
Apple just did something that AMD, Intel, and perhaps especially NVIDIA should take notice of. It launched new systems with updated chips and ton of unified memory. The new Apple Mac Studio M3 Ultra can be configured with up to 512GB of unified memory and there is also a M4 Max option. In our chats, Patrick has been asking for high-memory capacity SoCs for a few quarters now, and when I got sent this announcement today, I knew he already had one on order.
New 512GB Unified Memory Apple Mac Studio is the Local AI Play
Somewhat confusing is that Apple has been rolling out the M4 series for some time. We reviewed the Apple Mac Mini M4 quite some time ago. The Mac Studio is getting the M4 Max, but it is also getting the M3 Ultra. The M4 Max goes up to a 40-core GPU and 128GB of memory, which is going to be a great platform for folks. The M3 Ultra, however, will have 256GB and 512GB shared memory capacities and up to an 80-core GPU.
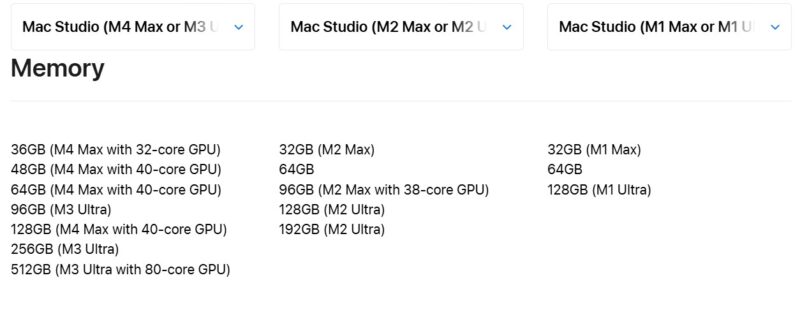
Of course, since this is apple, expect everything to be very pricey when it comes to options. Even with a paltry 1TB of storage, the 512GB model will set you back $9,499.
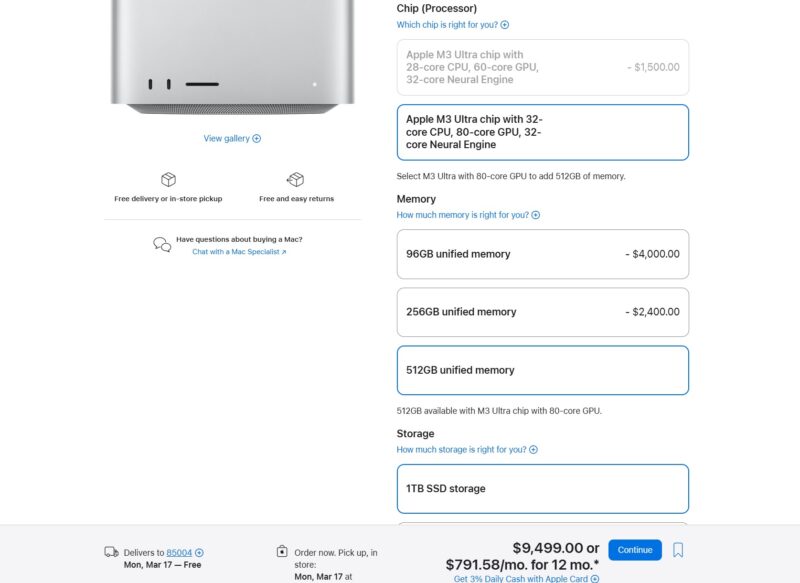
It is a shame that Apple still charges a lot on top of this for storage, but with Thunderbolt 5 and 10GbE, picking the $4600 16TB storage upgrade (we are not kidding there) is probably going to be one that many will skip in favor of network storage.
