
We are covering the NVIDIA GTC 2025 keynote live. At the keynote, we expect a vast number of announcements in GPUs, AI, networking, and robotics. Expect this to be a packed keynote as NVIDIA has seen massive growth with the AI boom, becoming one of the most valuable companies in the world and a clear leader in major data center categories.
This year’s keynote is being held at the SAP Center, San Jose’s local sports venue. The show has long outgrown being able to place everyone in the main hall of the San Jose Convention Center for the keynote – though the actual show sessions still take place there – so NVIDIA has to hold it off-site at the SAP Center.
Unfortunately, the signal reception at the SAP Center with 10K+ techies is lacking at best – both WiFi and cellular are all but saturated, thanks in part to everyone trying to publish news from the keynote – so the best seat in the house is the seat at your house, with NVIDIA’s live stream of the keynote. Which is where I’m at, while Patrick is at the SAP Center to see NVIDIA’s keynote in person.
Since this is being done live, please excuse typos. If you want to watch along, here is the link:
As always, we suggest opening the keynote in its own browser, tab, or app for the best viewing experience.
NVIDIA GTC 2025 Keynote Live Coverage
It’s at a few minutes until 10am local time, and we’re just waiting for NVIDIA’s keynote to kick off.

As is usually the case, NVIDIA essentially has two tiers of announcements planned. The press has been pre-briefed on some items that will be revealed during the keynote, while critical details and certain other special announcements are withheld so that the company’s most critical announcements can’t be leaked (accidentally or otherwise) beforehand. Suffice it to say, this year’s show stands to be packed.
Officially, the keynote’s runtime per NVIDIA’s calendar invite is 2 hours, but it’s pretty common for GTC keynotes to run over. The one constraining factor? This is a morning keynote this year, instead of an afternoon keynote, so if the keynote goes on for too long, it means getting between people and their lunches!
And it looks like the keynote is going to be off to a bit of a delayed start: at this point we’re 5 minutes past the hour and things have yet to kick off.
As a general reminder, GTC keynotes these days are as much about software as they are about hardware, if not more. While NVIDIA invests billions into hardware development, they also invest similarly insane amounts into software development – and it’s the latter that’s increasingly become their moat over the last decade, as they supply hundreds of turnkey libraries, APIs, and other tools for developers. Consequently, finding a software optimization to shave off the amount of time needed to generate an LLM token can pay huge dividends. And with the rate of hardware improvement (increasing transistor counts) slowing down, it makes software all the more important.
And here we go!
This year’s theme: AI Factory

And tokens. In NVIDIA’s world, tokens are the unit of compute for AI (and what their customers can charge for)
“Token’s don’t just teach robots how to move, but how to bring joy”
“And here is where it all begins”

“This year we want to bring you to NVIDIA’s headquarters”
“We have a lot of incredible things to talk about”
Jensen is making it a point to let the audience know that he’s doing this without a script or teleprompter.
“GTC started with GeForce”
Jensen has a GeForce RTX 5090 in his hands, as well as a RTX 4090 for comparison’s sake.

