
Today at Hot Chips 2024, Meta is giving a presentation about its next-generation MTIA. This is a processor designed specifically for recommendation inference.
Please excuse typos. These are being done live during the presentations.
Meta AI Acceleration in the Next-Gen Meta MTIA for Recommendation Inference
Meta does a lot with AI. One of the big applications for AI inside Meta is recommendation engines.
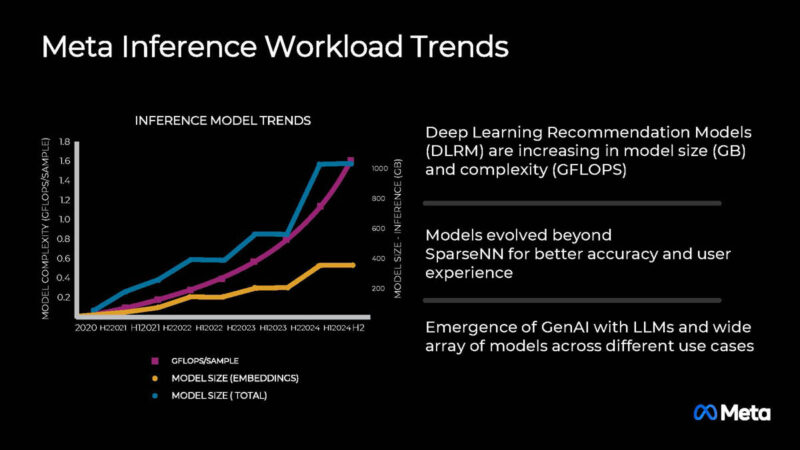
The company says that using GPUs for recommendation engines has a number of challenges.
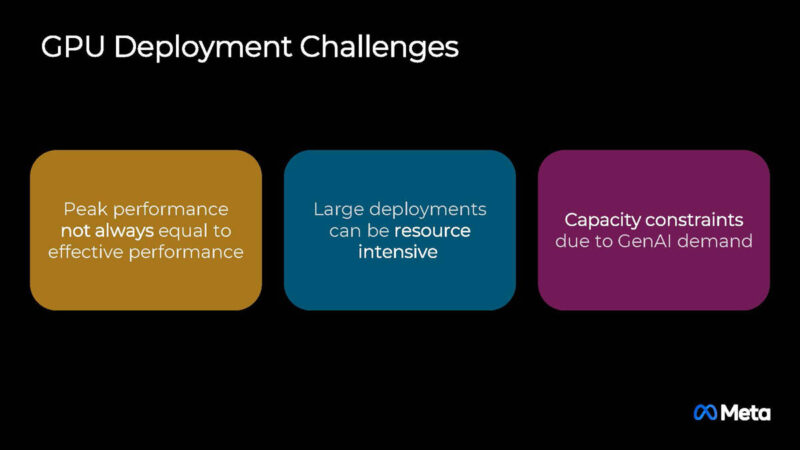
As a result, the next-gen MTIA was designed to have better TCO and handle several services efficiently.

Here are the key features of the new MTIA. The company has increased the compute significantly in this generation.
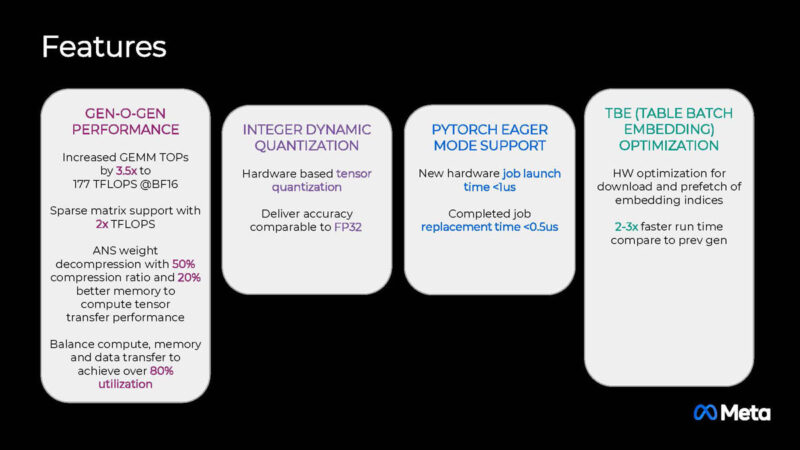
The new chip is built in TSMC 5nm and runs with a 90W TDP. The other interesting aspect here is that Meta is using LPDDR5 here for the memory. Even though this is a lower TDP device, because it is designed for recommendation engines, it also has 128GB of memory.

Aside from the 16 channel LPDDR5 128GB memory, there is also 256GB of on chip SRAM for the 8×8 compute grid.
