
MLPerf Inference v1.1 is out marking the second release of this year. One of the biggest challenges covering MLPerf is that the benchmark suite changes, tools change, and those happen at rates faster than the underlying hardware changes. Still, We wanted to at least give some discussion of the new results.
MLPerf Inference v1.1 Results Discussion
We are going to focus broadly on the data center and edge categories. There was not much on the edge side in terms of system diversity, so most of our discussion is going to be around the data center.
MLPerf Inference v1.1 Data Center Category
The closed data center category was a bit more interesting than usual. NVIDIA, and through its partners, had not just A100 PCIe/ SXM4 and 40GB/80GB submissions, but there were some new results as well. We saw the NVIDIA A10 and A30 get included this time. Perhaps the most interesting results were that NVIDIA used the 80 core Ampere Altra and saw a very similar performance to its Intel results. Strangely, this was listed as “Arm Neoverse-N1” as the CPU in the Processor label, even though that is the core generation, not the processor. Given MLPerf prides itself on peer-reviewed submissions, this just looks strange.

Of course, NVIDIA announced plans to acquire Arm so it almost feels like this was being done to promote Arm rather than recognize the actual Ampere Altra chip being used. Ampere takes the Neoverse N1 cores and has to put important features such as memory controllers and PCIe controllers around it so that it can do simple things like run an operating system and link to the NVIDIA A100 GPUs.
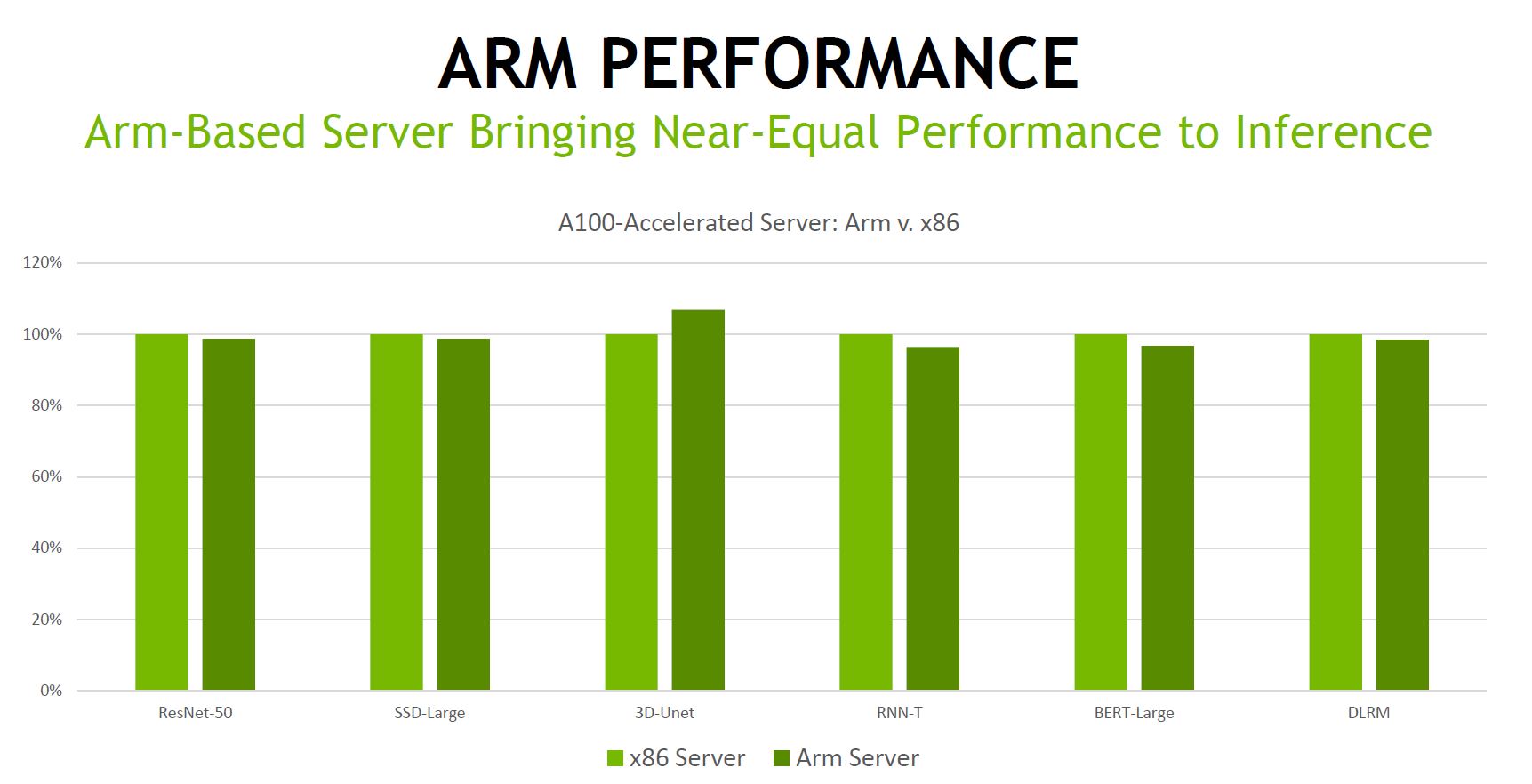
The Ampere Altra based system did extremely well, nearly rivaling x86 performance. While it is cool to see these results, seeing something that looks like it is going against data standards being offered by NVIDIA feels out of place, especially since MLPerf is often seen as a very NVIDIA-focused effort.
