NVIDIA Quadro RTX 4000 Deep Learning benchmarks
As we continue to innovate on our review format, we are now adding deep learning benchmarks. In future reviews, we will add more results to this data set. At this point, we have a fairly nice data set to work with.
ResNet-50 Inferencing in TensorRT using Tensor Cores
ImageNet is an image classification database launched in 2007 designed for use in visual object recognition research. Organized by the WordNet hierarchy, hundreds of image examples represent each node (or category of specific nouns).
In our benchmarks for Inferencing, a ResNet50 Model trained in Caffe will be run using the command line as follows.
nvidia-docker run --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 --rm -v ~/Downloads/models/:/models -w /opt/tensorrt/bin nvcr.io/nvidia/tensorrt:18.11-py3 giexec --deploy=/models/ResNet-50-deploy.prototxt --model=/models/ResNet-50-model.caffemodel --output=prob --batch=16 --iterations=500 --fp16
Options are:
–deploy: Path to the Caffe deploy (.prototxt) file used for training the model
–model: Path to the model (.caffemodel)
–output: Output blob name
–batch: Batch size to use for inferencing
–iterations: The number of iterations to run
–int8: Use INT8 precision
–fp16: Use FP16 precision (for Volta or Turing GPUs), no specification will equal FP32
We can change the batch size to 16, 32, 64, 128 and precision to INT8, FP16, and FP32.
The results are in inference latency (in seconds.) If we take the batch size / Latency, that will equal the Throughput (images/sec) which we plot on our charts.
We also found that this benchmark does not use two GPU’s; it only runs on a single GPU. You can, however, run different instances on each GPU using commands like.
```NV_GPUS=0 nvidia-docker run ... &
NV_GPUS=1 nvidia-docker run ... &```
With these commands, a user can scale workloads across many GPU’s. Our graphs show combined totals.
We start with Turing’s new INT8 mode which is one of the benefits of using the NVIDIA RTX cards.
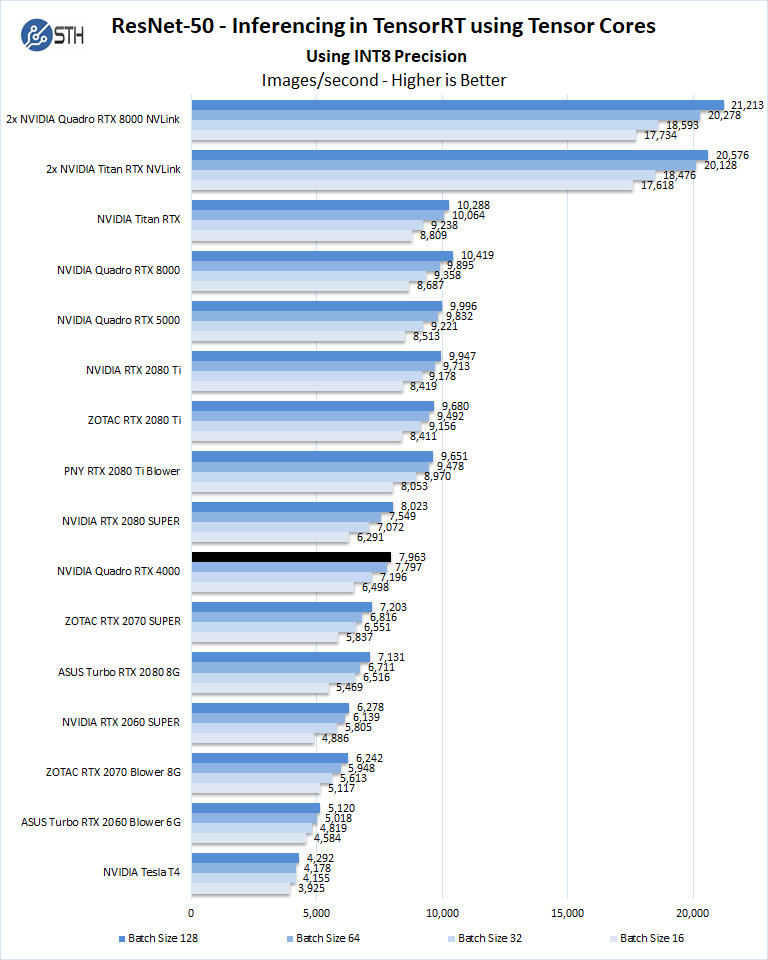
NVIDIA Quadro RTX 4000 ResNet Inferencing INT8Using the precision of INT8 is by far the fastest inferencing method if at all possible, converting code to INT8 will yield faster runs. Installed memory has one of the most significant impacts on these benchmarks. Inferencing on NVIDIA RTX graphics cards does not tax the GPU’s to a great deal. However, additional memory allows for larger batch sizes.
