
Today we have a new set of AI inference benchmark results in the form of MLPerf Inference V2.0. This iteration of the predominantly NVIDIA-led benchmark solution featured a lot of what we have seen from previous generations. The majority of data center results were NVIDIA GPUs, however, NVIDIA went the further step to use its Triton platform to submit results for competitive silicon from companies like Intel and AWS. The other big player is Qualcomm in this space, but they had a strange release cycle. Finally, we did see a handful of different results.
MLPerf Inference V2.0 Results Discussion
The overwhelming majority of results for MLPerf were systems based on NVIDIA GPUs. MLPerf is claiming many submitters, but realistically, most of the diversity in the benchmarks are now OEMs supported by NVIDIA using NVIDIA GPUs and submitting results. There are normally not huge differences in how NVIDIA GPUs perform in OEM systems with similar power and cooling, and that is exactly the point of NVIDIA’s software work. NVIDIA’s software goal is to ensure its GPUs perform optimally independent of the host system.
Qualcomm had a fairly significant number of results with the Cloud AI 100 cards and we were impressed with the number of submissions with five submissions for the data center closed and the closed power using Qualcomm chips. There were nine for the edge side. There were some oddities such as a Gigabyte server that appears to be submitted by Qualcomm and Krai and it was not immediately clear why there was a Krai submission as well. Qualcomm’s submissions usually focused on three of seven benchmarks while NVIDIA’s submissions tended to be all seven when testing its own hardware. Qualcomm for its part canceled its press briefing ahead of the results, so we are unsure how to read into that.
Some of the really interesting accelerators/ submissions included.
- AWS Inferentia was submitted by NVIDIA using the NVIDIA Triton platform
- Intel Cooper Lake and Ice Lake had submissions by NVIDIA using the NVIDIA Triton platform
- The Alibaba Yitian 710 made an appearance in the Alibaba Cloud Server Sinian Platform (Panjiu-M)
- There was a submission for the Neuchips RecAccel using the Terasic DE-10 Pro FPGA Acceleration Board submitted on a single result
- In the edge section we also saw a result for the FuriosaAI Warboy across three of the seven benchmarks
- The ODROID-N2+ made an appearance. This is an Arm part while we looked at the ODROID-H2+ with H2 Net Card for a cheap 6x 2.5GbE solution
- The NVIDIA Jetson AGX Orin made an appearance on this list as well
Comparing Qualcomm to NVIDIA is really hard. Qualcomm’s cards are much lower power than A100’s, but NVIDIA can split the A100 into seven MIG instances with very little performance loss over using the whole A100. Often for a small number of cards, when the A100 is underutilized, we see the Qualcomm Cloud AI 100 do well, but using MIG versus the Qualcomm card seems to tilt the balance the other way.
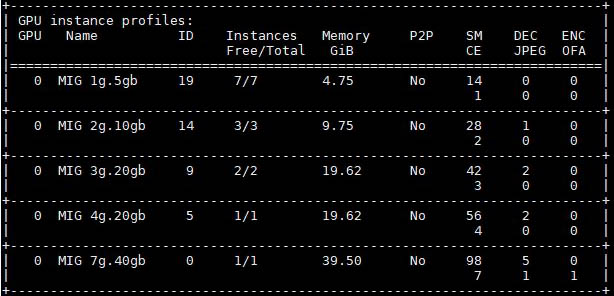
NVIDIA submitting competitive silicon in a number of benchmarks as it is saying that it is using its Triton platform is an interesting development. Intel, for example, did not submit in this round, so NVIDIA did it for them. The same with AWS and Inferentia. This is interesting because now NVIDIA has a way to get comparisons into MLPerf even without its competitors submitting. Since the benchmarking project does not require submission in every category, NVIDIA only submitted some benchmarks on its competitive products.

The other major loophole in the MLPerf Inference was discovered with this iteration. While vendors like Lenovo note when liquid cooling is used (and Lenovo submitted liquid cooled results), in theory, one could use an unmodified inferencing solution in an immersion tank and remove a large amount of power. In our recent Deep Dive into Lowering Server Power Consumption we found that 15%+ power of even standard dual-socket 1U and 2U servers can go toward spinning fans. For higher-end systems, this is even more. By using liquid cooling, or immersion cooling, companies can effectively reduce this part of power consumption to near zero. At STH we will have a piece later today showing how a liquid cooling system works, here is a preview from that with a CoolIT Systems CDU. The CDU may sit in another rack and would not be covered by the power meter used for efficiency results.

A similar CDU can be used with immersion cooling systems and unmodified systems can turn off fans via firmware and often be used, especially with lower power inferencing parts.
Perhaps the most interesting result of the entire V2.0 exercise was the NVIDIA Jetson AGX Orin versus the Xavier generation.
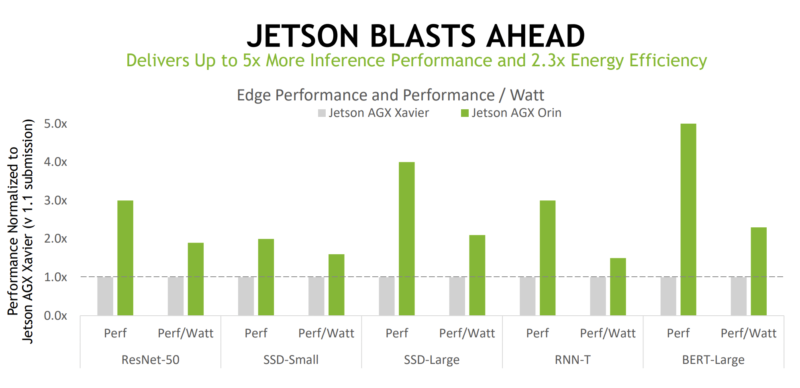
Not only is the Jetson AGX Orin faster, but it is providing better performance per Watt. We will also note that the ResNet-50 is an older model while BERT would be more of a modern model where there is a lot of investment. The BERT results were significantly better. As you can tell from the cover image, we have an Orin developer kit and will have a review of it coming soon.
Final Words
A critique we often have of MLPerf results, including these MLPerf Inference V2.0, is that it is very NVIDIA heavy. That is both with NVIDIA submitting results as well as it enabling partners to submit results. This time, Google decided not to participate. Intel did not participate, although NVIDIA submitted CPU results for Intel hardware. Qualcomm participated, submitting a few configurations on almost half of the benchmarks. We also saw a few interesting results from sporadic submissions of unique hardware on subsets of the overall benchmark suite.
A big part of this is that NVIDIA has a huge software ecosystem and revenue stream from AI. NVIDIA can invest resources in optimizing results and enabling partners. MLPerf is effectively a NVIDIA benchmarking exercise, and that is not a bad thing. We can see some interesting results like the Jetson AGX Xavier to Orin performance and power efficiency changes.
Perhaps that is how we will start to view MLPerf in the future. It is a useful tool to compare NVIDIA generational results and similar NVIDIA configurations. NVIDIA will also use it to benchmark its competitors and show selected results from those tests.



{kind=link}