
While MLPerf Training is largely NVIDIA’s benchmark, the MLPperf Inference is more interesting. The MLPerf Inference v2.1 results this time included a number of new technologies including Intel setting a floor for next-generation AI inference accelerators and new accelerator options from NVIDIA, Biren, Moffett, and others.
MLPerf Inference v2.1 Results Preview Next-Gen AI Tech
We are going to focus on the MLPerf Inference v2.1 Open datacenter and Closed datacenter results. There were a number of interesting solutions in the Open category.
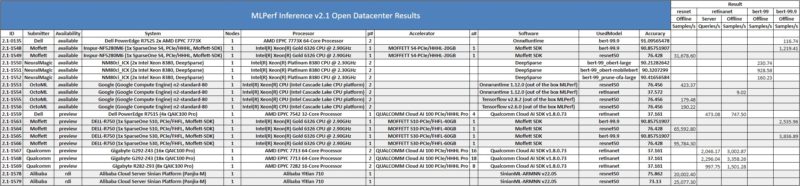
In the latest Open Datacenter category, there are the Alibaba Yitian 710 chips. These are the new Arm CPUs we covered previously. In the open category, these do not need to do the same math, so one cannot compare them to the closed category, but it is still an interesting result.
The other interesting one here was the Moffett S4, S10, and S30 PCIe accelerators. Here is a look at the S4:

Moffett leverages sparsity in its design, like many other solutions, so that may be why they are in the open category not the closed category because there is more leeway on how that can be leveraged in the open category.
Turning to the closed category, we saw a number of decent results, but there were some interesting ones.
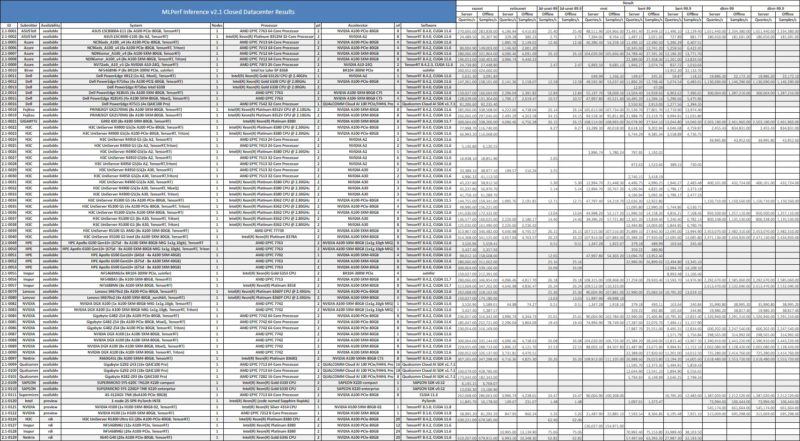
NVIDIA showed off the new H100. NVIDIA’s results tend to get much better over time, so the new results using a Xeon Silver 4314 and a EPYC 7252 look good at this point.

One of the interesting results was the Sapeon X220. These were fitted to Supermicro servers and are some of the older generation technology to be tested with MLPerf Inference this time. Still, it is interesting to see this hardware.

The Biren BR100 “BR104-300W PCIe” made an appearance on the list in an Inspur NF5468M6 server. The 8x PCIe solution looks as though it is going to end up somewhere between the NVIDIA A100 and H100 which is quite amazing for a first GPU-architecture accelerator. It makes one wonder a bit how Biren was able to do this so quickly versus companies like AMD and Intel. The company only submitted ResNet and BERT 99.9 results, but they are certainly promising.

Intel for its part set a floor for next-generation inferencing. The Sapphire Rapids 2-socket result used PyTorch, but it also showed inference performance in-line with a NVIDIA A2 or higher depending on the benchmark. Intel did not submit for all tests, but the implication is that with the next generation of acceleration, the old model of deploying a 1U server with a single <60W PCIe inference accelerator just to get some inference capabilities may be sunset. While one can scale PCIe and other form factors to higher performance per system, having inference acceleration in every CPU is a big deal. That is part of the reason we called More Cores More Better AMD Arm and Intel Server CPUs in 2022-2023.

Qualcomm was back at it with the Cloud AI 100. Qualcomm says that there is a lot of demand. From what we have seen, server vendors want their servers reviewed with NVIDIA, some with AMD GPUs, but we have yet to get a request to test a Qualcomm-based solution. Usually what we see is an indicator of market momentum. We saw a lot of EPYC interest with the Rome generation just as that took off as an example.

An honorable mention we wanted to point to was the NVIDIA Jetson AGX Orin, especially in the Closed Edge category.

This is one we saw a few months ago, but in this generation, it was able to see a 50% performance per watt improvement.
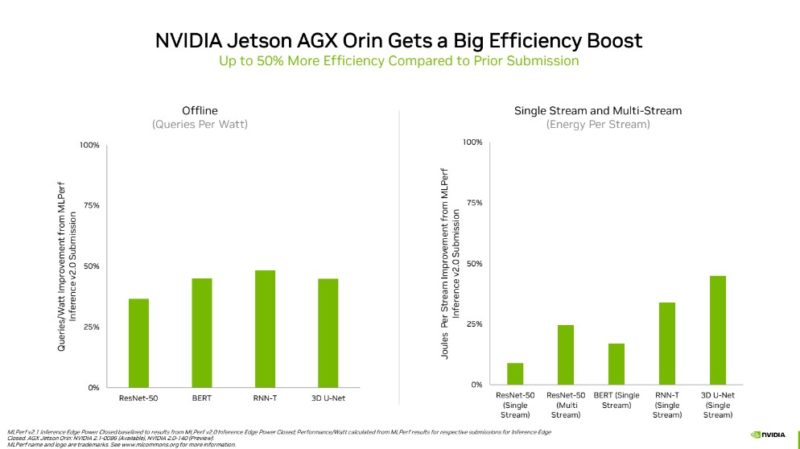
This is an example of NVIDIA’s software getting better over time.
Final Words
There was certainly a lot of interesting hardware in the MLPerf Inference. This may be a case where the Training side is less interesting, but the inference side is increasingly so. The theory is that the inferencing market will eventually be vastly larger than the training market, so perhaps that makes sense. If you do want to dig into the results, MLCommons publishes its full results online.



{kind=link}
The result in there from Biren are with BR104, not BR100. BR104 is basically half of BR100 in performance. I don’t believe the 8x BR100 accelerator is in production yet. only the 8x BR104 is going through testing/trialing with customers right now (Inspur in this case)
Interesting that there were 36 AMD systems vs. 33 Intel systems in the test…