Inferencing on NVIDIA RTX graphics cards does not tax the GPUs a great deal, however additional memory allows for larger batch sizes.
Let us look at FP16 and FP32 results.
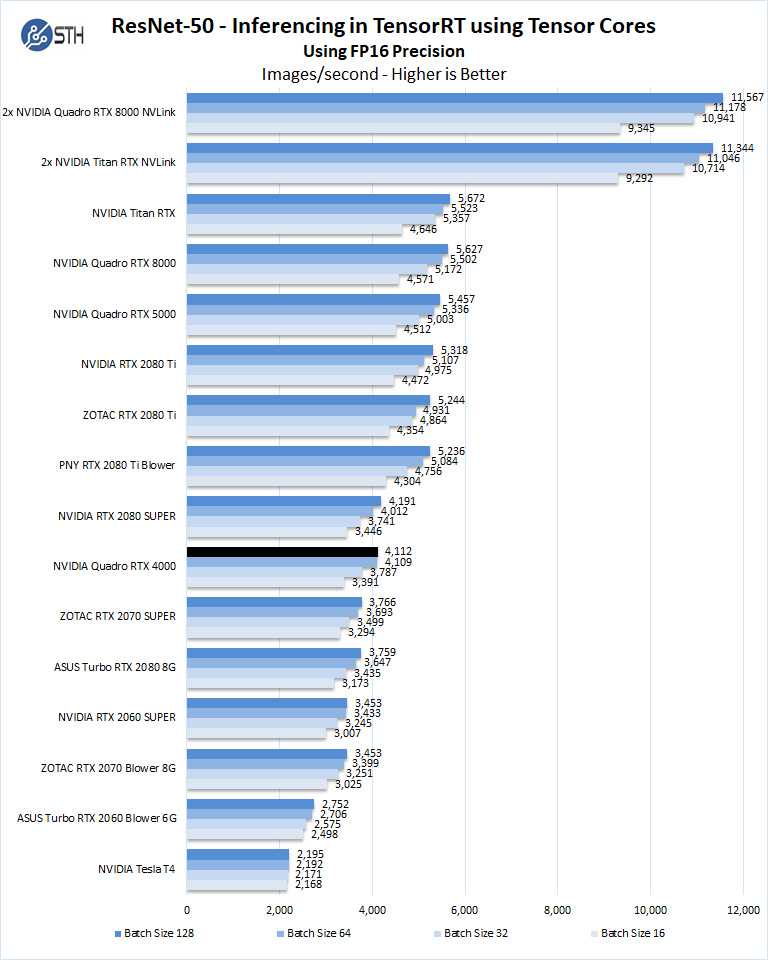
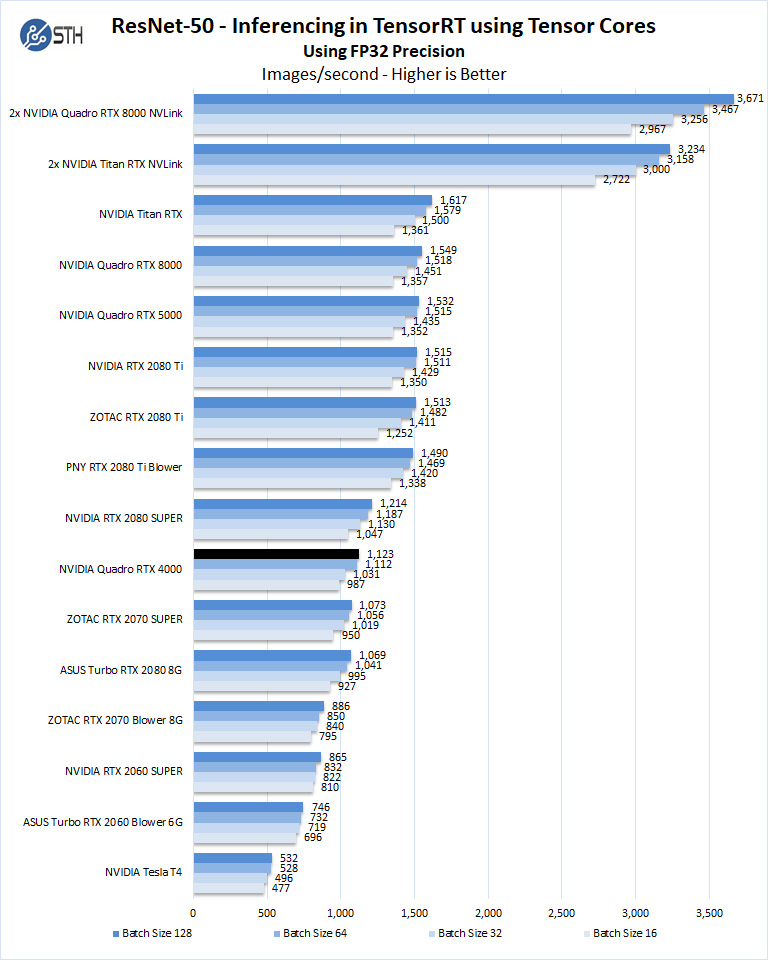
Here we see performance quite a bit better than both the NVIDIA GeForce RTX 2070 super. Perhaps more interesting is that with the extra power headroom, and the larger form factor, the NVIDIA Quadro RTX 4000 performs quite a bit better than the more expensive NVIDIA T4.
This intuitively makes sense. NVIDIA is working with content creation software providers such as Adobe to accelerate workflows of tools such as Adobe Sensei that use AI to greatly speed up certain tasks. For many professional users, having great AI inferencing performance will directly impact daily content creation workflows.
Training with ResNet-50 using Tensorflow
We also wanted to train the venerable ResNet-50 using Tensorflow. During training the neural network is learning features of images, (e.g. objects, animals, etc.) and determining what features are important. Periodically (every 1000 iterations), the neural network will test itself against the test set to determine training loss, which affects the accuracy of training the network. Accuracy can be increased through repetition (or running a higher number of epochs.)
The command line we will use is:
nvidia-docker run --shm-size=1g --ipc=host --ulimit memlock=-1 --ulimit stack=67108864 -v ~/Downloads/imagenet12tf:/imagenet --rm -w /workspace/nvidia-examples/cnn/ nvcr.io/nvidia/tensorflow:18.11-py3 python resnet.py --data_dir=/imagenet --layers=50 --batch_size=128 --iter_unit=batch --num_iter=500 --display_every=20 --precision=fp16
Parameters for resnet.py:
–layers: The number of neural network layers to use, i.e. 50.
–batch_size or -b: The number of ImageNet sample images to use for training the network per iteration. Increasing the batch size will typically increase training performance.
–iter_unit or -u: Specify whether to run batches or epochs.
–num_iter or -i: The number of batches or iterations to run, i.e. 500.
–display_every: How frequently training performance will be displayed, i.e. every 20 batches.
–precision: Specify FP32 or FP16 precision, which also enables TensorCore math for Volta and Turing GPUs.
While this script TensorFlow cannot specify individual GPUs to use, they can be specified by
setting export CUDA_VISIBLE_DEVICES= separated by commas (i.e. 0,1,2,3) within the Docker container workspace.