Jensen is showing off a path traced environment – with significant AI to provide upscaling, denoising, etc.
“Generative AI fundamentally changed how computing is done”
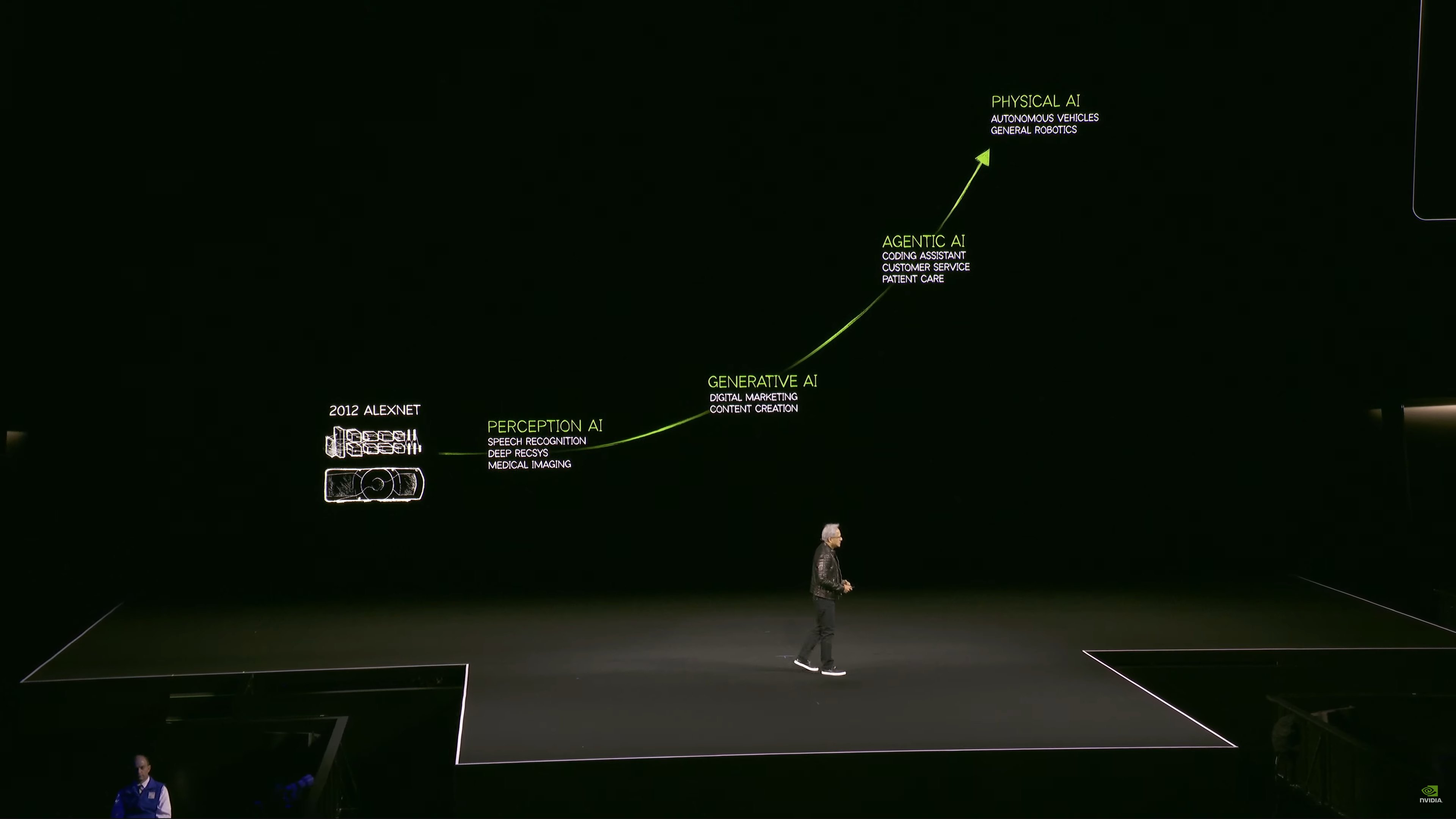
AI now has agency – what Jensen refers to as “Agentic” AI. Models can retrieve content from websites, both as training, but also as more immediate information retrieval.
Jensen says they’re also going to talk a lot about reasoning AIs today.
As well as “physical AI,” using AI to help simulate and train other AI models.
“The only way to make GTC bigger is to grow San Jose. We’re workin’ on it!”
Every single year, more people come because AI is able to solve more problems for more people and companies.
Three fundamental scaling laws:
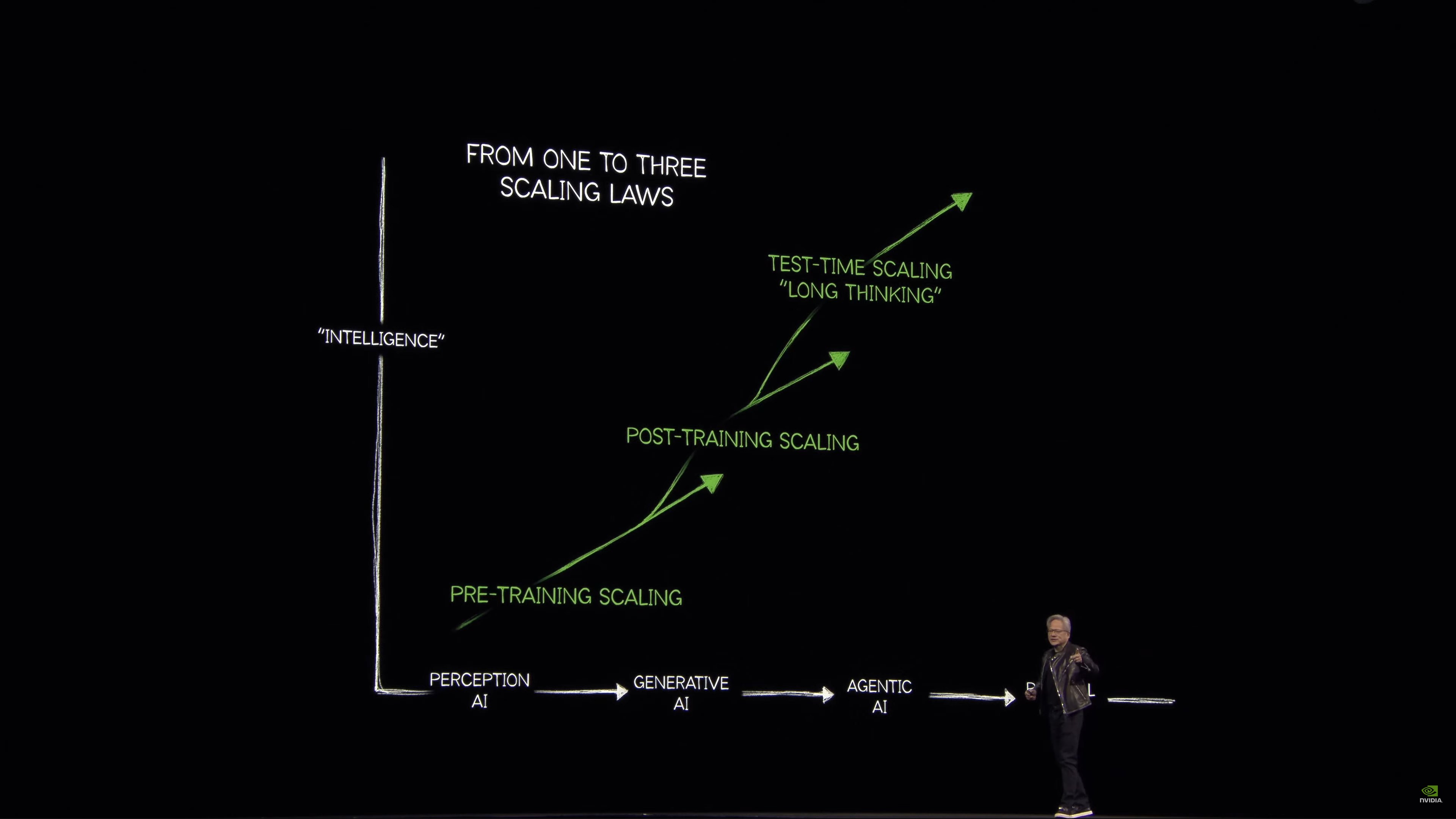
Pre-training scaling, post-training scaling, and test-time scaling. How do create, how do you train, and how do you scale?
Scaling: this is where almost the entire world got it wrong last year. The amount of computation we need as a result of reasoning is easily 100x more than the world thought it would need last year.
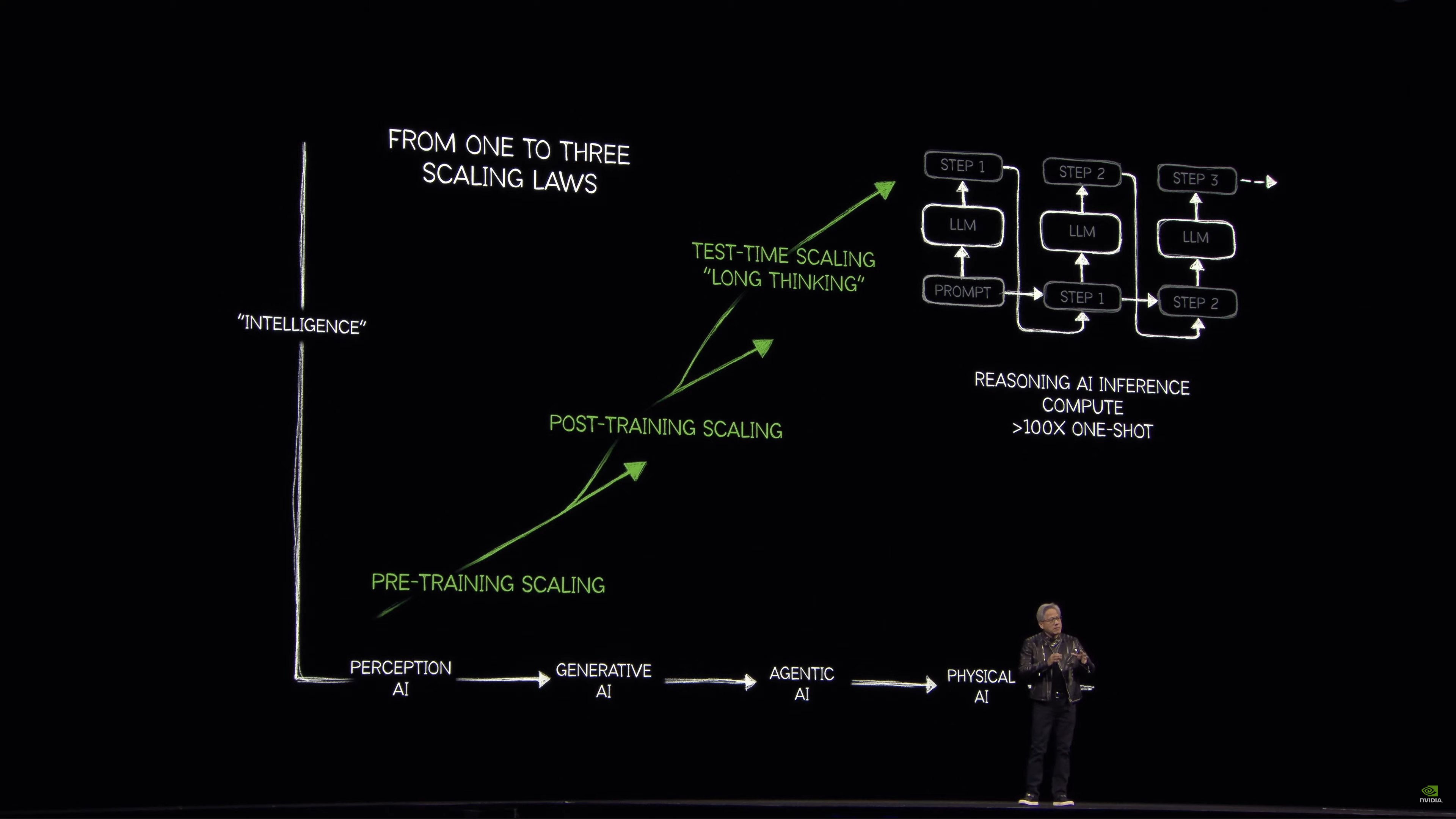
We now have AIs that can reason step by step thanks to chain of thought and other techniques. But the underlying process of generating tokens has not changed. Instead, this kind of reasoning requires many more tokens – substantially higher, “easily 100 times more.”
In order to keep models responsive, the amount of computation required per second is equally as high.
Reinforcement learning is the big breakthrough of the last few years. Give AIs millions of different examples to solve a problem step-by-step, and reward (reinforce) the AI as it does a better job. That comes out to trillions and trillions of tokens to train that model. In other words: synthetic data generation to train an AI.
Jensen says that this has been embraced by the industry with hardware sales.
Hopper shipments of the top for cloud service providers. Peak year of Hopper versus the first year of Blackwell.
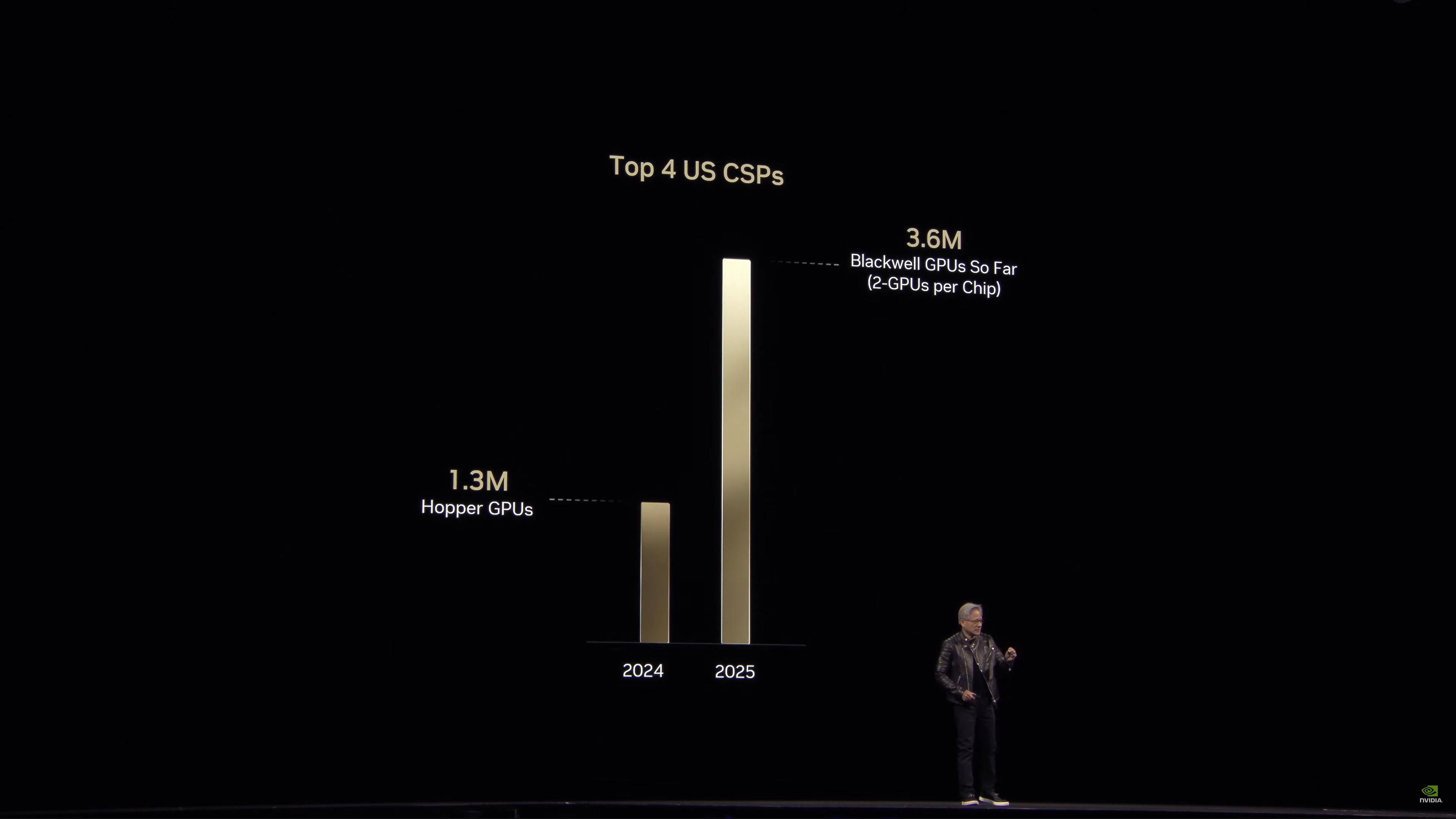
In just one year – and Blackwell has just started shipping – NVIDIA is reporting significant growth in in enterprise GPU sales.
Jensen expects datacenter buildout to reach a trillion dollars quite soon.
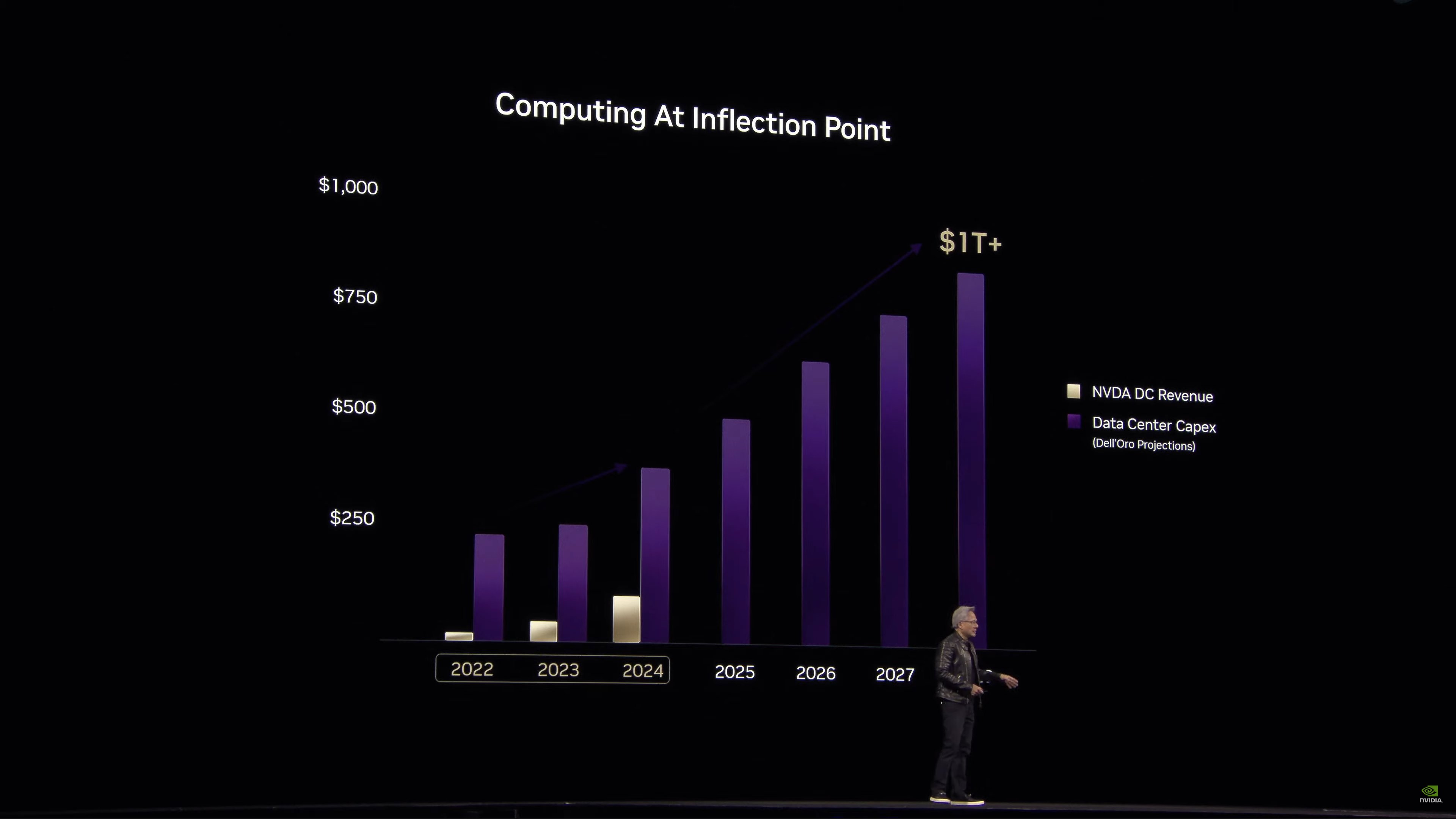
Jensen believes we’re seeing an inflection point in datacenter buildouts towards accelerated computing (i.e. GPUs and other accelerators instead of just CPUs).
“The computer has become a generator of tokens, instead of a retrieval of files”. This is what NVIDIA calls an AI Factory.
While everything in the datacenter will be accelerated, not all of it will be AI.