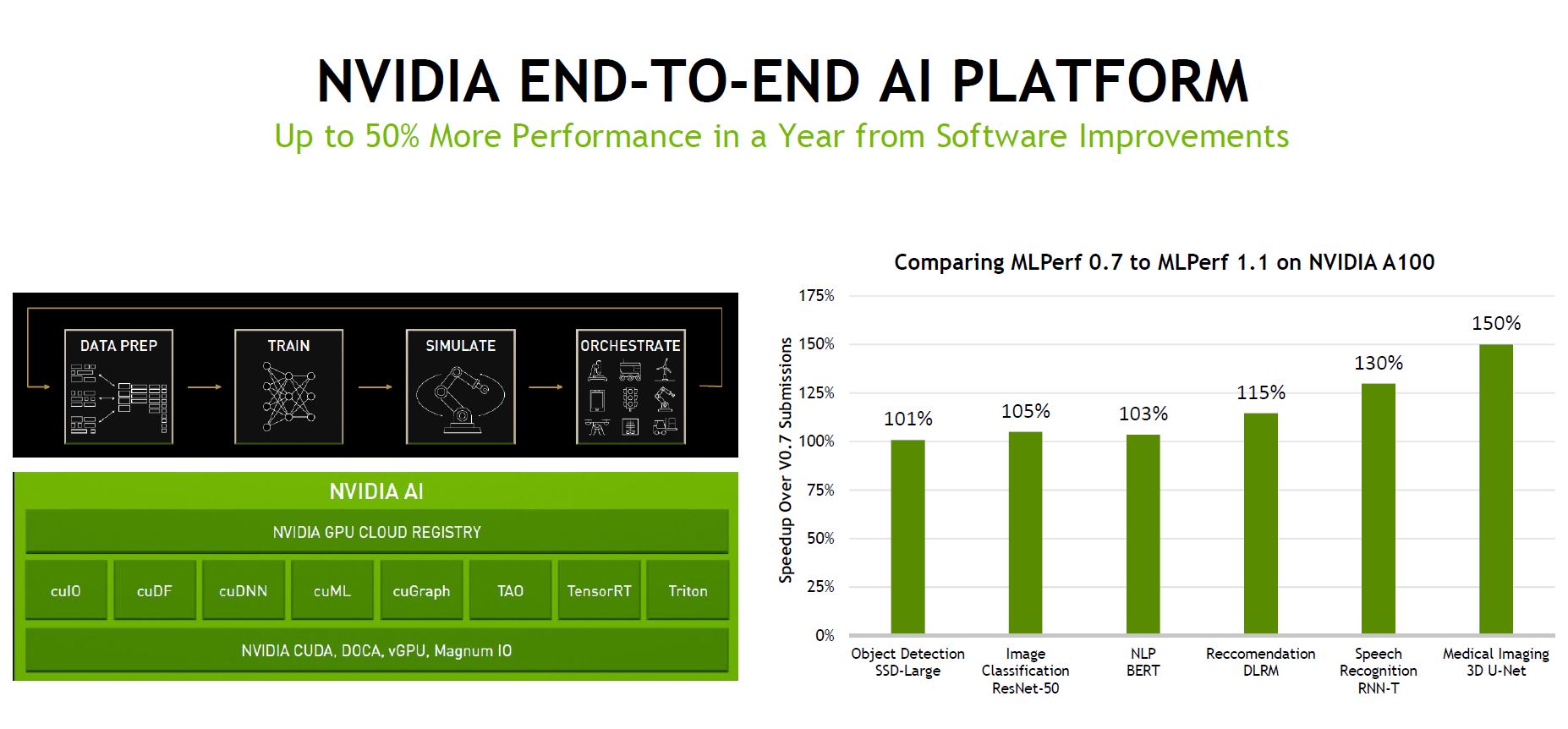
Overall, we got another generation of software lift from NVIDIA (and its partners that NVIDIA helps submit results leading to the MLPerf results being highly NVIDIA focused.)