We will run batch sizes of 16, 32, 64, 128 and change from FP16 to FP32. Our graphs show combined totals.
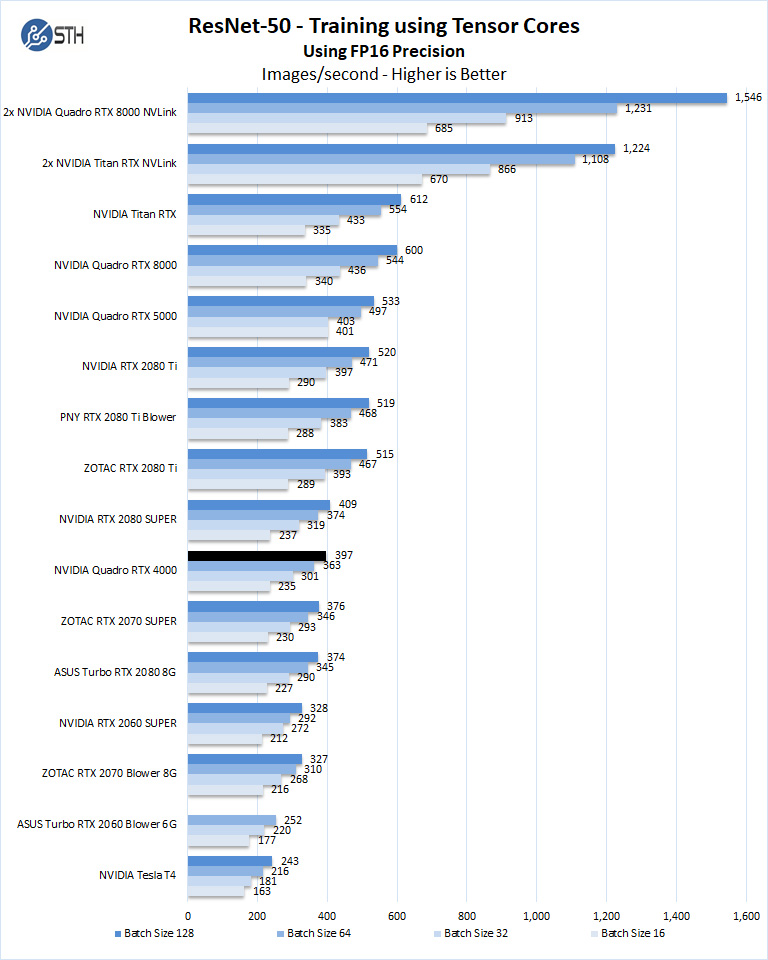
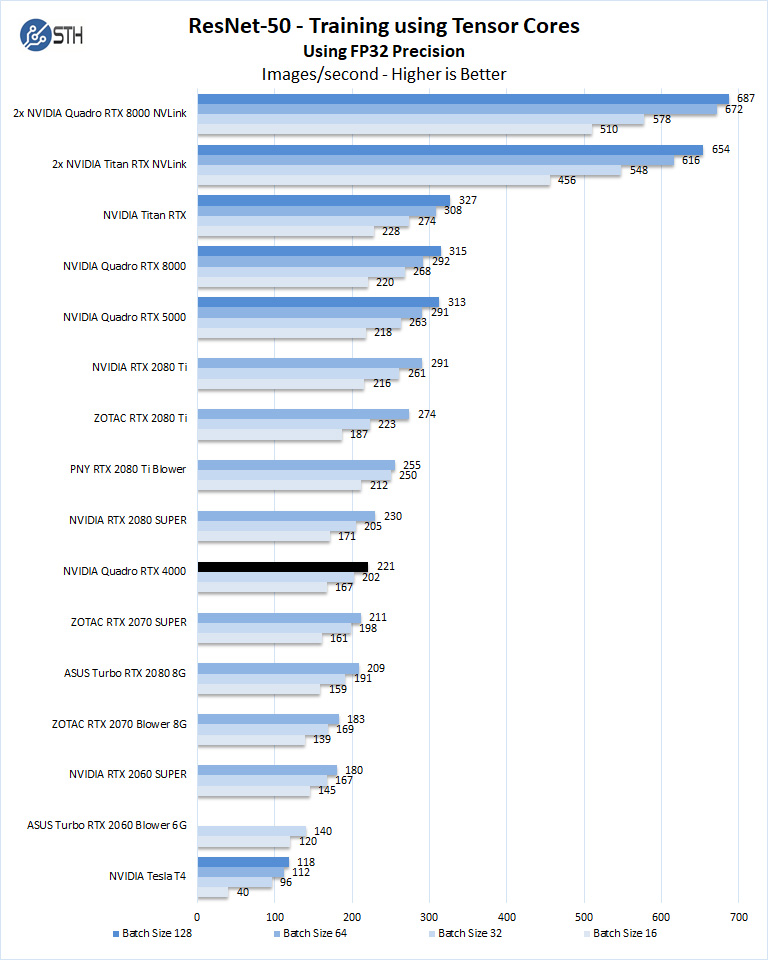
After the NVIDIA T4 review that we did (called Tesla T4 at the time) and is linked above, we discussed how the RTX 2070 (Super) may be a better value for some looking for lower-cost training and inferencing. The Quadro RTX 4000 is perhaps that next-level of intriguing since it offers a single-slot design. While not low-profile, nor passively cooled as are required for many servers, this does put the Quadro RTX 4000 into an interesting position.
Let’s move on to power and thermal testing and continue with our final words.



{kind=link}
The Quadro RTX 4000 has served me well at work in an external Thunderbolt GPU chassis as a portable production GPU. It is an interesting use case as the raw GPU performance was not as critical as getting several check boxes marked on the feature set which precluded many of the lower end Quadros and made anything higher end pure overkill.
One of the requisite features was support for the Quadro Sync II board so that it can be gen-locked with various video production equipment. Since the Quadro RTX 4000 is a single slot board, the Quadro Sync II card fit in with the external GPU chassis. Note that the gen lock board can mount into a PCIe slot, all communication with the GPU card is done via ribbon cables. In a small tower system, I’ve rigged up the same genlock board inside a front panel bay to save on slot spacing.
One of the more interesting things I’ve recently tested has been with nVidia voice where this graphics card get pulled in to do some audio processing in recent months.