You also need frameworks for physics, biology, and other fields of science. All of which NVIDIA already provides as part of their CUDA-X libraries. cuLitho for computation lithography, cuPynumeric for numerical computing, Aerial for signal processing, etc. This is NVIDIA’s “moat” in the larger industry.
“We’re going to have our first Quantum Day here at GTC” on Thursday.
“The install base of CUDA is now everywhere” By using these libraries, developers software can reach everyone.
Now Jensen is taking 5 while NVIDIA runs a short video about CUDA and thanking the many developers at the show.

Blackwell is over 50,000x faster than the first CUDA GPU.
And back to Jensen.
“I love what we do. I love even more what you do with it.”

CSPs love that CUDA developers are CSP customers.
But now that they’re going to take AI out to the rest of the world, things are changing a bit. GPU clouds, Edge computing, etc, all have their own requirements.
Among NV’s many smaller announcements, several companies (Cisco, T-Mobile, and others) are building a full stack for radio networks in the US using NVIDIA’s technologies (Ariel-Sionna, etc).
But that’s just one industry. There’s also autonomous vehicles. AlexNet convinced NVIDIA to go all-in on self-driving car technology. And now their technologies are being used all over the world. NVIDIA builds computers for training, simulation, and the self-driving car computer.
NVIDIA is announcing that GM is going to be partnering with NVIDIA to build their future self-driving car fleet.
“The time for autonomous vehicles has arrived”
(I hope this is true, but I feel like I heard something very similar when I was riding around in an NV-powered autonomous vehicle at CES 2018)
NVIDIA has had all 7 million lines of code safety assessed by third parties. Safety would seem to be the operative word for NVIDIA’s automotive efforts this year.
Now rolling another video, this time on the tech and techniques NVIDIA is using to create autonomous vehicles.
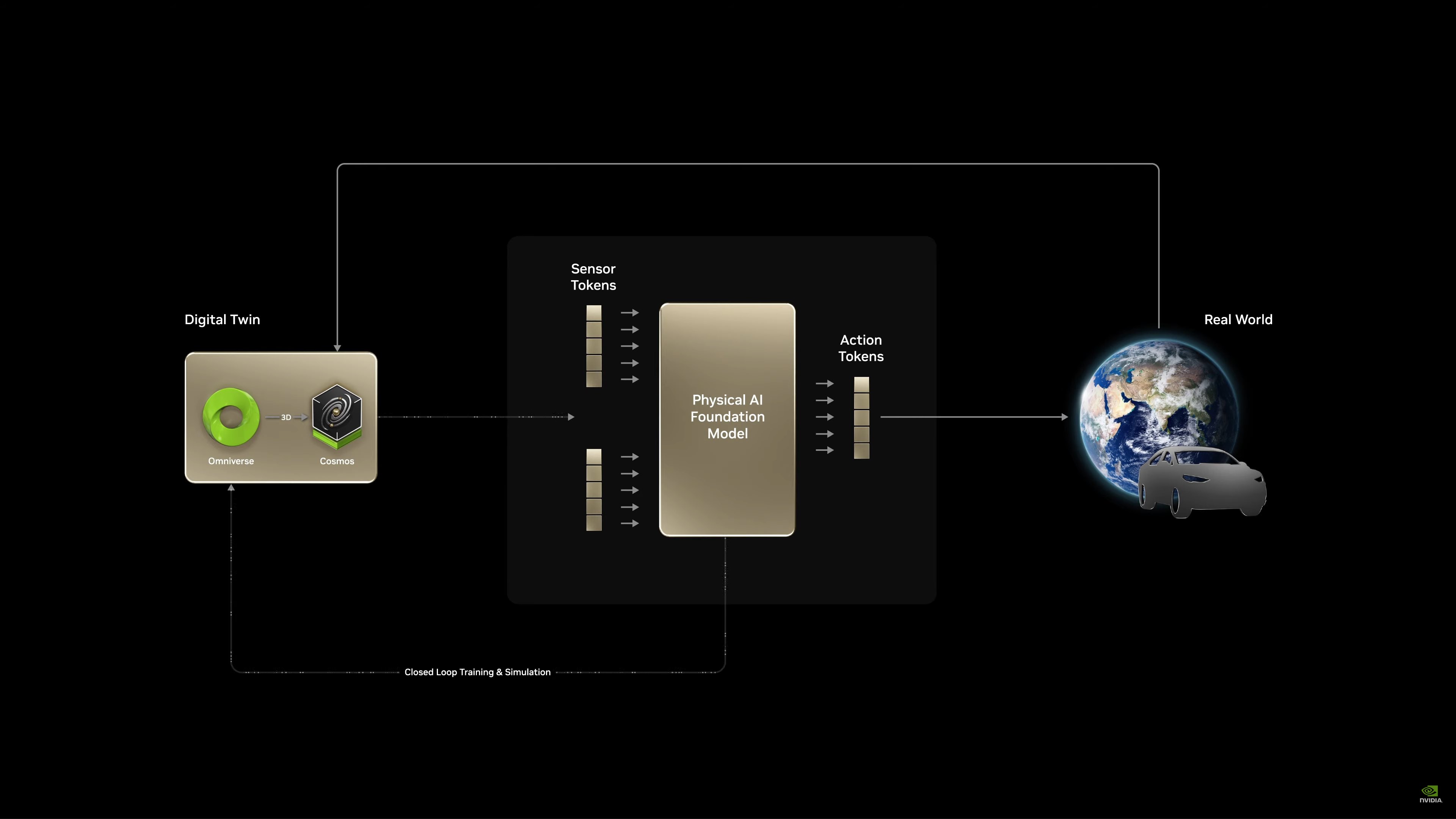
Digital twins, reinforcement learning, generating diverse scenarios, etc. All built around NVIDIA Cosmos. Using AI to create more AI.
Now on to datacenters.

Grace Blackwell is now in full production. Jensen is showing off the various rack systems offered by its partners.
NVIDIA has spent a very long time working on distributed computing – how to scale up, and then how to scale out. Scale-out is hard; so NVIDIA had to scale-up first with HGX and 8-way GPU configurations.

Jensen is showing out an NVL8 system is built. With an emphasis on the past.
To go past that, NVIDIA had to re-engineer how NVLink systems worked to scale up even further. NVIDIA moved NVLink switching outside of the chassis, and moved it to a rack unit device. “Disaggregated NVLInk”

Now NVIDIA can offer one ExaFLOP (of low precision) in one rack.