Final Words
I will let Patrick do the Final Words for this one. -Cliff
Editor’s Note: Apple is charging a huge amount for its systems at just under $10,000 (before tax) for a system configured with a modest 2TB of storage and 512GB of unified memory. At the same time, we have been running Deepseek-R1 671b on AMD EPYC systems for an article and video coming soon. The idea that you can run a big model like that on a system that is $10000 without having to get into the complexities of clustering should be a big deal to folks. Remember, a NVIDIA RTX 6000 Ada is $8999 (here is a B&H Affiliate link to the PNY version.) So for a few hundred dollars more, you get an entire system with the ability to do Thunderbolt 5 (120Gbps) clustering. That $8999 RTX 6000 Ada is a 2023-era part with only 48GB of memory, so Apple is offering a 10x memory footprint. One can, of course, point to the fact that the RTX 6000 Ada is a huge GPU, but the memory bit matters. We are going to talk about this a lot when we talk about running big AI models on EPYC soon, and in a very different context than others have previously.

I have told AMD’s server team they need a Strix Halo server part. Intel needs the same. NVIDIA has DIGITS. Still, Deepseek-R1 671b, or that class of models, running locally is great. We have a Framework Desktop with 128GB on order, and it is not a surprise the 128GB model is the most popular. The unified architectures for so long have been focused on lowering costs. As performance is ramping up in that segment, simply having access to a large memory pool becomes an almost binary yes/ no function to running higher-end workloads. The cost is high in the context of a workstation, but it is cheap when you compare it to NVIDIA’s cost per GB of memory.
I have a very strong feeling that the unified memory SoC model is going to be one that is going to be an enormous market in the future. For AMD and Intel, perhaps the challenge is that they have been looking at this market as a low-cost leadership segment for too long.
Some may find this a coincidence, but the March 17, 2025 date for the 512GB M3 Ultra model just happens to be the first day of NVIDIA GTC 2025.



{kind=link}
Two of them with exo and thunderbolt connection and you have enough RAM to run all LLM with 16 bit.
How it works? Use this https://github.com/exo-explore/exo
You find many hints on X for Clustering Mac Mini M4.
Yes. I’d be interested in what AMD concocts with the desktop version of Strix Halo (although it is slated to be available in SFF desktops like the the HP Z2 G1a or the Framework desktop.
Deepseek r1 is sooo January. Qwen just released the QwQ-32B (not Preview) today and it matches or exceeds R1 at 32B: https://qwenlm.github.io/blog/qwq-32b/
TB5 networking is 64gpbs bidirectional, full duplex. The 120gbps marketing figure is one way downstream “bandwidth boost” mode when pushing multi monitor and it dynamically cuts bandwidth upstream to 40gbps in this mode. 120×40 is great for laptop docks, but networking is 64×64. 80×80 even still is 64×64 for data/networking/pcie. The other 12×12 is reserved for video. 64gbps is PCIe 4.0 x4, which is what TB5 essentially is.
For that price an M4 Ultra would be great, but with no UltraFusion connectors on the M4 Max chip it’s impossible to merge two fourth-generation chips to create an M4 Ultra.
with 2 VM limits ROTFL
Remember that running an LLM on 512GB will require 4x the bandwidth than running a model on 128GB to maintain iso token/s. So even if the M3 Ultra is impressive, so will your patience need to be when it comes to waiting for answers.
And then I simply don’t get the hype: All the models I’ve been able to run on my RTX 4090 have halucinated so badly, that they simply aren’t worth the bother.
@Cliff Robinson: Thunderbolt 5 is not a protocol but rather, a multiplexing technology. It offers 80 Gbit/s bidirectional or 120 down / 40 up for USB and/or DisplayPort traffic only. Anything using PCIe tunneling, incl. IP networking, is constrained by the PCIe 4.0 x4 back-end, i.e. 64 Gbit/s, less if the other protocols are together already using more than 16 or 56 Gbit/s (depending on mode) of the available total in that direction.
@anufrejoval: Hallucination is a consequence of poor accuracy, i.e. insufficient parameters and/or excessive quantization, i.e. insufficient GDDR capacity on your 4090. A computer with a lot of DDR or LPDDR memory with high – but not extreme – bandwidth to the GPU / NPU cores lets you run a better model but at reduced speed. Maximum performance in both respects requires a large amount of very expensive HBM memory.
Btw: In practice, according to Alex Ziskind on his YouTube channel, only about 75% of the uniform memory bandwidth on an Apple system is actually available for the graphics cores. This can be tweaked but any more and the operating system running on the CPU cores may become unstable, YMMV.