Qualcomm has its AI 100 accelerators out although only submitting on the resnet, ssd-large, bert-99, and bert-99.9 tests, or completing just under half the suite. Overall, Qualcomm did well, but it ended up making some very strange comparisons. Here is an example:
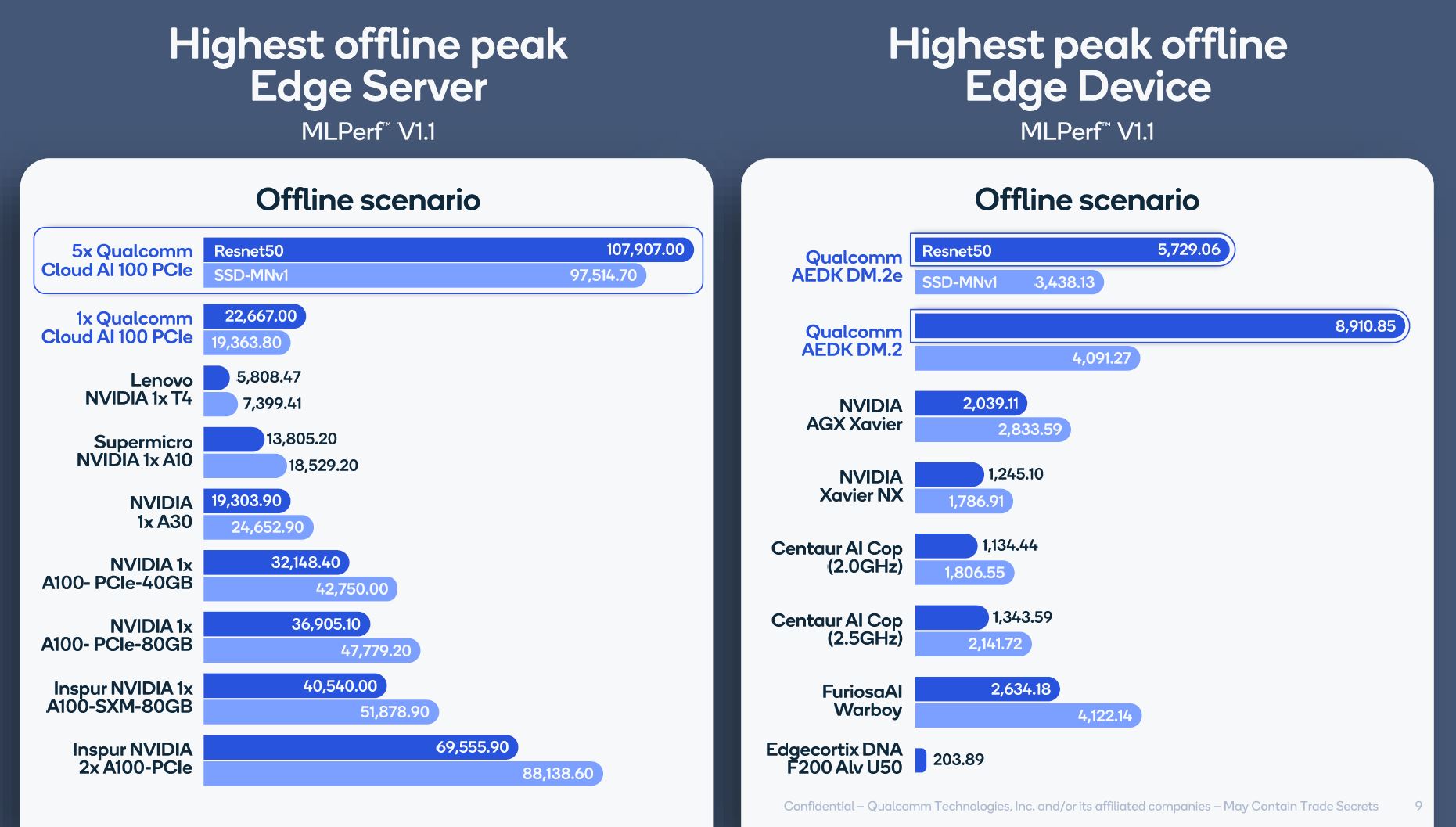
Here is another look:
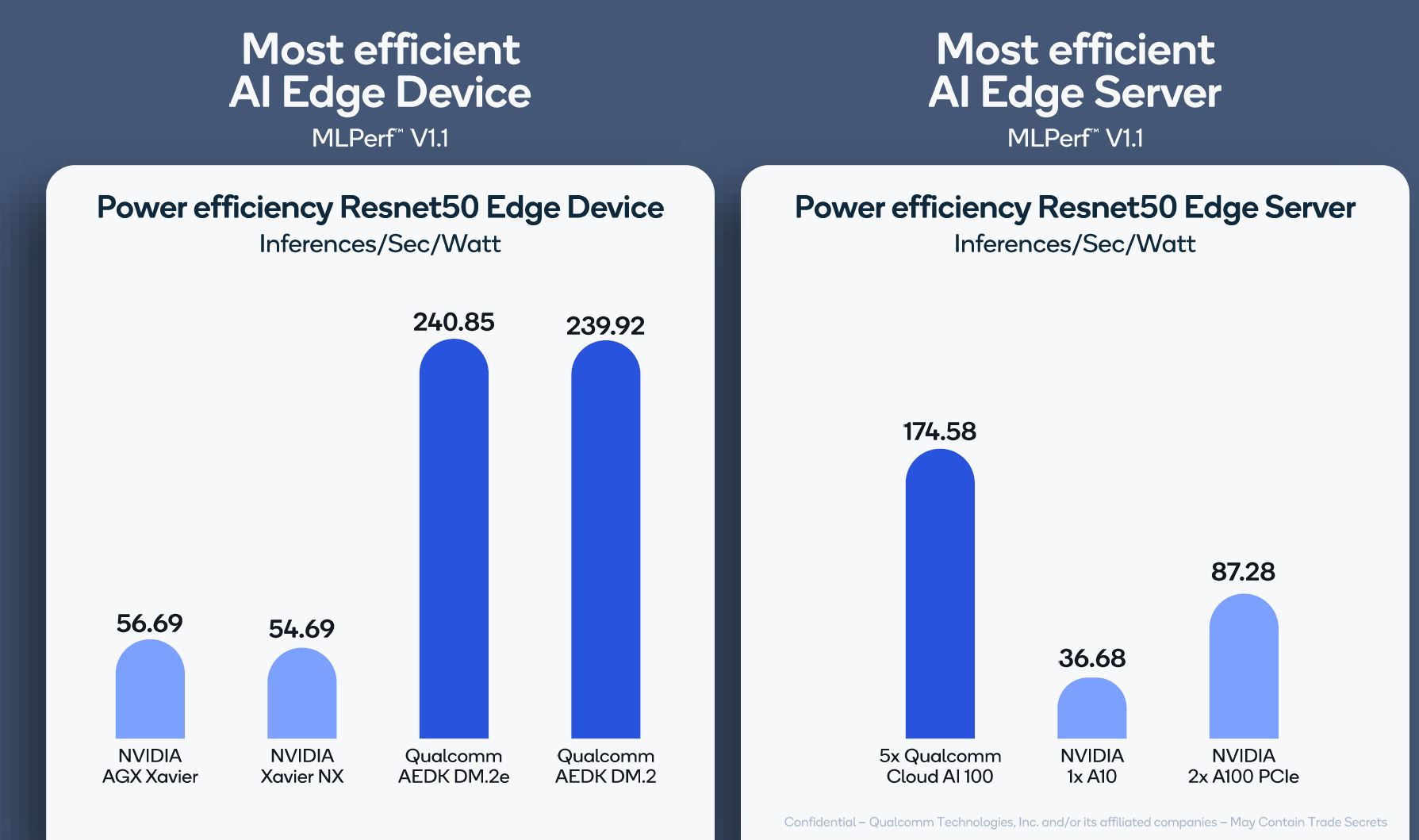
Qualcomm is really focused on its energy efficiency.
