NVIDIA RTX A4500 20GB GPU Performance
Something we are doing at STH is rebuilding our GPU test suite. William did our GPU reviews and benchmarks for years, and we had pages and pages of charts. As the GPU vendors look to release next-generation products, we have started on the new STH GPU benchmark suite. As always, we will focus more on GPU compute rather than gaming performance. That also means back-testing a number of options to serve as baselines for the next generations of GPUs. This is just one of the reviews that are stuck in the middle of those two eras. We are using our order benchmark suite here to allow you to compare to older cards as well.
Redshift v3.0.31
Redshift is a GPU-accelerated renderer with production quality. A Demo version of this benchmark can be found here.
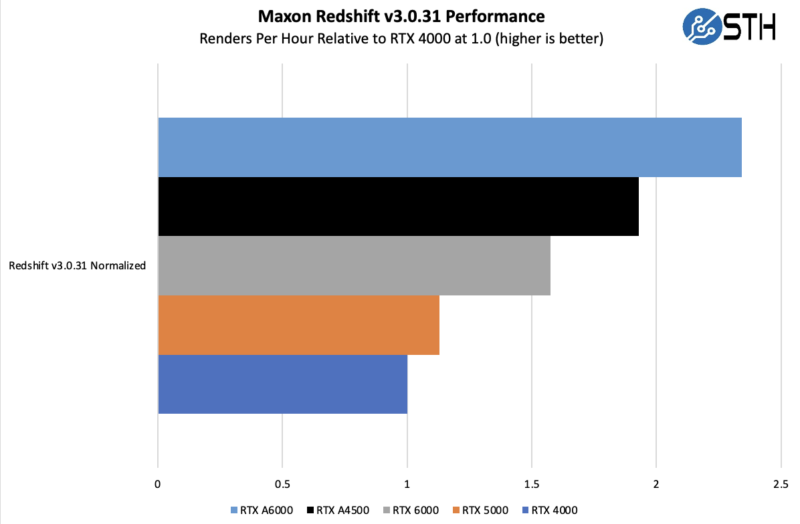
Performance on the A4500 is very good here. We can see that it easily eclipses the previous generation of cards.
ResNet-50 Inferencing in TensorRT using Tensor Cores
ImageNet is an image classification database launched in 2007 and designed for use in visual object recognition research. Organized by the WordNet hierarchy, hundreds of image examples represent each node (or category of specific nouns).
Note, we are going to be updating this in the next-generation of card reviews.
In our benchmarks for Inferencing, a ResNet50 Model trained in Caffe will be run using the command line as follows.
nvidia-docker run --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -v ~/Downloads/models/:/models -w /opt/tensorrt/bin nvcr.io/nvidia/tensorrt:20.11-py3 trtexec --deploy=/models/ResNet-50-deploy.prototxt --model=/models/ResNet-50-model.caffemodel --output=prob --batch=16 --iterations=500 --fp16
Options are:
–deploy: Path to the Caffe deploy (.prototxt) file used for training the model
–model: Path to the model (.caffemodel)
–output: Output blob name
–batch: Batch size to use for inferencing
–iterations: The number of iterations to run
–int8: Use INT8 precision
–fp16: Use FP16 precision (for Volta or Turing GPUs), no specification will equal FP32
We can change the batch size to 16, 32, 64, 128 and precision to INT8, FP16, and FP32.
The results are Inference Latency (in sec).
If we take the batch size / Latency, that will equal the Throughput (images/sec) which we plot on our charts.
We also found that this benchmark does not use two GPUs; it only runs on a single GPU.
You can, however, run different instances on each GPU using commands like.
“`NV_GPUS=0 nvidia-docker run … &
NV_GPUS=1 nvidia-docker run … &“`
With these commands, a user can scale workloads across many GPUs.
Also one can use the —device=0,1,2,3,4,… a command to select which GPU to run on, more on this later.
We start with INT8, FP16, and FP32 modes. We are also only going to show data for the largest batch sizes that we previously tested.
