terms of performance. Here you can see that we achieved slightly better than expected performance. Also, if you are running a two generation old quad Intel Xeon E7-8800 series system then the new quad Platinum systems may make a lot of sense if you are looking to consolidate.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads.
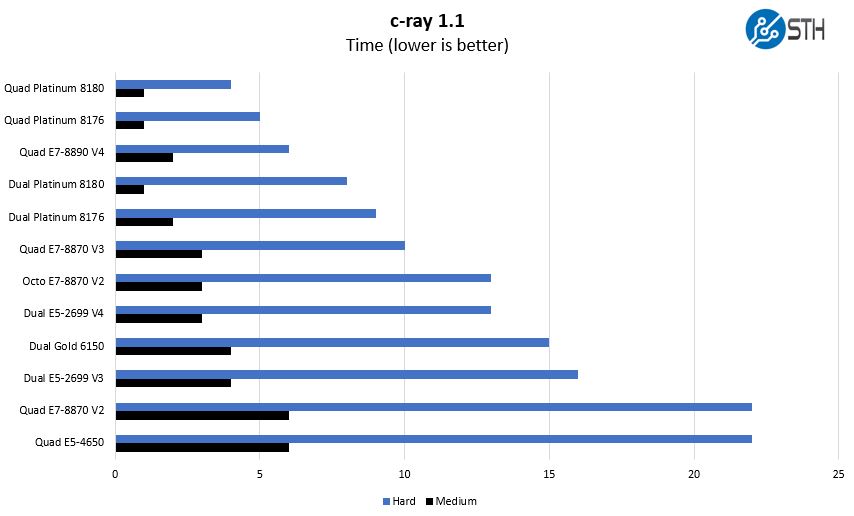
One can clearly see the benefit of having higher TDP and turbo clocks. We do have to heat soak these chips before running c-ray. For smaller CPUs, e.g. the Xeon E3 or Denverton parts, our tests take long enough to heat soak the CPUs. With these large systems, we have to heat soak the chips before running our benchmarks to see more real-world performance numbers.
We needed to add an 8K resolution benchmark. We have that one tested on most CPUs in our lab so it is likely that you will start seeing those results added by the time we get into dual processor stacks.
This is not an AVX-512 workload, however, the overall, performance is very good. On the other hand, this is the type of application where AMD EPYC architecture excels as it is a near perfect match for Zen architecture.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
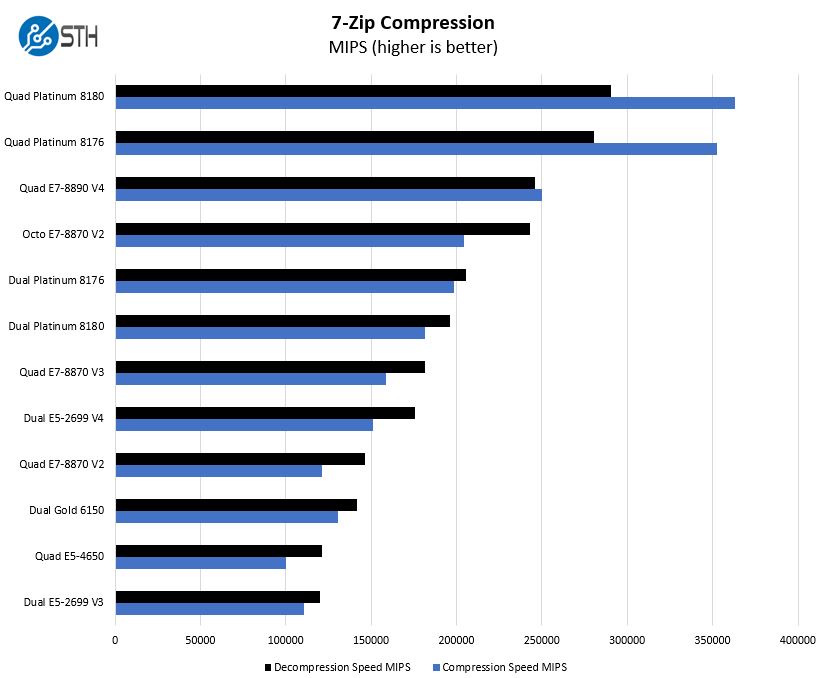
This is an area where we are seeing the impacts of increased core counts plus IPC gains. We should note that if you have an Intel Lewisburg PCH with QuickAssist, you can get 100Gbps worth of compression offload. We have not been able to test the new generation of QuickAssist, however, we expect that if you workloads are compression heavy, that will be an extremely attractive option, even more so than the 40Gbps version we tested in 2016. In theory, one can use more than one PCH per system as well.