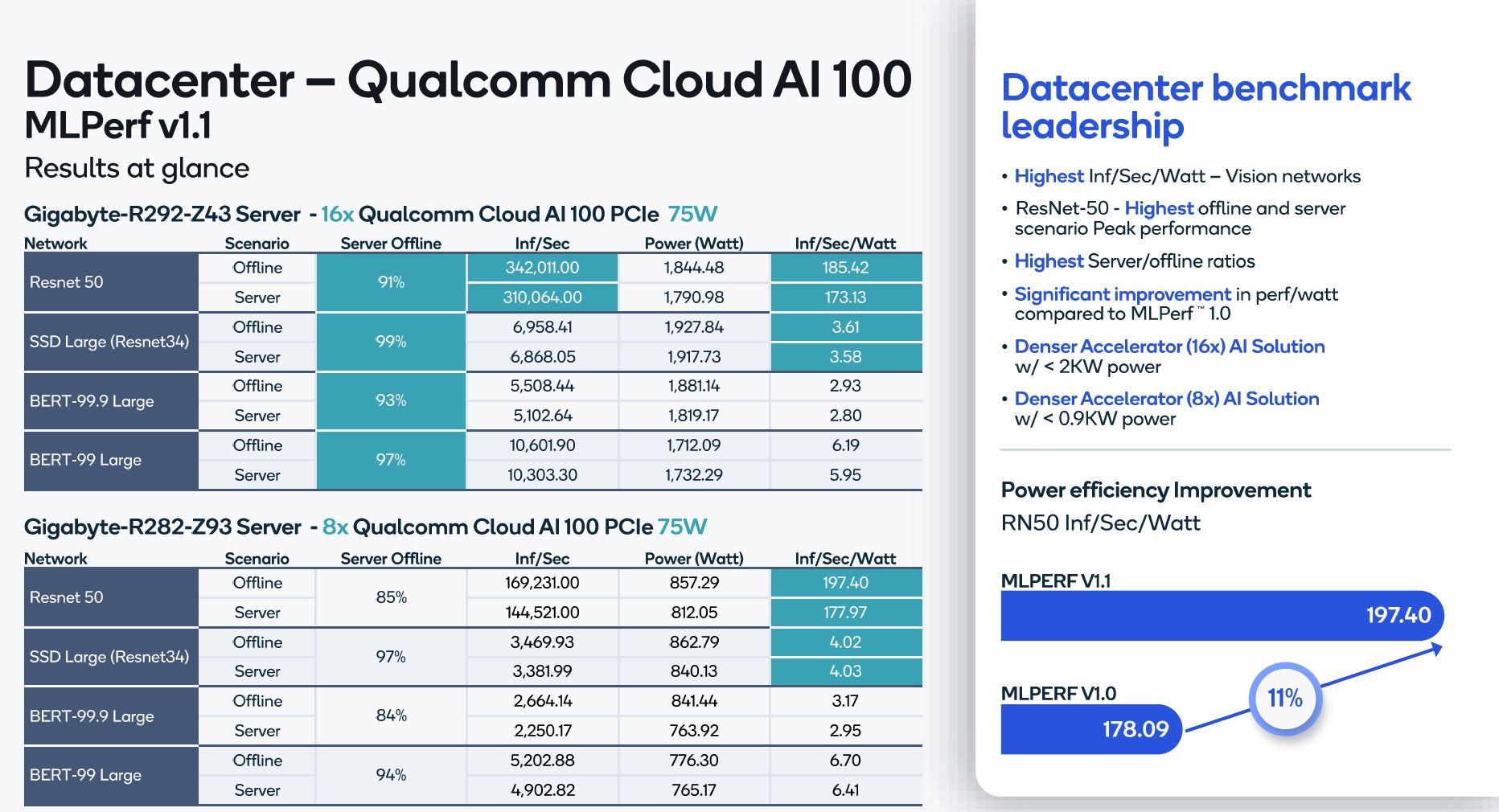
Sitting through the briefings, Qualcomm said that its inference AI 100 card was more efficient than 400W/ 500W NVIDIA A100’s. That was very bizarre in terms of comparison. Qualcomm was comparing an inference-only part to more training-focused cards from NVIDIA.