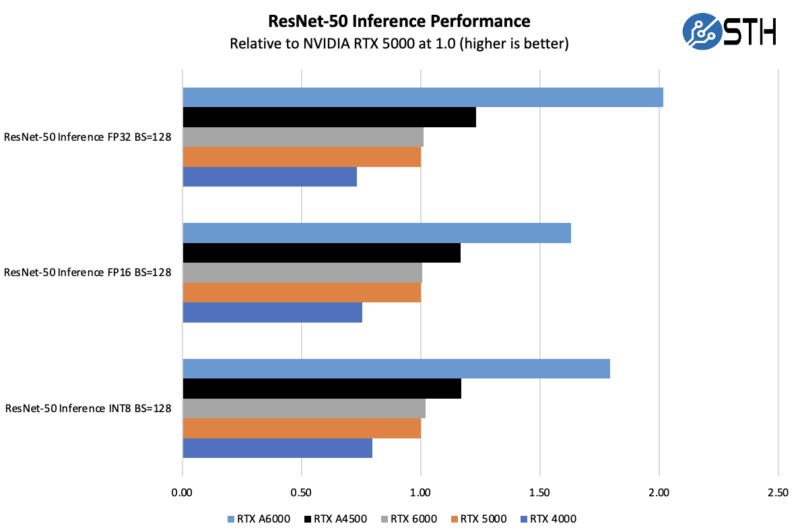
Here we can see a huge generational leap in performance with the A4500 over the older Turing generation RTX 5000 and RTX 6000. At the same time, the massive 48GB NVIDIA RTX A6000 clearly shines here, and that is a trend we will see.
ResNet-50 Training, using Tensor Cores
We also wanted to train the venerable ResNet-50 using Tensorflow. During training, the neural network is learning features of images (e.g., objects, animals, etc.) and determines what features are important. Periodically (every 1000 iterations), the neural network will test itself against the test set to determine training loss, which affects the accuracy of training the network. Accuracy can be increased through repetition (or running a higher number of epochs.)
The command line we will use is.
nvidia-docker run --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v ~/Downloads/imagenet12tf:/imagenet --rm -w /workspace/nvidia-examples/cnn/ nvcr.io/nvidia/tensorflow:20.11-tf2-py3 python resnet.py --data_dir=/imagenet --batch_size=128 --iter_unit=batch --num_iter=500 --display_every=20 --precision=fp16
Parameters for resnet.py:
–layers: The number of neural network layers to use, i.e. 50.
–batch_size or -b: The number of ImageNet sample images to use for training the network per iteration. Increasing the batch size will typically increase training performance.
–iter_unit or -u: Specify whether to run batches or epochs.
–num_iter or -i: The number of batches or iterations to run, i.e. 500.
–display_every: How frequently training performance will be displayed, i.e. every 20 batches.
–precision: Specify FP32 or FP16 precision, which also enables TensorCore math for Volta, Turing and AmpereGPUs.
While this script TensorFlow cannot specify individual GPUs to use, they can be specified by
setting export CUDA_VISIBLE_DEVICES= separated by commas (i.e. 0,1,2,3) within the Docker container workspace.
We will run batch sizes of 16, 32, 64, 128, and change from FP16 to FP32.
Some lower-end GPUs cannot show all of these batch sizes. An example of this is the NVIDIA RTX 4000 using FP32 because that uses too much memory.
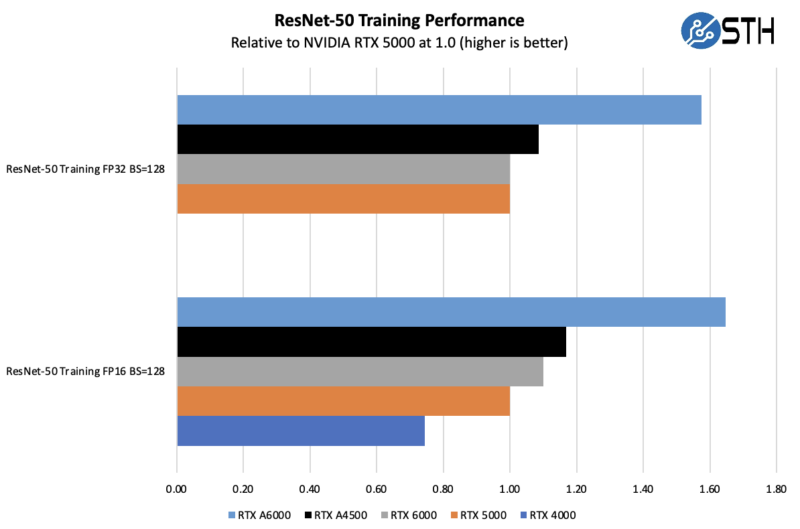
Here we can see that the older RTX 4000 could not run this using FP32 and the larger 128 batch size because it only has 8GB of memory onboard. For those purchasing between a RTX 4000 and a RTX 5000 in the previous generation, the A4500 is a clear winner.