The Blackwell GPU is already pushing the reticle limits, so NVIDIA scaled up by going to what is essentially now rack-scale systems instead of individual servers.
All of this, in turn, is to help provide compute performance for AI. And not just for training, but for inference as well.
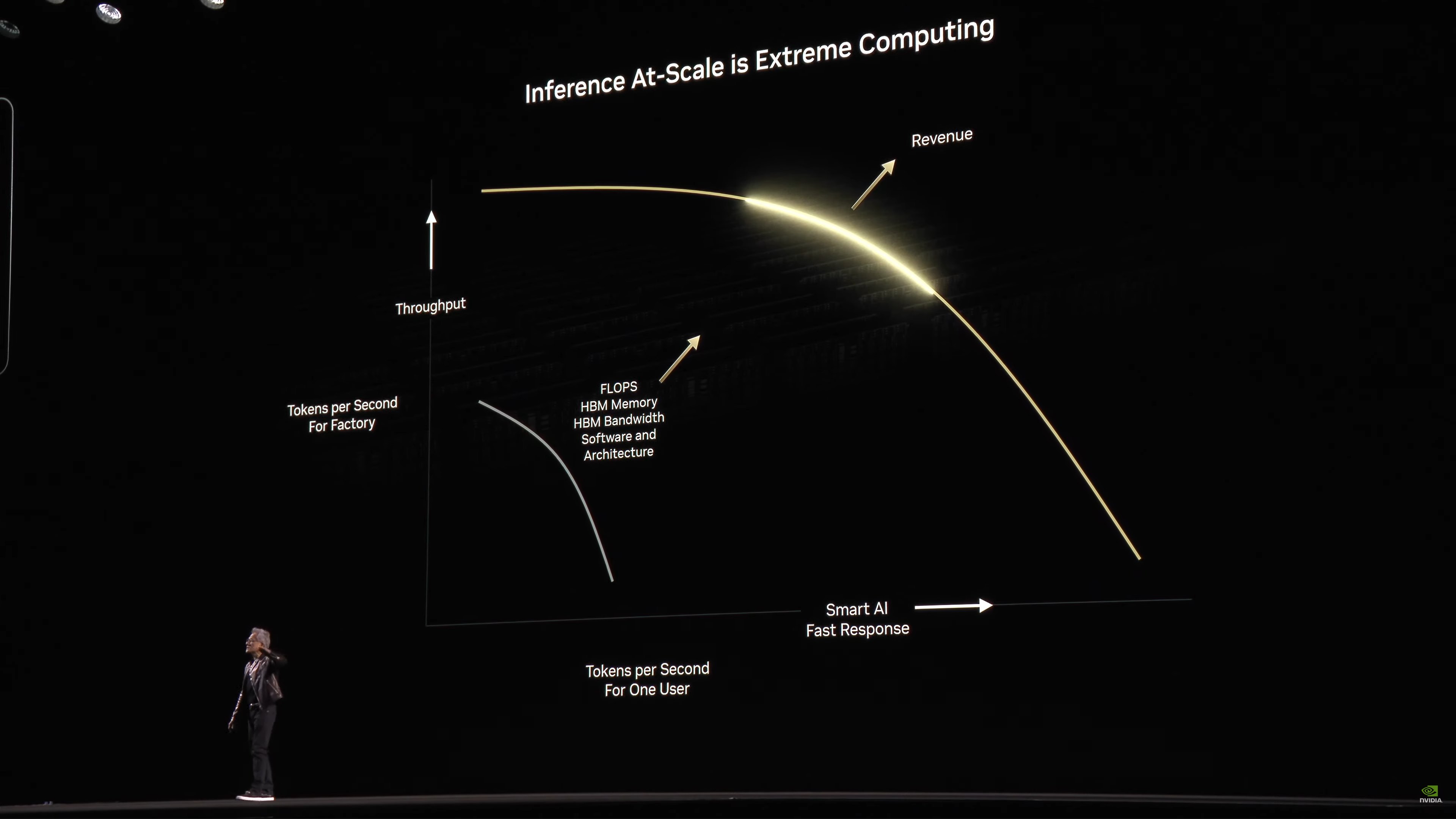
Jensen is presenting an inference performance curve for large scale computing. In short, it’s a balance between total throughput and responsiveness. Keeping the system saturated will maximize token throughput, but it will take an individual token a long time to get generated. Take too long, and users will move on to somewhere else.
It’s the classic latency versus throughput trade-off.
So for NVIDIA’s CSP partners and other customers who are using NV hardware for inference, to maximize their revenues they need to carefully pick a point on the curve. Generally, the ideal point will be up and to the right – the most throughput and responsiveness without significantly compromising one for a minor improvement in the other.
All of this requires FLOPS, memory bandwidth, and more. So NVIDIA built hardware to provide just that.
Now running another video, showing the utility and computational needs of reasoning models.