NAMD Performance
NAMD is a molecular modeling benchmark developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. More information on the benchmark can be found here. We are going to augment this with GROMACS in the next-generation Linux-Bench and are building a dataset of those results for future publication.
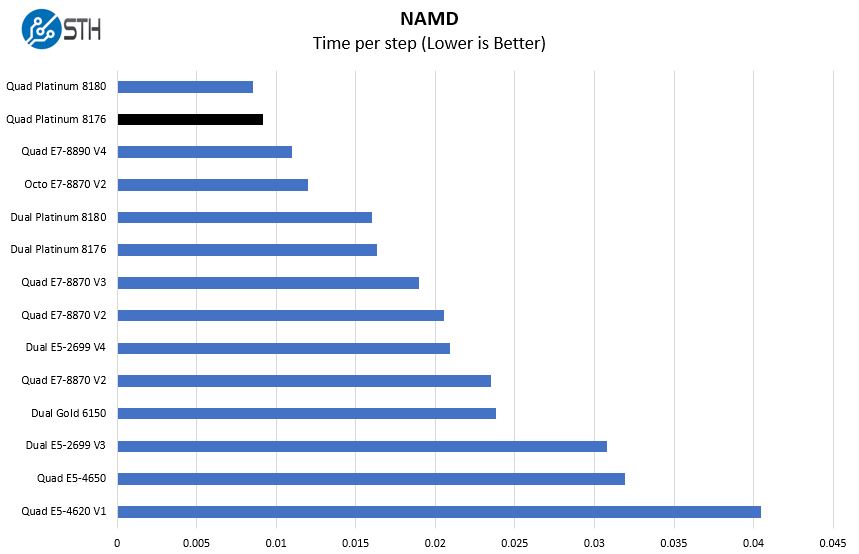
Here you can see the Intel Xeon Platinum 8176 perform about in line with expectations. Again, we are not using AVX-512 here which is where the CPUs will obliterate the Xeon E7-8890 V4 setup.
Sysbench CPU test
Sysbench is another one of those widely used Linux benchmarks. We specifically are using the CPU test, not the OLTP test that we use for some storage testing.
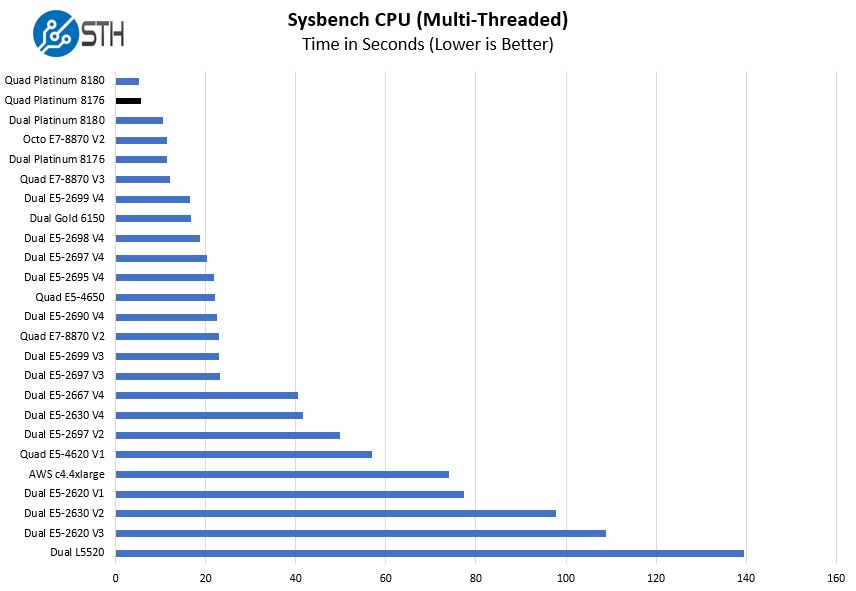
This is raw comptue power so we see the two quad Intel Xeon Platinum 28-core CPU systems perform very close to one another. This is another test where performance has improved to the point that an Intel Xeon E7 V2 generation eight socket system is no match for a three generation system with half as many CPUs. In fact, it is no match for even two Intel Xeon Platinum 8176 CPUs.