Training using OpenSeq2Seq (GNMT)
While Resnet-50 is a Convolutional Neural Network (CNN) that is typically used for image classification, Recurrent Neural Networks (RNN) such as Google Neural Machine Translation (GNMT) are used for applications such as real-time language translations.
The command line we use for OpenSeq2Seq (GNMT) is as follows.
nvidia-docker run -it --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v ~/Downloads/OpenSeq2Seq/wmt16_de_en:/opt/tensorflow/nvidia-examples/OpenSeq2Seq/wmt16_de_en -w /workspace/nvidia-examples/OpenSeq2Seq/ nvcr.io/nvidia/tensorflow:20.11-tf2-py3
We then open the en_de_gnmt-like-4GPUs.py and edit our variables.
vi example_configs/text2text/en-de/en-de-gnmt-like-4GPUs.py
First, edit data_root to point to the below path:
data_root = “/opt/tensorflow/nvidia-examples/OpenSeq2Seq/wmt16_de_en/”
Additionally, edit the num_gpus, max_steps, and batch_size_per_gpu parameters under
base_prams to set the number of GPUs, run a lower number of steps (i.e. 500) for
benchmarking, and also to set the batch size:
base_params = {
...
"num_gpus": 1,
"max_steps": 500,
"batch_size_per_gpu": 128,
...
},
Also, edit lines 44 and below as shown to enable FP16 precision:
#”dtype”: tf.float32, # to enable mixed precision, comment this
line and uncomment two below lines
“dtype”: “mixed”,
“loss_scaling”: “Backoff”,
We then run the benchmarks as follows.
python run.py –config_file example_configs/text2text/en-de/en-de-gnmt-like-4GPUs.py –mode train
The results will be Avg. Objects per second trained which we plot.
We should note that the NVIDIA Quadro RTX 4000 was unable to run at these batch sizes so it does not have a score.
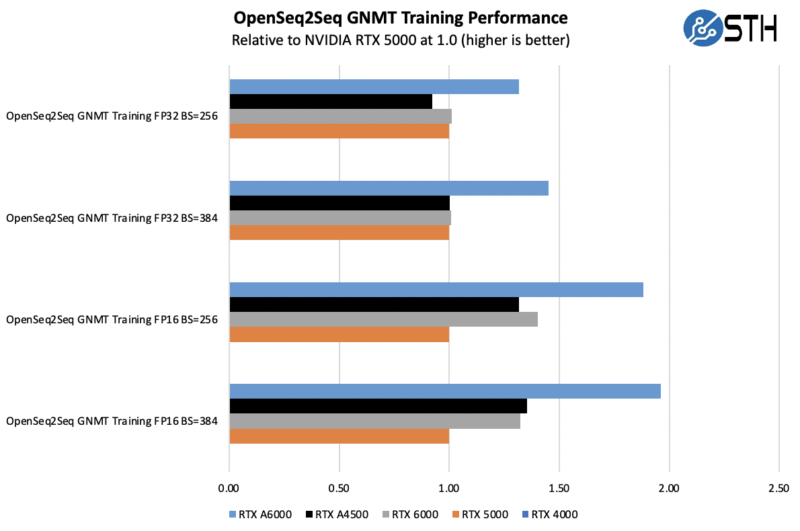
Here again, we see generally great performance from the RTX A4500, this time generally between the RTX 5000 and RTX 6000 or even ahead of the RTX 6000. That was an interesting result that we were not necessarily expecting. The RTX A6000 remains dominant, but we should also remember that is roughly 3x the price.
Next, let us discuss the market for these cards.



{kind=link}
This is the configuration 3080 Ti should have been.
Thank God. Ai performance
So what’s the market for the RTX A5000? Realistically, and more importantly when it comes to price to performance, the A5500 makes more sense it’s got loads more CUDA cores and cost less than half an A6000 with 24GB of VRAM.
Any reason Specviewperf benchmarks weren’t done like in previous RTX reviews?
Thanks STH for ML benches