A traditional LLM is fast, efficient, and wrong in NVIDIA’s use case of wedding seating. 439 tokens wasted. The reasoning model can handle it, but it requires over 8,000 tokens.
Making all of this performant doesn’t just require lots of hardware, but lots of optimized software, right down to the OS in order to handle fundamental optimizations like batching.
Pre-fill – digesting information – is very FLOPS-intensive. The next step, decode, is memory bandwidth intensive as the model needs to be pulled in from memory; trillions of parameters in. All of this to produce 1 token.
This is fundamentally why you want NVLink. To take many GPUs and turn them into one massive GPU.
And then this allows for further optimizations. How many GPUs will be used to work on pre-fill versus decode?
Announcement: NVIDIA Dynamo, a distributed inference serving library. The operating system of the AI Factory.
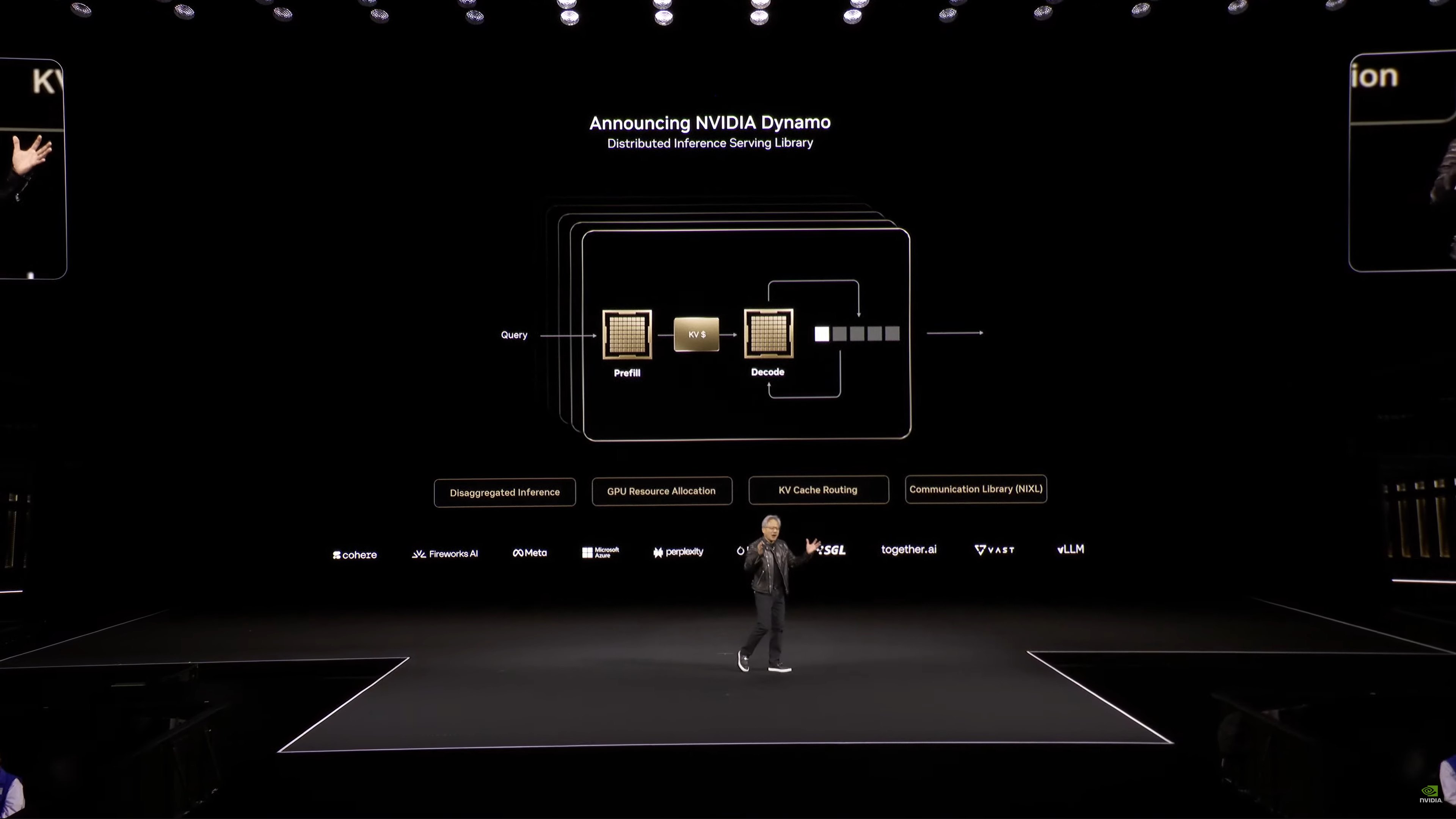
Jensen is comparing Dynamo to VMWare in terms of scope. Whereas VMWare was laid out over CPU systems, Dynamo is laid out over GPU systems.
Dynamo is open source.
Now back to hardware and performance. Jensen is comparing an NVL8 Hopper setup to Blackwell. Tokens per Second per Megawatt plotted against Tokens per Second per User.
“Only at NVIDIA do you get tortured with math”
For service providers, lots of tokens over lots of time translates into lots of revenue. Keeping in mind the throughput versus responsiveness tradeoff. This is the curve that NVIDIA is trying to bend.
Blackwell improves on this with better hardware and support for lower precision data formats (FP4). Use less energy to do the same as before, in order to do more.
“Every future datacenter will be power limited.” “We are now a power-limited industry”
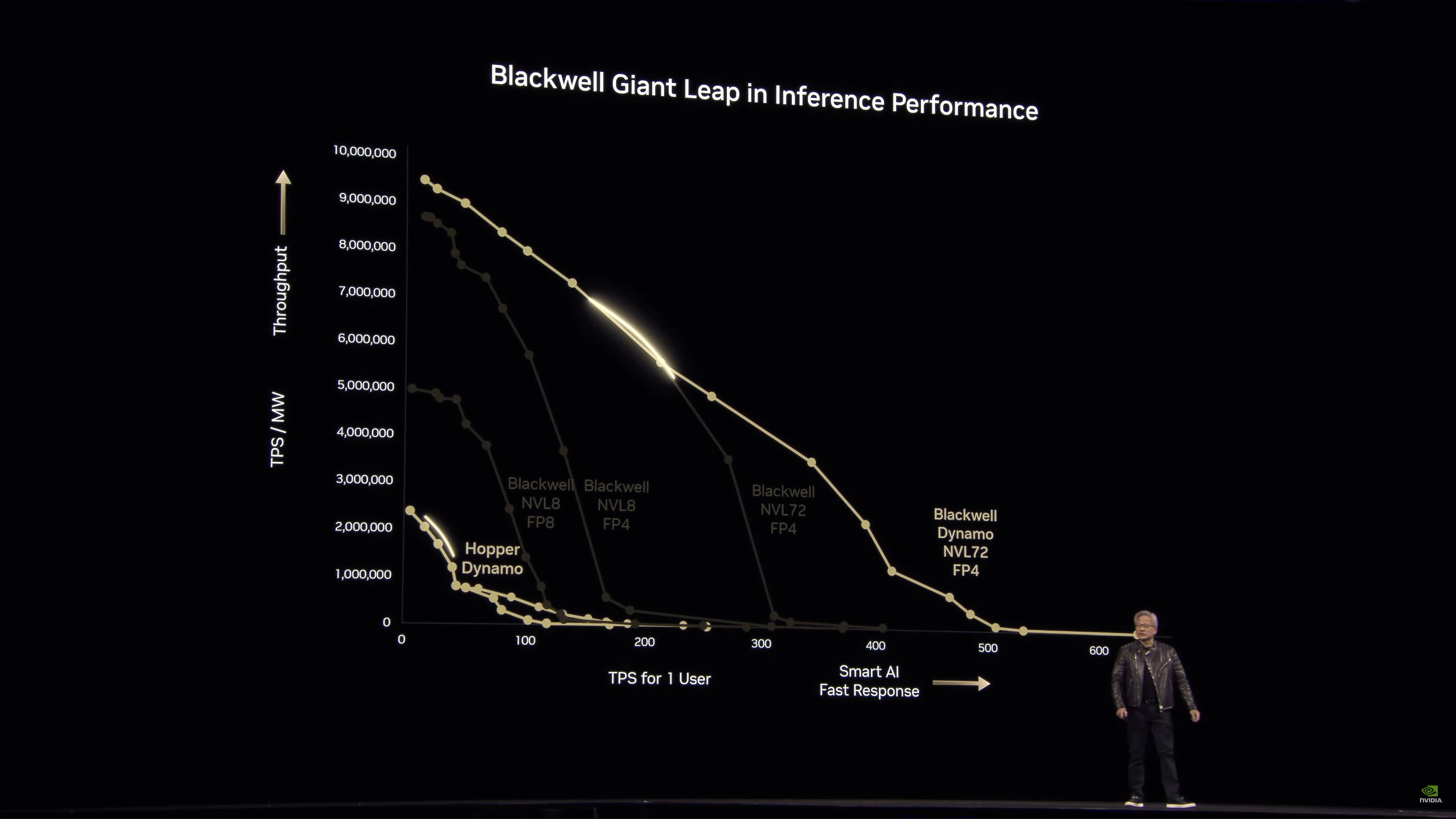
Dynamo helps make Blackwell NVL72 even faster. And this is at iso-power, not iso-chip. 25x in one generation.
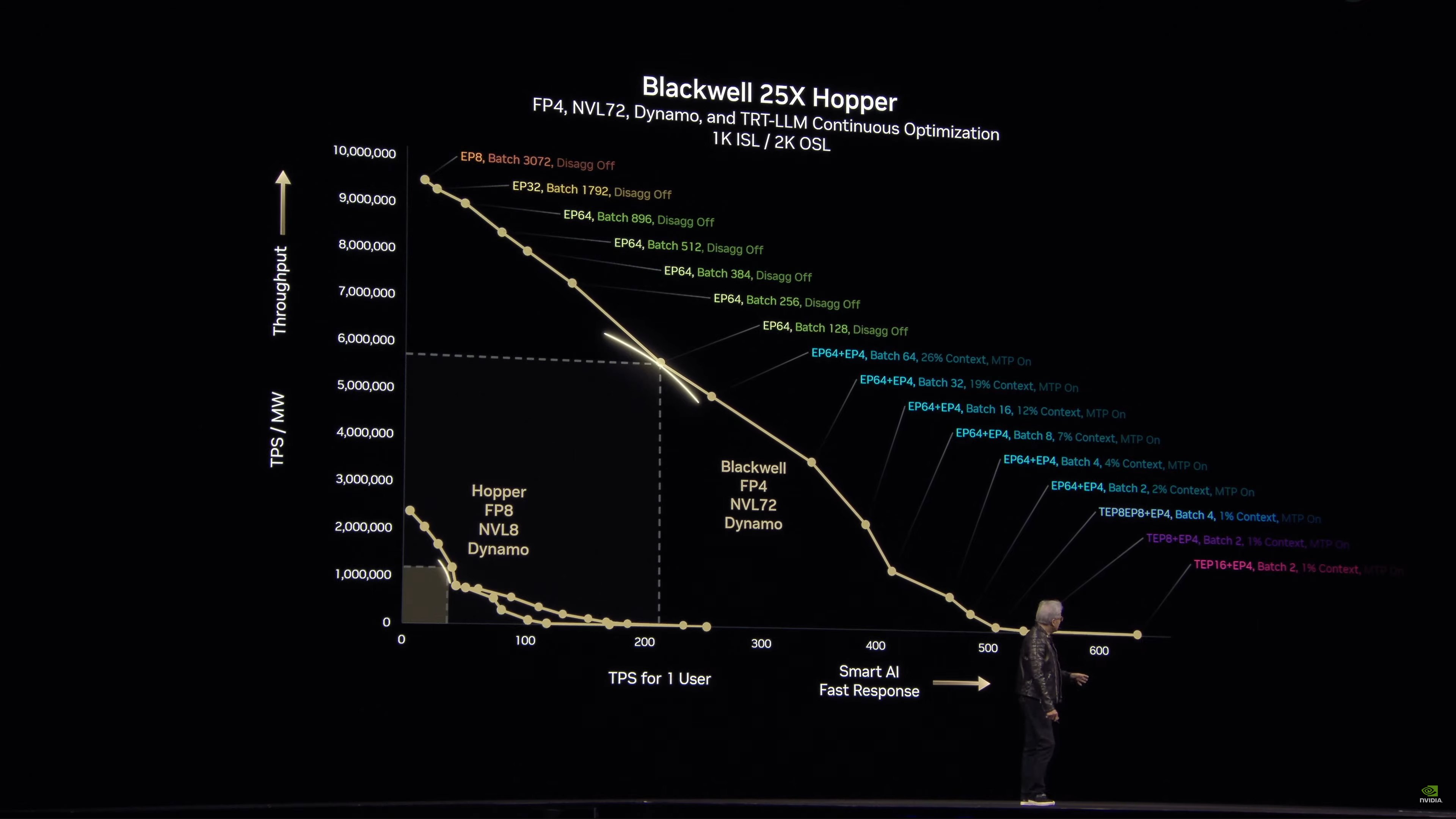
Now talking a bit about pareto frontiers and pareto optimality, and how various model configurations hit different points on the curve.
And in other situations, Blackwell can hit 40x the (iso-power) performance of Hopper.
“I’m the chief revenue destroyer.” “There are circumstances where Hopper is fine.”

And there it is: “The more you buy the more you save.” “The more you buy, the more you make.”
Rolling another video. This time talking about how NVIDIA is building digital twins for datacenters of all things. (In NV’s world, it’s just another factory, after all)
Ultimately, using a digital twin allows for all of this to be planned and optimized in advance, and then finally built once and built quickly.

Jensen is running out of time and is going to have to pick up the pace!
Blackwell Ultra NVL72, shipping in the second half of this year. 1.1 Exaflops dense FP4 inference. 2x more networking bandwidth. 20TB of HBM system memory. And a new attention instruction that should double performance there.
The industry is now at a point where spending has to be planned on. Companies are making multi-year commitments to hardware, to facilities, and to NVIDIA’s ecosystem. Which is why Jensen wants to make NVIDIA’s roadmap clear.
Following Blackwell is Vera Rubin, who discovered dark matter.

Vera Rubin NVL144, second half of 2026. Vera Arm CPU + Rubin GPU.
Going forward, NVIDIA is now counting GPU dies rather than individual GPU chips going forward when talking about NVLink domains. So NVL144 is 144 dies, not 144 chips.

And then Rubin Ultra NVL576 in the second half of 2027. 600KW for a rack. 15 ExaFLOPs. 1TB HBM4e memory per GPU package.


Rubin is going to drive the cost of AI compute down significantly.
And that was scale-up. Now it’s time to talk about scale-out and NVIDIA’s networking products.
Jensen is recapping NVIDIA’s decision to buy Mellanox and to get into the networking market.

CX-8 and CX-9 are coming. NVIDIA would like to scale out to many hundreds of thousands of GPUs in the Rubin era.
Scale-out means that datacenters are the size of a stadium. Copper connections won’t cut it. Optical is needed. And optical can be very energy intensive. So NVIDIA plans to make optical networking more efficient with co-packaged silicon photonics.

Based on a technology called Micro Ring Modulators (MRM). Built at TSMC on a new 3D stacked process they’ve been working on with the fab.

