
Next week, we have Hot Chips 34. On STH we are going to use HC34 instead of “Hot Chips 34” or Hot Chips 2022 just to save time in a mad rush for coverage. NVIDIA decided to get ahead of next week’s cycle by having an embargo today on next week’s disclosures at HC34. Although there were a few scheduled for today, we wanted to focus on the NVIDIA Grace Arm CPU details. These are perhaps the most interesting.
New NVIDIA Grace Arm CPU Details Ahead of HC34
With today’s embargo lift, we have a number of new disclosures around the NVIDIA Grace CPU. Perhaps one of the most interesting is that we now get a basic floorplan. Here is the basic diagram for a NVIDIA Grace CPU:
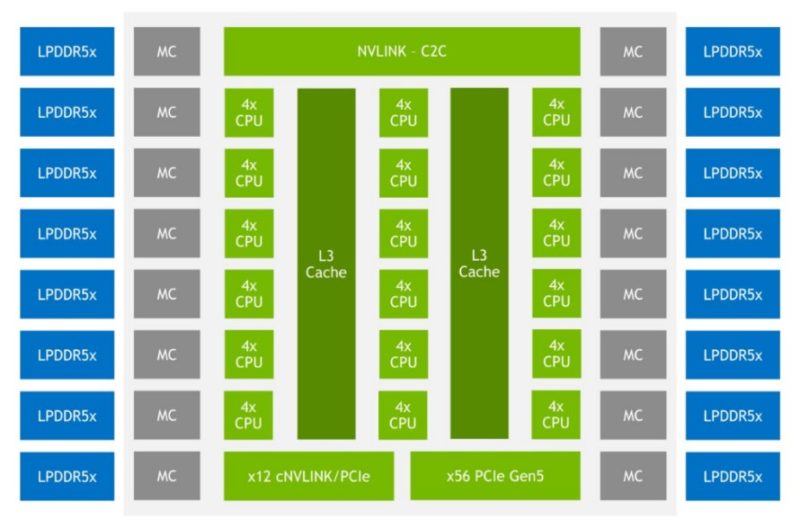
NVIDIA says that the new Grace CPU will be based on Arm v9.0 and will have features like, SVE2, virtualization/ nested virtualization, S-EL2 support (Secure EL2), RAS v1.1 Generic Interrupt Controller (GIC) v4.1, Memory Partitioning and Monitoring (MPAM), System Memory Management Unit (SMMU) v3.1, and more.
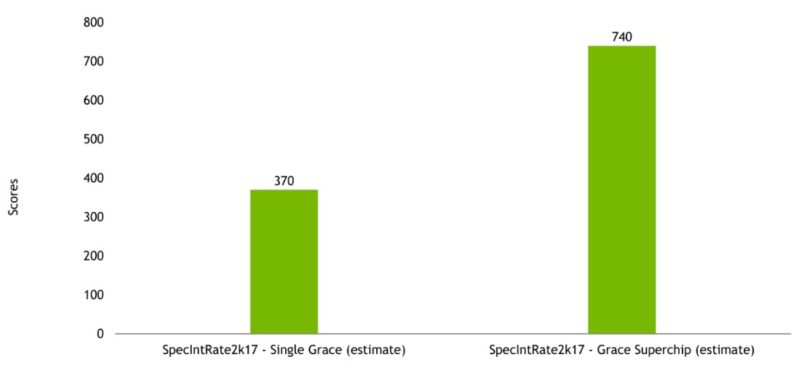
NVIDIA also shared that it expects the new 72-core CPU to hit around SPEC CPU2017 Integer Rate scores of around 370 per full 72-core Grace CPU using GCC. For some context, a 64-core AMD chip will have official scores in the 390-450 range (e.g. an AMD EPYC 7773X.) With two Grace CPUs on a module, we get the Grace Superchip that would effectively double these numbers.
