
Last week we covered the AMD Instinct MI300X GPU and MI300A APUs Launched for AI Era. During the event, we learned that AMD is going much broader with its XGMI technology, called Infinity Fabric. Broadcom announced that its next-generation PCIe switches will support XGMI/ Infinity Fabric on stage. There were also rumblings at the event around XGMI-connected NICs which would be the next step for RDMA NICs.
Next-Gen Broadcom PCIe Switches to Support AMD Infinity Fabric XGMI to Counter NVIDIA NVLink
During the event, AMD showed its massive GPUs and APUs dubbed the AMD Instinct MI300X and MI300A respectively.

It is one effort to build a server with eight OAM accelerators stick them in a UBB and make an 8-way accelerator server platform. It is another to scale that server platform to a cluster of servers to do AI training.

At the event, AMD said that it is putting its weight behind Ethernet, and specifically the Ultra Ethernet Consortium to use Ethernet instead of Infiniband as the interconnect of choice for AI clusters.

AMD then said that it is opening up its Infinity Fabric ecosystem to new partners.

Infinity Fabric is perhaps best known as the interconnect that AMD uses between processors in EPYC servers.
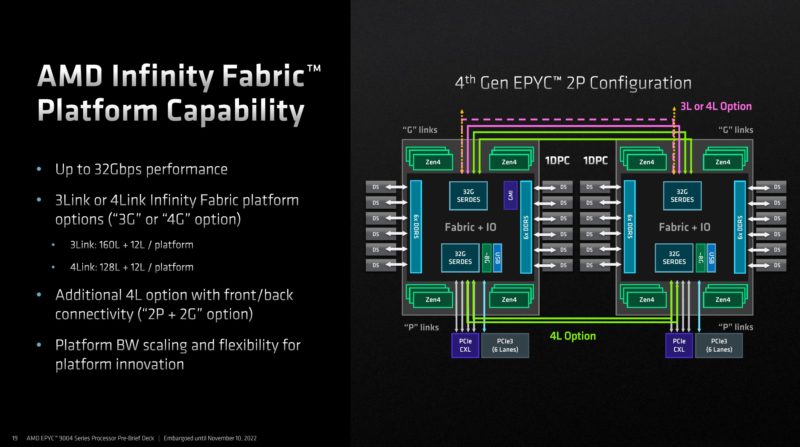
One of the really neat capabilities of AMD Infinity Fabric/ XGMI controllers is that they can serve multiple functions. AMD’s I/O controllers can do things like handle package-to-package connectivity as Infinity Fabric, PCIe Gen5 for cards, and CXL. On stage at the event, Jas Tremblay, Vice President and General Manager of the Data Center Solutions Group at Broadcom said that its next-generation PCIe switches will support XGMI/ Infinity Fabric.

That is an important tidbit. We expect the next-generation of PCIe switches to also start looking at features like CXL and have shown the switches from companies like XConn for a number of years.

It seems like Broadcom is not just looking at PCIe and CXL, but it also has plans to have switches for things like Infinity Fabric. At a system level, that is a big deal. NVIDIA HGX V100, A100, and H100 systems have one internal level of NVSwitches to provide an interconnect within a chassis, and then an external link for external switches. NVIDIA also briefly had a 16-GPU configuration in the NVIDIA DGX-2 with tray-to-tray NVSwitch links.

For AMD, this is a big deal. A switched topology will allow more than eight GPUs per node without having to use less efficient PCIe signaling.
We also heard another nugget at the show. Imagine not just the CPU and GPU communication happening over XGMI/ Infinity Fabric. Instead, imagine a world with XGMI-connected NICs where the NIC was on the same coherent fabric. If AMD intends to extend its AI training clusters via Ultra Ethernet, then instead of having to go CPU/ GPU to PCIe with RDMA transfers over the PCIe Ethernet NIC, imagine having the XGMI NIC sitting on the Broadcom XGMI switch with the CPU and multiple GPUs. That is a fascinating concept.
Final Words
While this is some future technology, AMD needs it. Its story of scaling beyond 8-GPU machines is Ethernet. Ultra Ethernet will help, but our best guess is that with the consortium forming in 2023, we are still some time off until Silicon on that side. AMD’s 2024 sales forecast of $2B (credit Max at Reuters) feels very low. AMD is shipping MI300X systems from some OEMs this month, and we expect at least one OEM to have $300M+ of MI300 bookings before Christmas 2023 and those systems are not for Microsoft. If AMD can deliver the MI300X chips, it is going to blow out a $2B forecast in 2024.
With so much hardware being deployed, we hope Broadcom can deliver its next-gen Infinity Fabric PCIe switch sooner rather than later.



{kind=link}
Excellent. This cannot happen fast enough.
Cache-coherence over ethernet is, of course the Grand Dream.
Latency is the first worry. When a GPU or CPU does a load-miss to a remote line, how long does it take?
And does this work mean a public, interoperable protocol for doing MOESI over ethernet?
But the real question here is….
Will it blend?