(De-tangling cables) “Oh mother of god”
Jensen is talking about how current optical networking works, with individual transceivers for each port on both sides. This is reliable and effective, but the electrical to optical conversion (and back again) adds up to a low of power consumed.
“Every GPU would have 6 transceivers”. This would take 180 Watts (30W per) and thousands of dollars in transceivers.
All the power consumed by transceivers is power that can’t be used on GPUs. Which keeps NVIDIA from selling customers that many more GPUs.
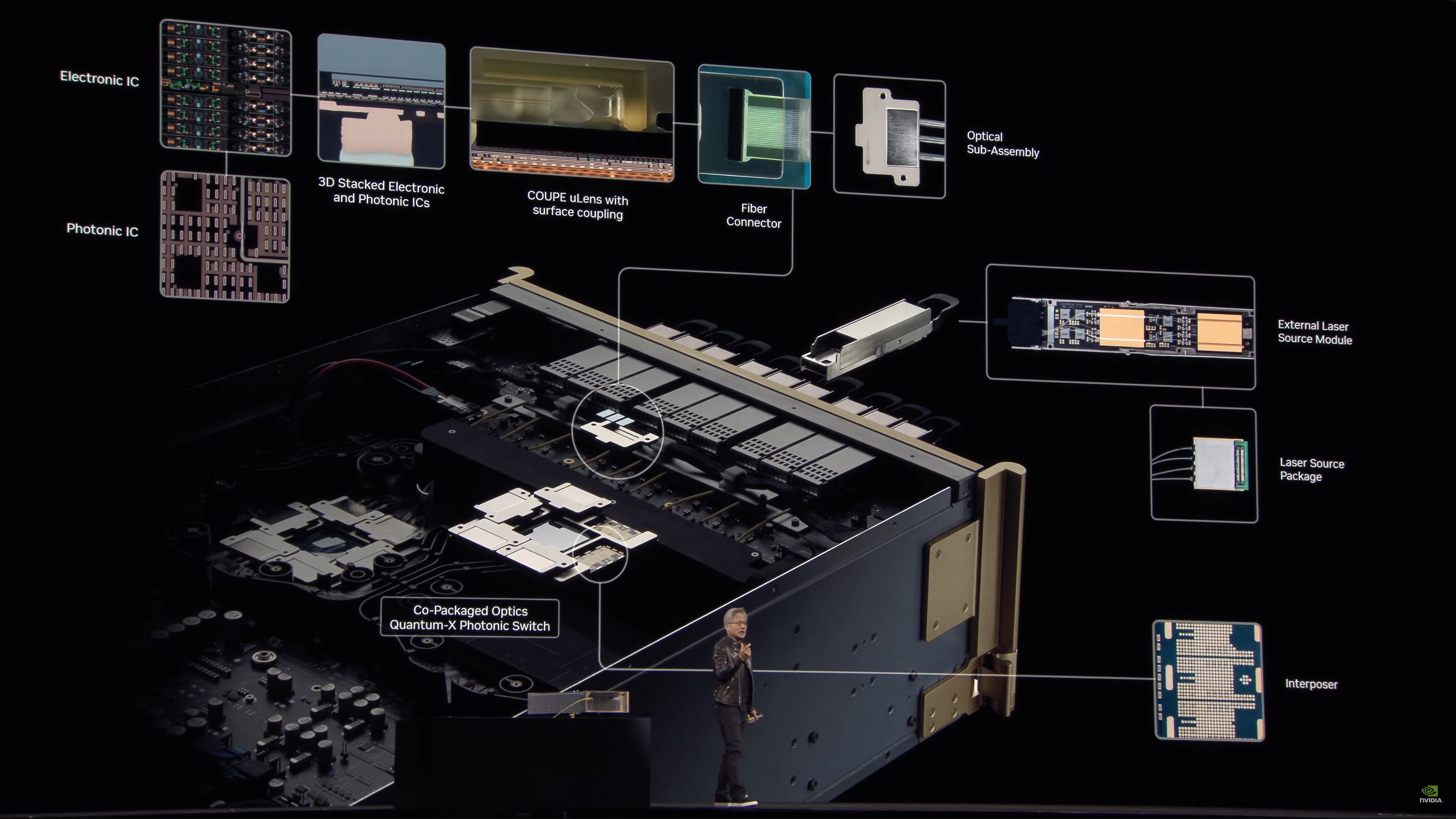
Packaged as TSMC using COUPE.
Now rolling another video, showing how the photonics system works in a bit more detail.

NVIDIA will ship a silicon photonics Quantum-X (InfiniBand) switch later in 2025, and then a Specturm-X (Ethernet) switch in the second half of 2026.
No transceivers – direct fiber in. Up to 512 ports on the Spectrum-X switch.
Saving 6 MW is 10 Rubin Ultra racks a datacenter can add.

A new platform every year.
The next generation of GPUs after Rubin? The legendary Richard Feynman.
Now pivoting to systems.
100% of NVIDIA software engineers will be AI-assisted by the end of this year. We need a new line of computers.
Announcing DGX Spark. This is the final name for NVIDIA’s previously announced Project DIGITS mini-PC.
Unfortunately, it looks like the uplink for the live stream may have just died… Standby.

After a few minutes gap, we’re back.
DGX Spark and DGX station.