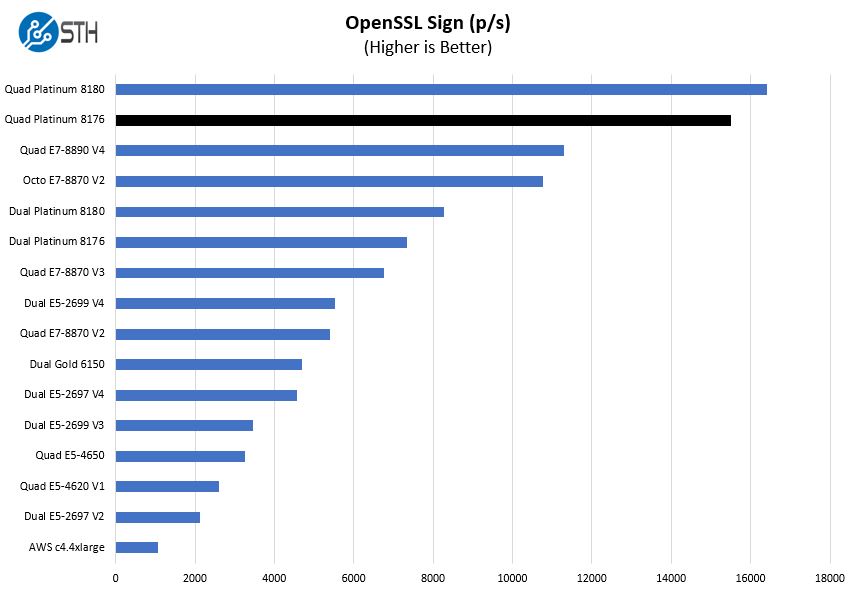
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
Here are the verify results:
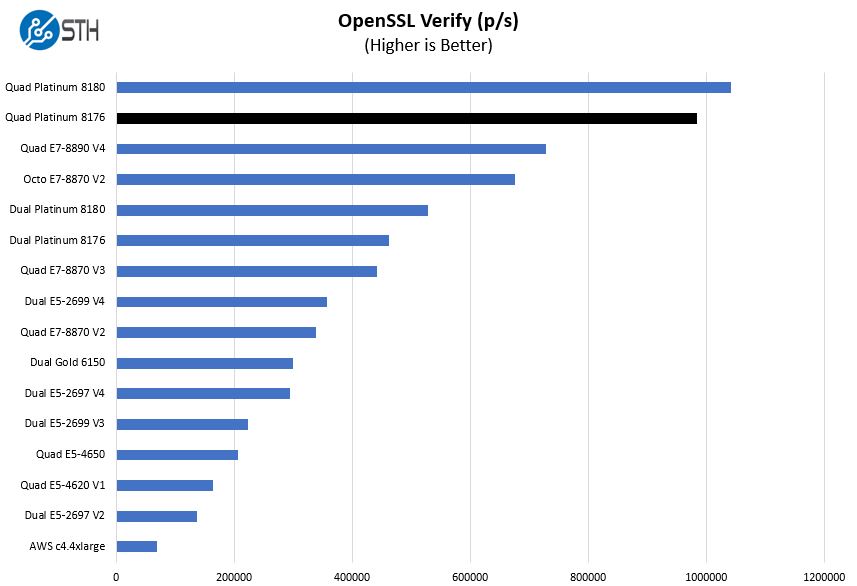
Although at first blush this may not look overly impressive. Remember this is essentially the prior generation’s top end launch SKU, the Intel Xeon E7-8890 V4 versus the number two SKU one generation later. Even though it is not the top end SKU anymore, with only around 17% more cores (28 v. 24) Skylake-SP is getting about 37% more performance out of the Quad Intel Xeon Platinum 8176 generation.