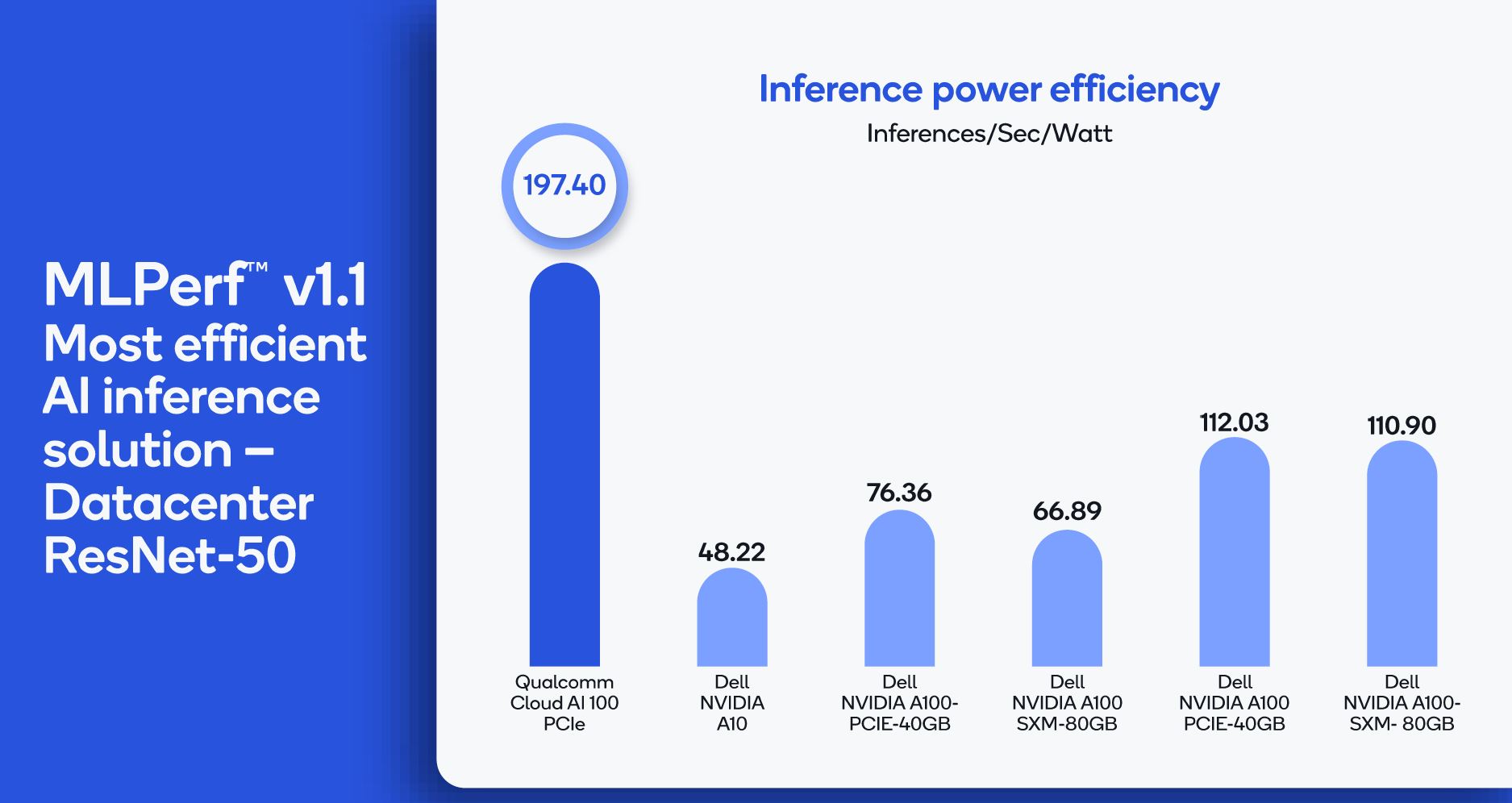
Part of the challenge here, and that STH pointed out since we have hands-on with these cards and most of the press/ analysts on the pre-briefing calls do not, is that the NVIDIA A100 running inference is very inefficient. MLPerf uses wall power and so having a high-end GPU with NVLink fabric sitting relatively idle during MLPerf Inference testing is somewhat of a strange comparison.