The one thing on my wish list for any future nVidia A4000 replacement card would be include Thunderbolt 4 ports on the GPU itself instead of Virtual-Link. It’d be far more useful and there are a handful of video production boxes with Thunderbolt 3 interfaces that could hypothetically communicate directly with the A4000’s hardware video encoders, reducing latency for real time encoding by a few critical hairs. Similarly, an HDMI 2.1 port would be valuable for the video production area that I’ve been involved in lately as a DisplayPort to HDMI adapter would not be necessary for display. Though for a multidisplay system where timing is critical, having all the ports leveraging the same adapters does equalize time vs. one native HDMI port and multiple DP ports with active adapters.
I have installed the NVIDIA RTX 4000 on my Intel s2600stbr motherboard with 256GB ram and two 10 core intel Xeon silver 4210 CPUs with windows 10 pro for workstations, and got the message after compatibility check that due to programs running in the background or OS incompatible, can anyone help with this.
I have an RTX 4000 in my Dell Precision T7610 with two 10 core Xeons and 128gb RAM. Very strangely the machine totally refused to boot up with the RTX card in the PCI-E 16x slot that in intended for the GPU card, so I removed it and put it in the lower PCI-E 16x slot and it’s fine. Bit weird but there we go.
It runs hot. Even with the case fans running fairly energetically it was in the 80’s on full load. I’ve put a slot-fan both above and below the card forcing more air to blow all over it and it’s shaved about 10 degrees off, much better. But now I’m using three slots for a single slot card, which defeats the object somewhat!
Lovely card though.