GPU acceleration of storage as well. NVIDIA has been working with all of the major storage vendors.
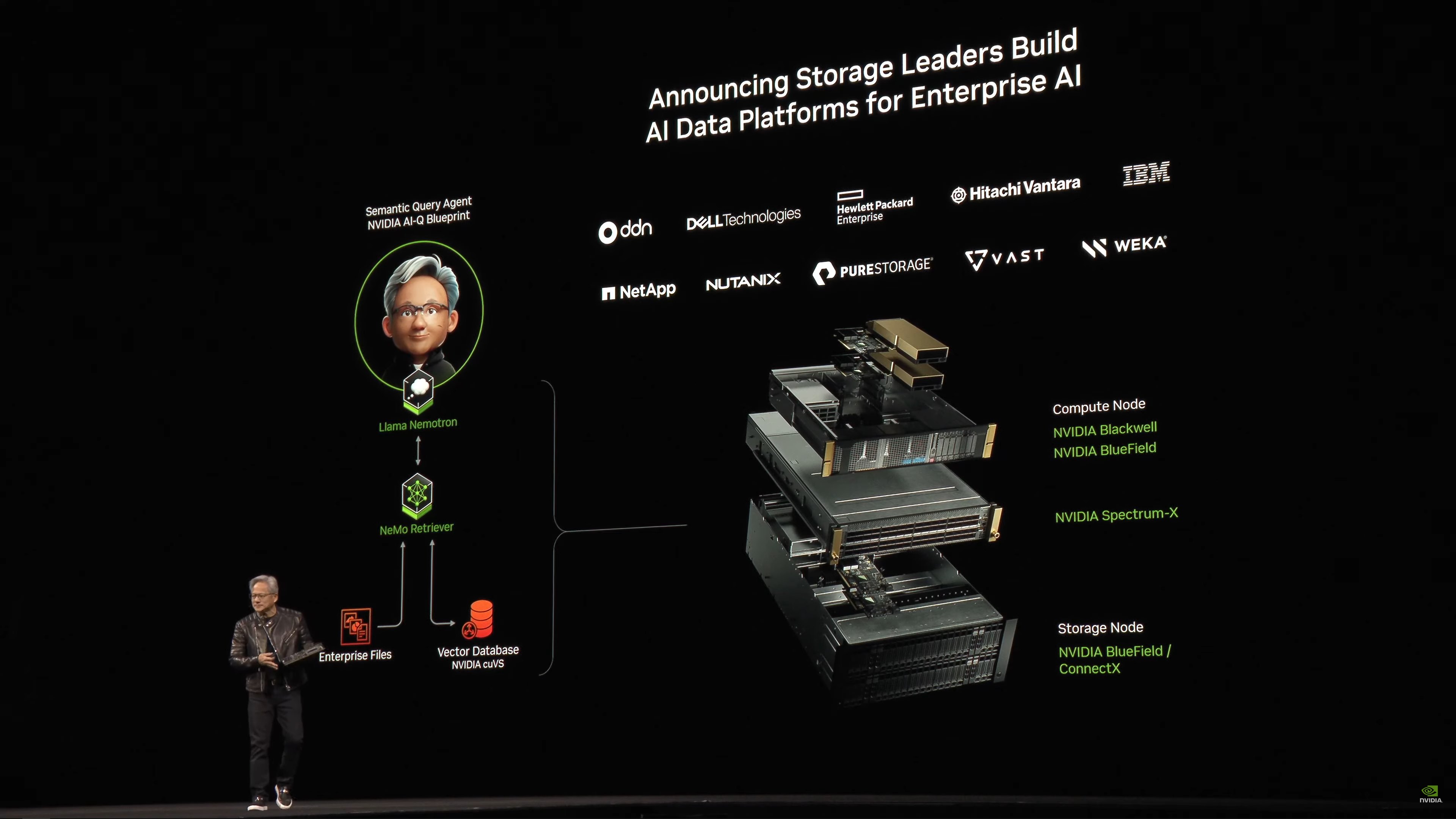
Dell is going to be offering a whole line of NVIDIA-based systems.
NVIDIA is also announcing a new open source model: NVIDIA Nemo Llame Nemotron Reasoning.
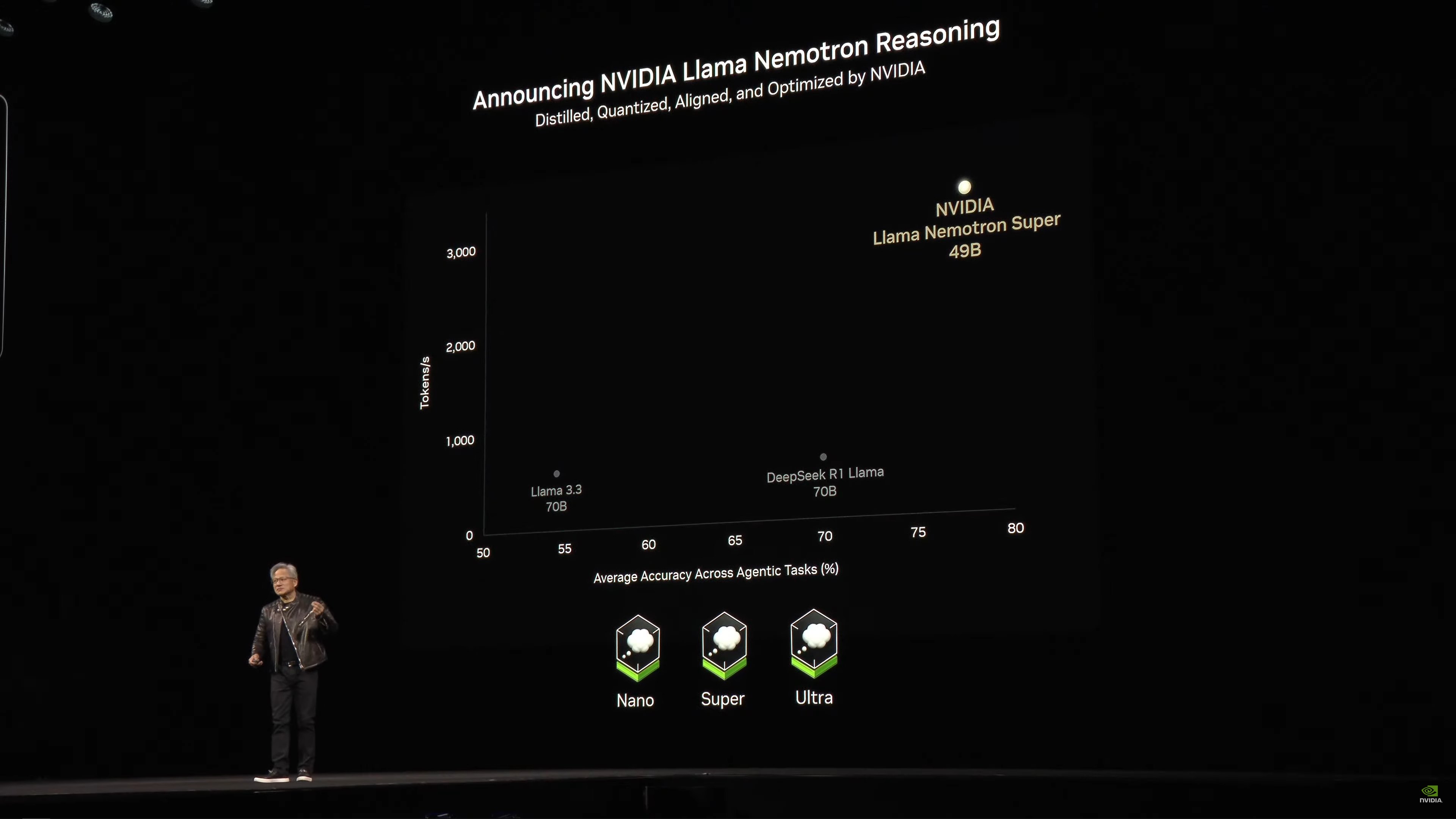
Now quickly blasting through slides on all of NVIDIA’s customers who are integrating NVIDIA technology into their frameworks.
Now on to robotics.
“The world has a severe shortage of human workers”
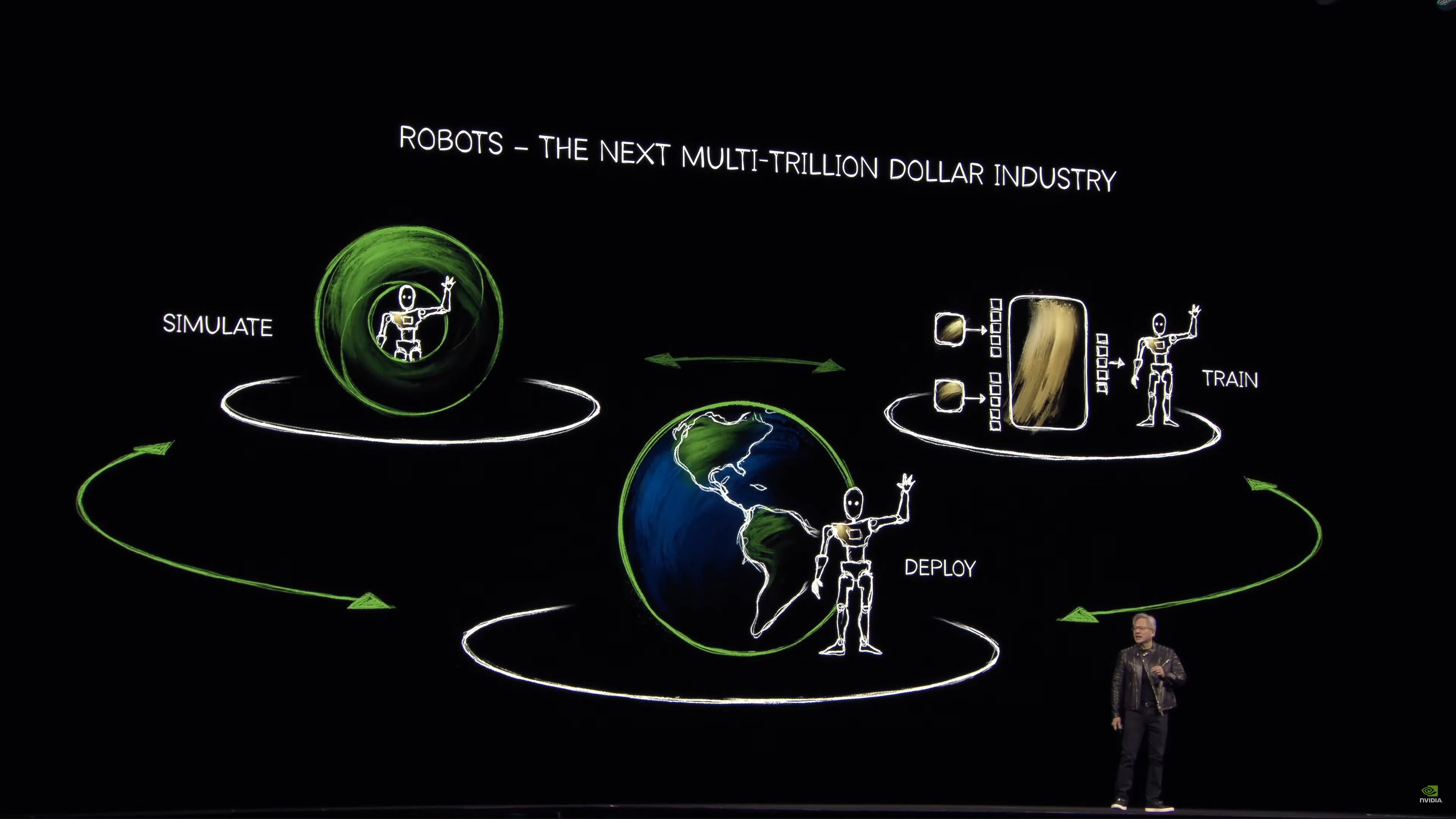
Now rolling a video on robotics.
Those robots, in turn, will be trained via AI simulation of the physical world.
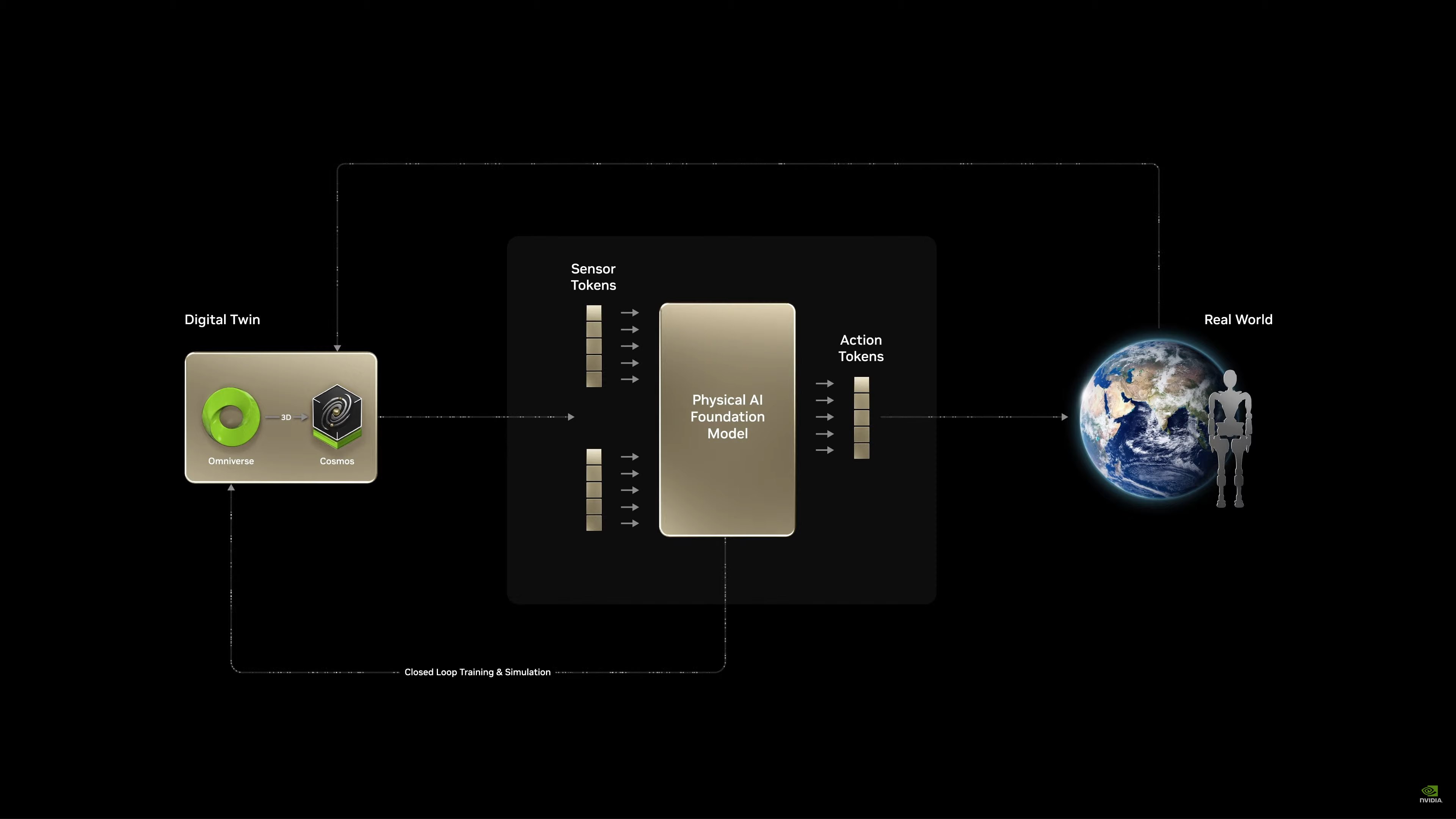