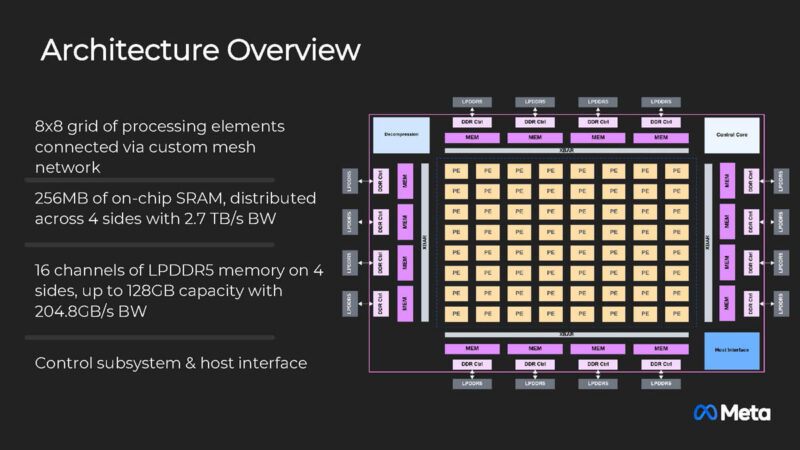
Each accelerator uses a PCIe Gen5 x8 host interface and is using RISC-V for control. It is interesting that not only is Meta not using a GPU here, but it also is using RISC-V instead of Arm.
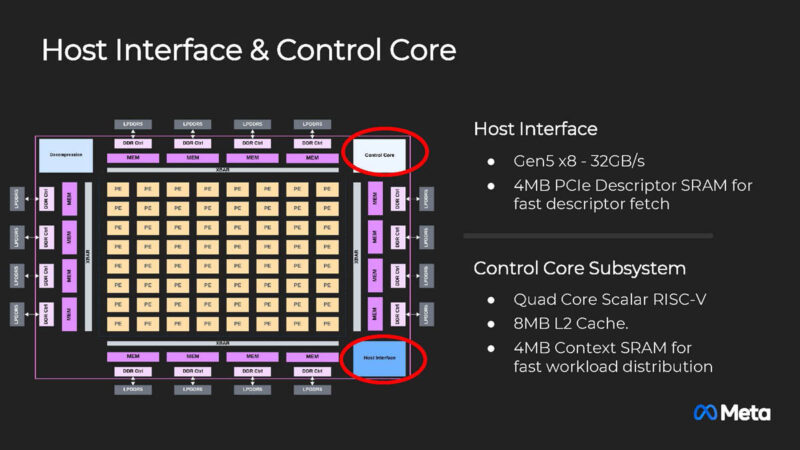
The new Network-on-Chip or NoC is faster than the previous generation.

The Processing Elements are based on RISC-V cores with scalar and vector. What is at least somewhat interesting here is that you can see some similarities between this and the Tenstorrent Blackhole RISC-V approach.
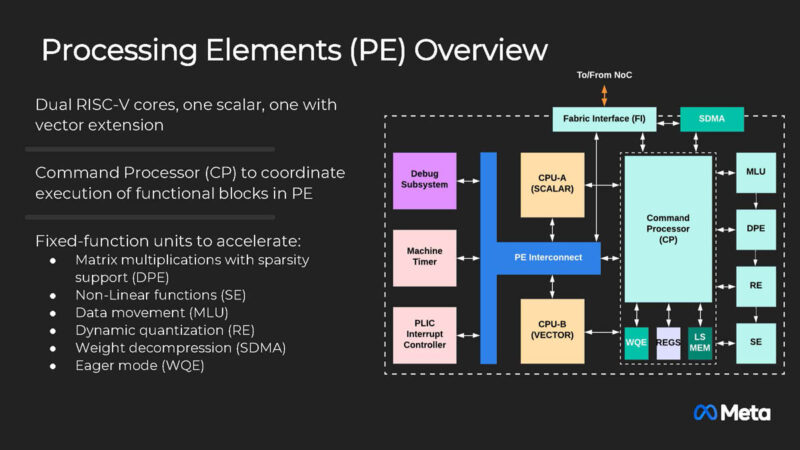
There is also a dot product engine or DPE.