That is really only part of the equation when it comes to Grace. Grace is not designed for all-out CPU performance. Instead, it is designed for memory bandwidth, power efficiency, and coherency with the company’s GPU products. One can see the 16x memory channels on the Grace diagram above. The basic goal of Grace is to use LPDDR5x to get a HPC/ AI usable capacity. Then NVIDIA will use many channels to get a lot of bandwidth. A few quick notes here, and big ones, are that AMD will have a 12-channel DDR5 controller with Genoa so the total capacity and bandwidth should be proportionally higher than the 8-channel below. The Genoa part will trade power consumption for serviceability and greater capacity. HBM2e is very expensive, but it provides a lot of bandwidth at the cost of capacity.
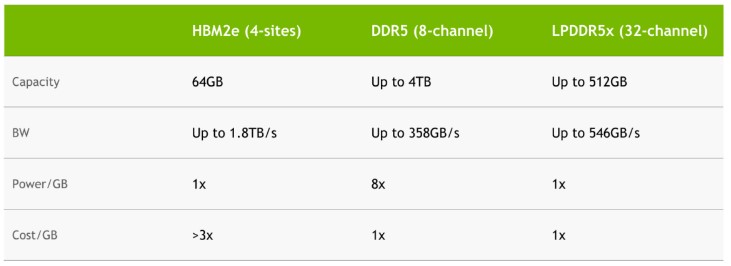
The above seems very focused on Sapphire Rapids HBM discussing four sites HBM and 8-channel DDR5. We showed this with Intel Sapphire Rapids HBM at Intel Vision 2022.

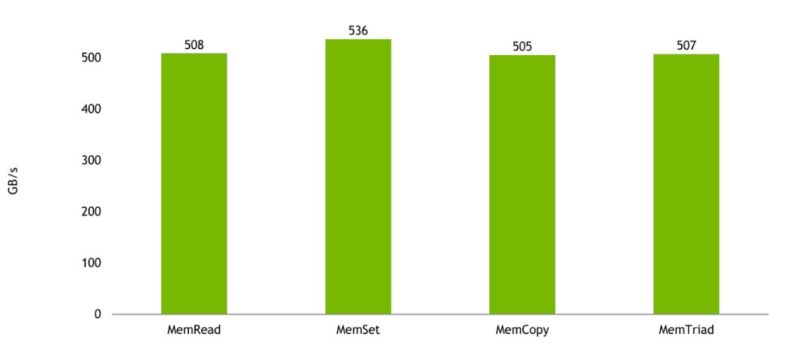
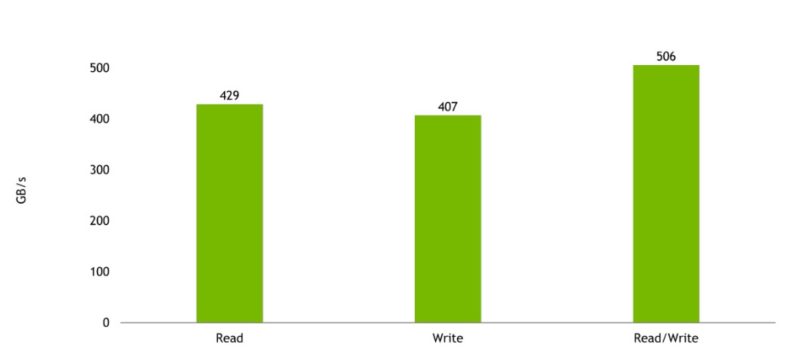
The big benefit is really the memory bandwidth. Here are the estimated memory bandwidth results for a Grace CPU (single CPU, not the Grace Superchip):
Perhaps the bigger pull for NVIDIA is the ability for a Grace CPU to have a coherent link between CPU and GPU using NVLink and over a NVSwitch fabric. NVIDIA is basically building a high-performance fabric that the rest of the industry will match at some point. NVIDIA is just doing it now. Using NVLink-C2C the company gets up to 900GB/s with “5x the energy efficiency” versus PCIe Gen5. A big part of that is that PCIe Gen5 is also designed to span longer distances than just an on-package interface.