A lot of this video is a recap of what NVIDIA has previously discussed. Use digital twins to create a virtual facility to help train robots. (When robots screw up in a virtual world, nothing breaks)
Introducing NVIDIA Isaac GROOT N1.
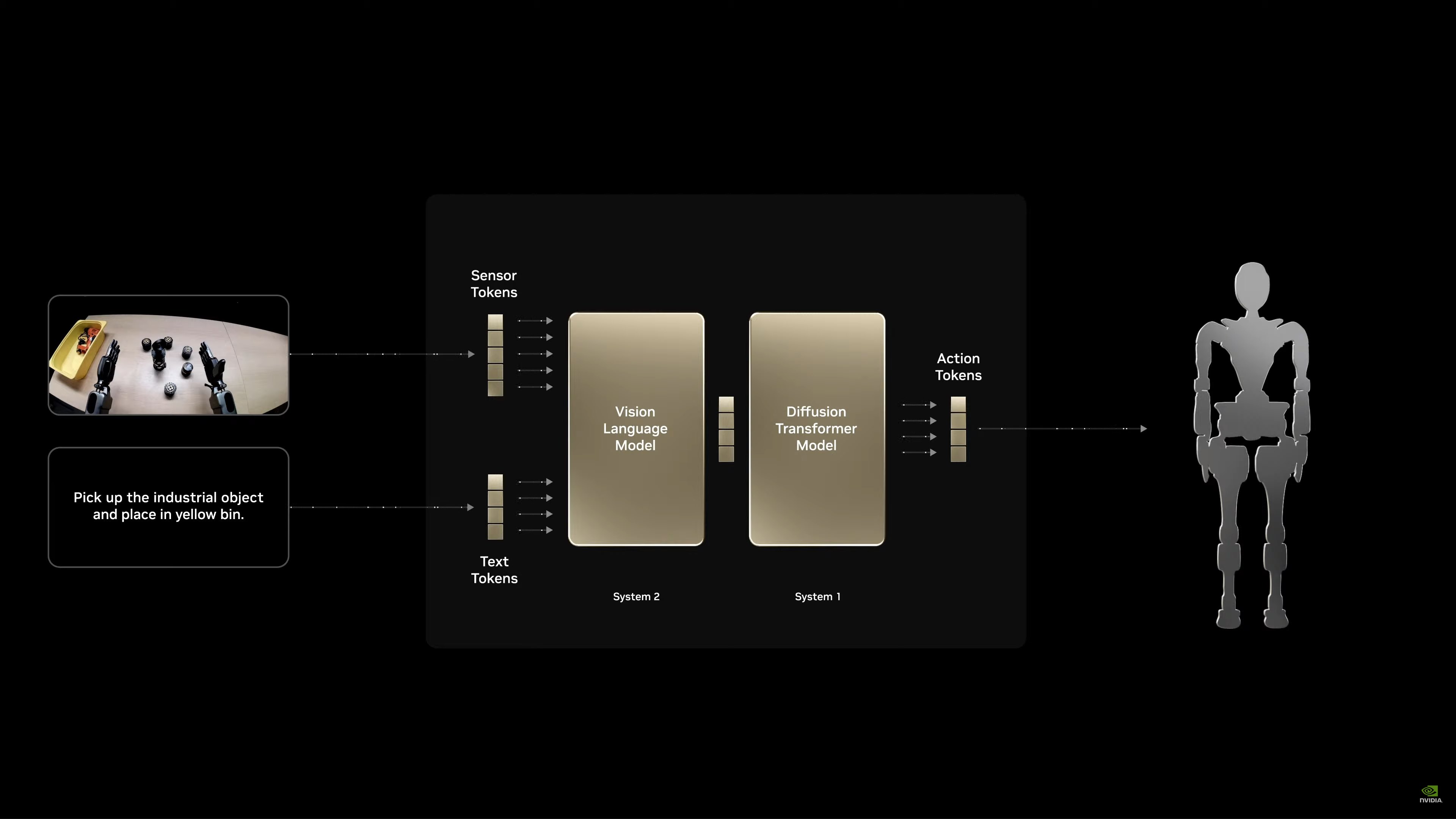

“Physical AI and robotics are moving so fast. Everybody pay attention to this space. This could very likely be the largest industry of all.”
Jensen is recapping how the Omniverse + Cosmos simulation works. Using Cosmos to create a variety of environments to help training.
What’s a verifiable reward in robotics? Physics. If a robot behaves in a physically correct manner, then that can be verified as accurate.
Now rolling another video, this time for a new physics engine called Newton.
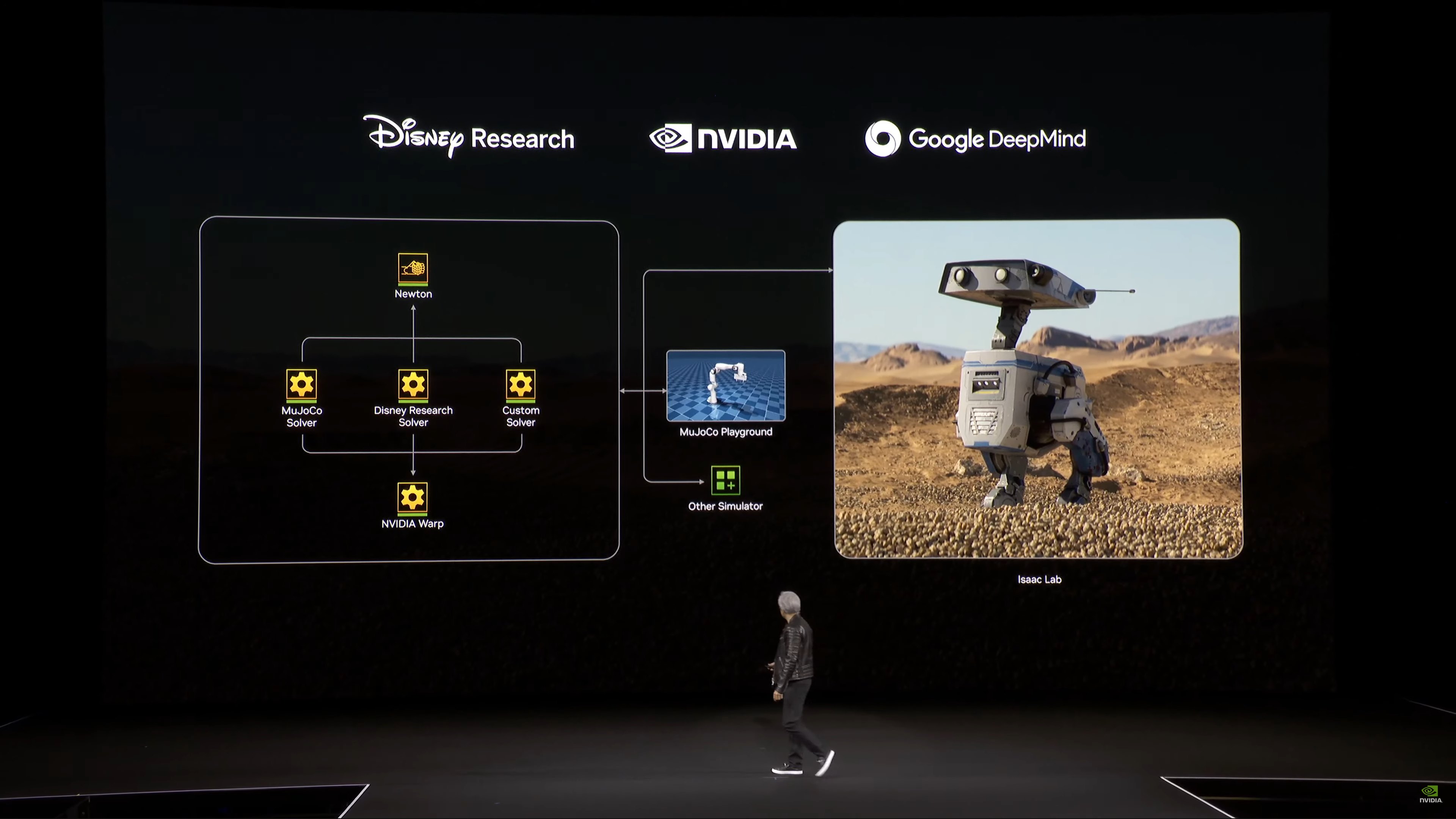


Going from digital to real. The robot in the video, Blue, is a real robot.
“Let’s finish this keynote. It’s lunchtime”
Also announcing today that Gr00t N1 is open source.
Now to wrap things up.

Blackwell is ramping, but NVIDIA already has their eyes on Blackwell Ultra for late 2025, Vera Rubin for 2026, Rubin Ultra for 2027, and Feynman for 2028.
One more treat:
And that’s a wrap. Thank you for joining our live blog coverage of the GTC 2025 keynote.
Final Words
While NVIDIA’s critical GPU business segment is decidedly mid-generation right now, GTC 2025 is making it clear that it isn’t stopping the rest of the company from moving full steam ahead. Looking at a world where the company expects demand for AI hardware to grow even more thanks to computationally-intensive reasoning models, NVIDIA is moving forward on both the hardware and software fronts to provide new tools and better performance. And ultimately, greater energy efficiency for a business that is becoming fundamentally energy limited.
On the hardware side of matters, while Blackwell is technically still ramping, NVIDIA already has its eye on what’s next. And for the second half of 2025, that is going to be the bigger and better B300 Blackwell Ultra GPU, which is a mid-generation kicker to the Blackwell family that is slated to offer improved performance. Details from NVIDIA are still sparse, but its main selling points are, for a single GPU package, 50% better FP4 performance (15TFLOPS) and support for 288GB of on-package HBM3e memory, a 50% improvement over the B200 GPU. Like its predecessor, this is a twin-die chip, with two “reticle-sized” GPUs packed into a single die.
Blackwell Ultra, in turn, will be used as well to build a newer Grace Blackwell GB300 superchip, which will be used as the building block for further NVIDIA products, most notably the Blackwell Ultra NVL72 rack-scale system, to augment NVIDIA’s current GB200 NVL72 offering.
Meanwhile, NVIDIA is also offering, for the first time in a while, a fresh hardware roadmap for the company, taking it to 2028. Acknowledging the fact that NVIDIA is now a major company with customers needing to make massive investments in the company’s hardware and product lines, NVIDIA is now aiming to be more transparent on their future hardware plans – at least on a very high level with product names and some very basic specifications.
To that end, in the second half of 2026 we’ll see the release of NVIDIA’s next-generation Arm CPU, codenamed Vera, while the GPU side will deliver the Rubin GPU architecture. Late 2027 will see the Rubin family refreshed with Rubin Ultra, a 4 die GPU. And 2028 will see the Vera CPU paired with GPUs based on the newly announced Feynman GPU architecture, which will use a next-generation (post-HBM4e?) memory technology.
As for NVIDIA’s networking business, the former Mellanox group will be augmenting NVIDIA’s AI efforts with the introduction of co-packaged silicon photonics into NVIDIA’s switches. Designed to cut down on the amount of power required for networking by ditching dedicated optical transceivers, NVIDIA will be using silicon photonics to more directly drive the requisite lasers. The second half of 2025 will see the introduction of a Quantum-X (InfiniBand) switch, while the second half of 2026 will bring a pair of Spectrum-X (Ethernet) switches using the technology. Overall, NVIDIA is expecting that customers will be able to reinvest the power savings from their silicon photonics switches into buying and installing more GPU systems.
And last but not least, NVIDIA is at the show with several software announcements. Dynamo promises to help load balance and optimize the execution of inference on large GPU systems, helping NVIDIA’s service provider customers balance throughput with responsiveness to maximize how much work – and how much revenue – they get out of their for-hire GPU services. Meanwhile other offerings such as GR00T N1 and Llama Nemotron reasoning are aimed at the robotics and AI communities respectively.



{kind=link}
…we know how it ended with the babel tower, but…
I used to not believe but now I do, History will vindicate Ted K