Some of Intel’s Lewisburg PCH options have support for QuickAssist up to 100Gbps for OpenSSL. We tested the older Coleto Creek 40Gbps QuickAssist with OpenSSL and saw some awesome offload performance.
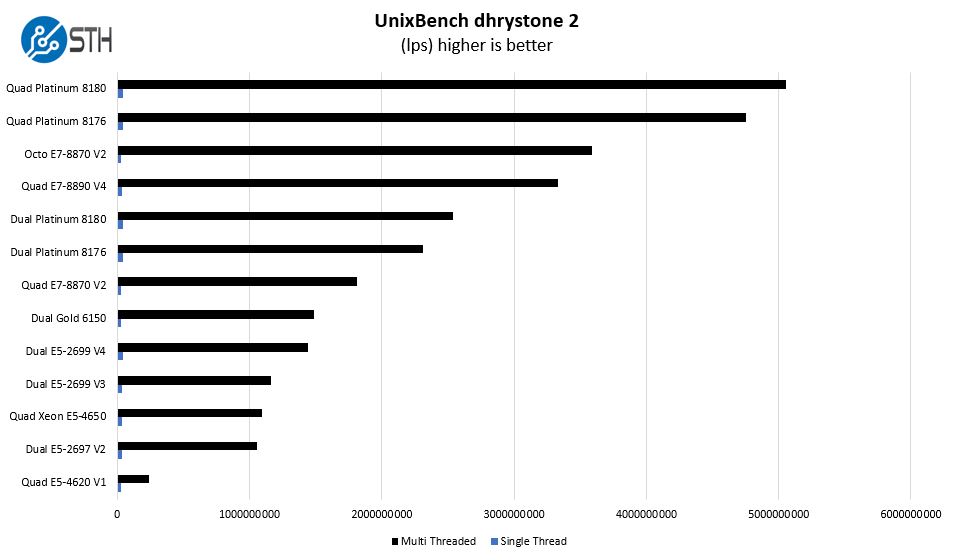
UnixBench Dhrystone 2 and Whetstone Benchmarks
One of our longest running tests is the venerable UnixBench 5.1.3 Dhrystone 2 and Whetstone results. They are certainly aging, however, we constantly get requests for them, and many angry notes when we leave them out. UnixBench is widely used so it is a good comparison point.
Here are the whetstone results:
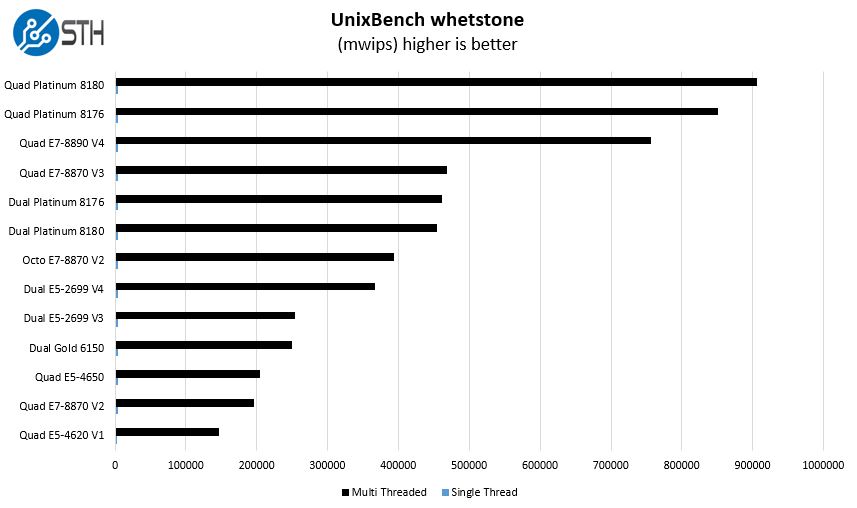
Again, we see that as we move past 200 threads in a single system the single threaded results are essentially unreadable. That is the point. Although these CPUs have solid single core turbo boost speeds, if you have a quad socket system they are expected to be loaded to a much higher degree. A single thread in a 224 thread system is under 0.5% or better known as a blip in overall utilization.