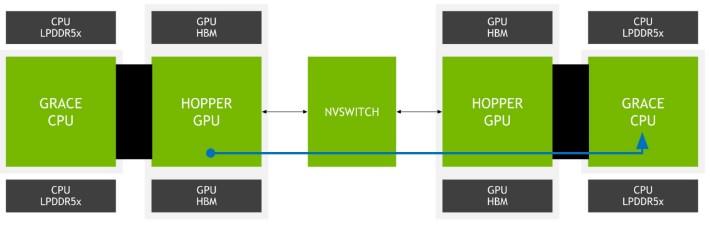
NVIDIA’s plan is to use these complexes to have up to 1TB/s of bandwidth on a package with just LPDDR5x on the Grace Superchip or more with the Grace Hopper solution. The company is showing just a Grace to Hopper interconnect will have an estimated combined bandwidth of over 500GB/s. While there is a penalty for going to the Grace CPU’s larger 512GB memory footprint, NVIDIA seeks to minimize the impact.
NVIDIA also showed a bit more on how the company plans to scale designs. Using the NVIDIA Scalable Coherecy Fabric, NVIDIA hopes to get up to 4-socket coherency and 72 cores/ 117MB of L3 cache (1.625MB/ core.)
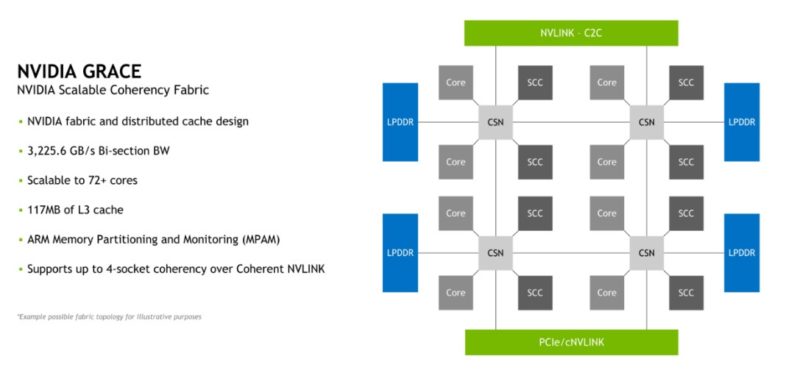
The company also said that there are up to 68 lanes of PCIe connectivity. We can see that there are 56x PCIe Gen5 lanes plus twelve more that can be PCIe or cNVLINK.
Overall, this is a very exciting design.
Final Words
There are really two reasons NVIDIA is building its own CPU. First, NVIDIA wants something that is a more efficient co-processor to the company’s GPUs in large systems. NVIDIA owns the hardware/ software stack much like Apple, so this is an attempt to become a truly full-stack provider. NVIDIA does not need Intel/ AMD’s new AI accelerators, it has its own. Likewise, it can build a chip with the right performance attributes to augment a GPU, rather than duplicating other parts.
The second reason is more obvious now. NVIDIA needs to de-couple itself from Intel and AMD. Both are competing with NVIDIA in HPC and AI. At the same time, the Hopper H100 is waiting for Sapphire Rapids to launch before the DGX H100 can launch. As a result, we are expecting a mid-to-late Q1 2023 debut for Hopper. Given that the chips exist, (see below) NVIDIA needs a CPU solution so it can sell its GPUs.

We will have more on the NVLink and other announcements as part of our HC34 coverage next week. Get ready for a lot of new content on STH Sunday through Tuesday (and likely Wednesday) as a result.



{kind=link}
Makes sense that they are so heavily focused on memory bandwidth. Anecdotally many of our compute intensive workloads spend between 60% and 70% of their time in memwait cycles. Higher bandwidth and direct to GPU transfer is therefore likely much more beneficial than another 15-20% raw compute uplift.