We note this whenever we do large GPU servers such as the Inspur NF5488A5 or recently the lower-end Dell EMC PowerEdge XE8545 we reviewed and where the 80GB model was used for comparison above.
The NVIDIA A100 has the ability to split into up to 7x MIG instances. Here is a screenshot of what this looks like on the 40GB A100 card in an ASUS server:
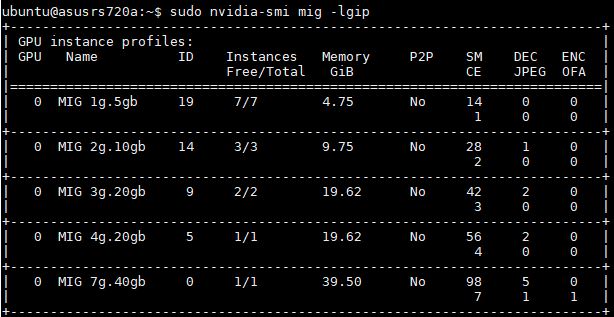
NVIDIA publishes MIG benchmarks in some areas, but it can run the entire suite, with two ResNet instances on the same NVIDIA A100 concurrently, and still get 95% of the single instance performance. This is due to overhead.

Since the A100 can run the MLPerf Inference benchmarks 7 at a time at 95% performance each, this is effectively like 665% of the performance of a single instance using the same hardware. So one of the strange things was that Qualcomm was claiming its inference-focused accelerator had better performance per watt than a very low utilization A100. Qualcomm was calling this a 400W/500W GPU, but when we run ResNet-50 on the PCIe or SXM4 GPUs, they run at relatively low power just because utilization is low. These are training cards.
Of course, the onus is on NVIDIA to provide power consumption figures with MIG for Qualcomm to compare to. The challenge is that running multiple workloads like this concurrently does not really fit into the MLPerf model. The even stranger part is that NVIDIA is getting that 95% result running DLRM, 3D-UNet, and RNNT, concurrently. These are all tests that Qualcomm did not even submit results on. It just shows some of the wacky world of MLPerf claims just due to the data sparsity in results.

Still, it will be exciting to see Qualcomm AI 100 cards hopefully make it to servers we review since we have done so many A100 systems from 6-10 different server vendors over the last two quarters.
Intel, for its part, had some Cooper Lake and new Ice Lake results. The reason Cooper Lake was used was specifically for bfloat16 with rnnt. Intel again is discussing its inference improvements in Ice Lake. Ice Lake is still far behind in terms of absolute performance, but Intel’s value proposition is that if one only needs a certain amount of inference performance as part of the overall application, then it can simply be cheaper to do it on the CPU without even adding an accelerator.
We are just going to note that most of the results in the Open Datacenter category were a handful of cloud instances. All of the open datacenter category results were Intel Xeon Ice Lake and Cascade Lake-based while the other categories for data center were roughly half AMD EPYC based.
MLPerf Inference v1.1 Open Edge Category
One of the big challenges is just sifting through the data. For example, the open,edge,power results had 94 submissions by Krai using the NVIDIA Jetson AGX Xavier using TFLite v2.5.0. In the open,edge category, Krai submitted 282 of the 286 benchmarks using the Jetson AGX Xavier, Raspberry Pi 4, and Firefly-RK3399 (firefly). There were three submissions of AWS c6gd.xlarge by cTuning that are not really competitors to the small edge boards that Krai submitted. Then we had a FPGA-based result on a Core i5 platform from Edgecortix.
A FPGA result, high-volume low power edge boards, and AWS cloud instances are very hard to compare logically.
Final Words
One of perhaps the challenges is that MLPerf Inference v1.1 is showing some changes, but it also feels like a smaller version of MLPerf Inference v1.0. Perhaps the bigger challenge is that we often experience inference at the edge. In terms of number of devices, inference at the edge will have to be bigger than inferences in the data center just simply due to the amount of compute required to ensure backhaul bandwidth is not overrun. Since MLPerf is so NVIDIA-focused at this point, the most diverse set of results is coming from the data center categories instead of the edge.



{kind=link}
So here is a big surprise, ARM servers and x86 servers do have -+ same performance when running MLPerf on the *same* NVidia GPU cards attached to the system.
Or do I interpret first paragraph with first table/picture in a wrong way?
nVidia A100.
Qcom AI100.
Uh huh.