
Packet has a really cool cloud model. They are well-known for adopting new platforms well before they are generally available in larger clouds. A few examples include handling Arm server development nodes for the WorksOnArm project. The company is also one of the first to adopt AMD EPYC for their cloud hosting that we covered in our piece Packet’s Dell EMC PowerEdge AMD EPYC Server Deployment Accelerating. One of the datacenters STH uses for its server reviews including the recent Gigabyte G481-S80 8x NVIDIA Tesla GPU Server Review also hosts Packet’s expanding Silicon Valley location. Although Packet is generally a leader, one area that the company has been slower to adopt has been GPU compute nodes. That is changing and changing with a twist. Packet is offering new GPU nodes starting with $0.00 per hour pricing.
Packet’s Foray into GPU Compute
Packet is not crazy. It has a large enough user base, a solid platform, and it knows that people are GPU hungry. The $0.00 per hour pricing is in many ways a(n effective) marketing gimmick. It is allowing a spot market to dictate pricing. That is an extremely interesting model and one that we hope works.
The one disadvantage to the spot market for these is that if you are in the middle of training and you are not priced high enough, you can lose many hours of work. That is an effective driver toward increasing prices in a spot only market. Packet says it is also looking at a timeshare model that allows instances to be reserved for hours at a time.
Perhaps one of the more interesting aspects of the company’s blog post on this subject was discussing pricing for new hardware. They used examples including the Graphcore IPU and Mellanox Bluefield SoCs when discussing the challenges of pricing new hardware. Packet has the infrastructure in place to handle smaller test installations of many varied hardware platforms. If this is a precursor to Graphcore IPU on the Packet cloud, it is extremely exciting.
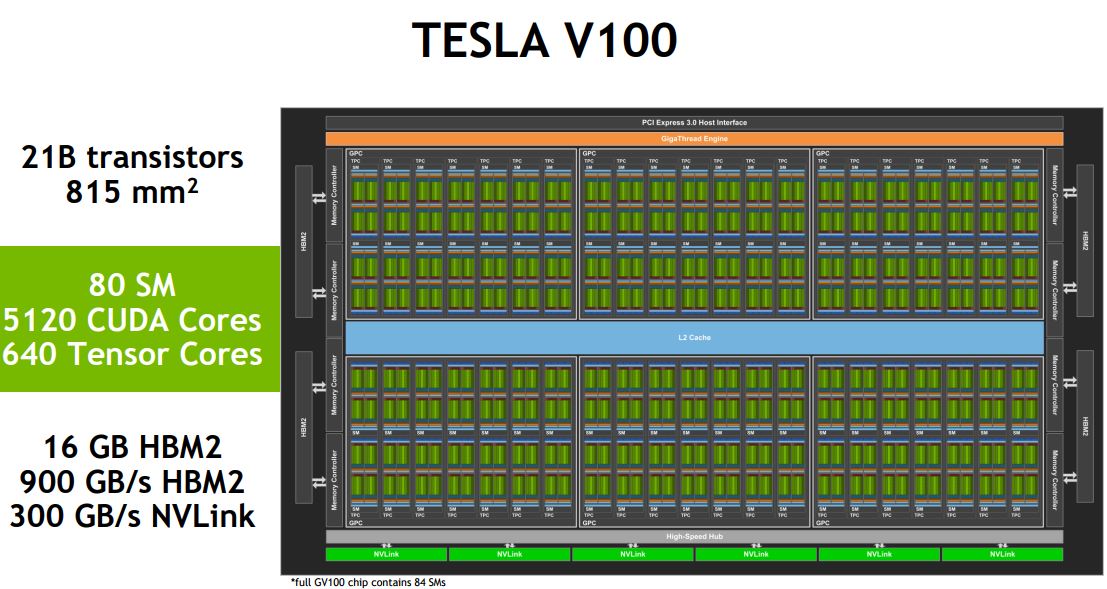
Packet’s GPU Server Specs
Inference Server – x2.xlarge
Execution of models, neural nets and matching engines.
- Dual Xeon 5120
- 384GB RAM
- 2 x 120GB SSD boot
- 1 x 3.2TB NVMe
- 1x Nvidia P4 GPU
- 2 x 10Gbps NICs
Training Server – g2.large
Training/modeling – DNN and CNN training.
- Dual Xeon 6126 (2x 12C/24T 2.6Ghz)
- 192GB RAM
- 2 x 120GB SSD boot
- 2 x 480GB SSD
- 2 x Nvidia V100 32GB GPU w/NVLINK
- 2 x 10Gbps NICs
As noted in their article, Packet’s Tesla V100 pricing is extremely good. It is below what many of NVIDIA’s system integrator partners pay from NVIDIA for the 32GB cards.



{kind=link}