Single Redis Instance Benchmarks
We unleash a single Redis instance for these benchmarks and generate set/ get requests against the instance. This is more of a frequency plus memory bandwidth bound workload rather than a CPU speed bound result.
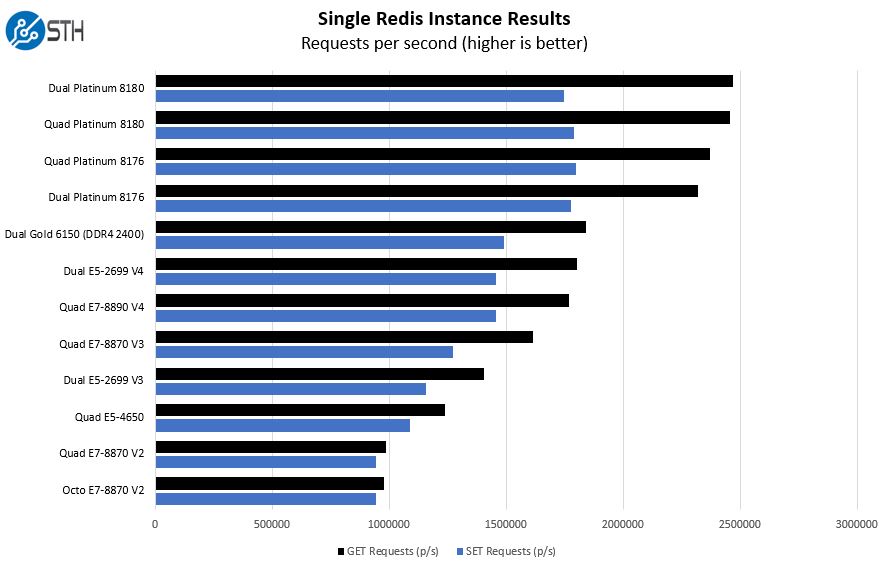
Here you can see that with a single instance there is relatively little separation between the two CPUs. This is due to the lighter loading of CPUs where we expect the non-AVX turbo frequencies to keep the CPUs relatively close in performance. You can also see a nice generational impact moving to the higher speed DDR4-2666 memory, and the newer microarchitecture.
Final Words
If you simply look at the Turbo clock speeds you may think that the Intel Xeon Platinum 8176 and 8180 are very similar. Indeed, in non-AVX workloads up to 12 cores they are. When the core counts are dialed up, the Intel Xeon Platinum 8180 shows why it commands a premium. In the near future, we are going to have several other performance data points on some of the larger applications we test with AVX-512 that will make this contrast even starker. The above should provide at least a relative sense of performance on Intel’s second-in line and top integrated Omni-Path fabric 4-socket Skylake-SP configuration can do.
You can read more about the new chips at our Intel Xeon Scalable Processor Family launch coverage headquarters.



{kind=link}
Thanks for the update to the initial review. You have done a solid job of reviewing these parts and putting the performance into context. I’m happy to see there’s at least one website out there that will actually try to use some modern workloads to help illustrate why these chips were made in the first place since Intel didn’t spend all this time and money to make a Cinebench system :-P