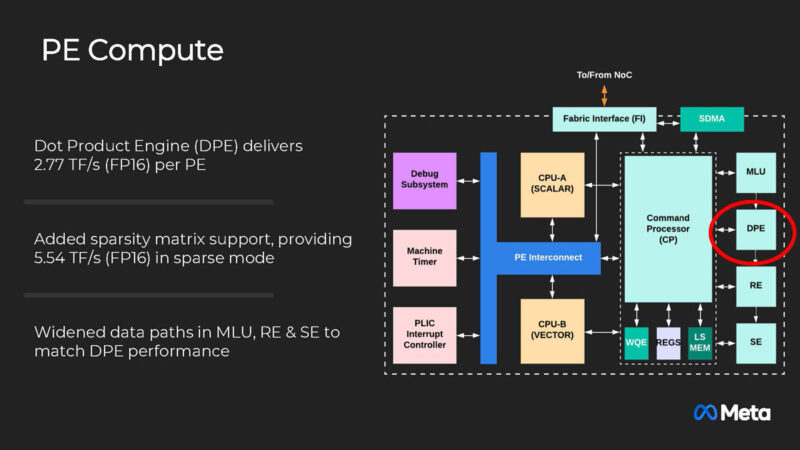
The local memory is 384KB. Meta said that working on memory and internal bandwidth is important to keep the compute utilized.
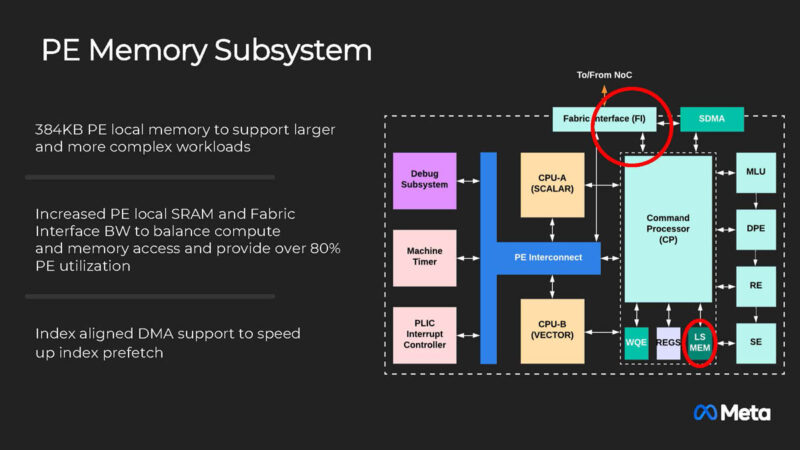
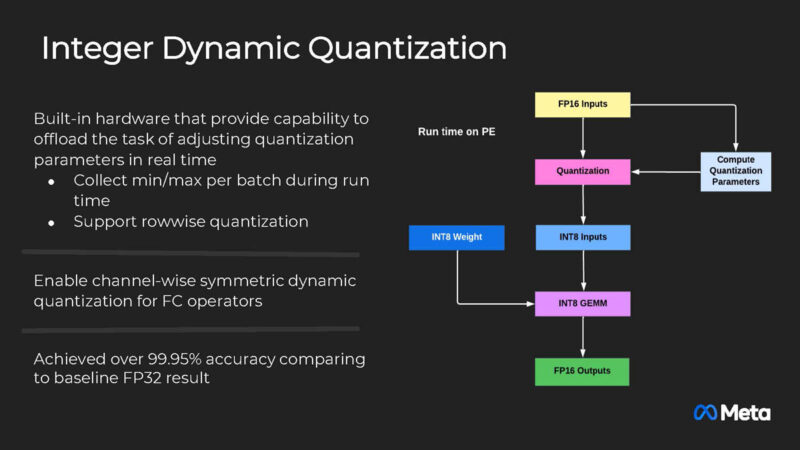
Meta built an Integer Dynamic Quantization engine with high accuracy that is running in hardware.
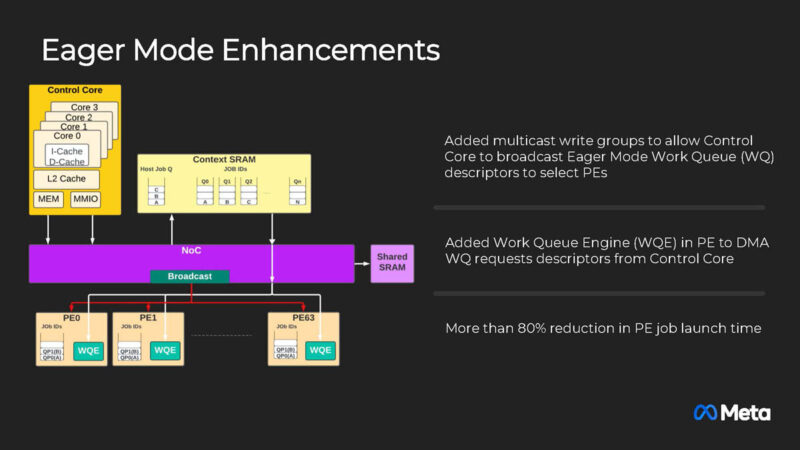
Eager mode is used to lower the job launch time and provide faster responsiveness.
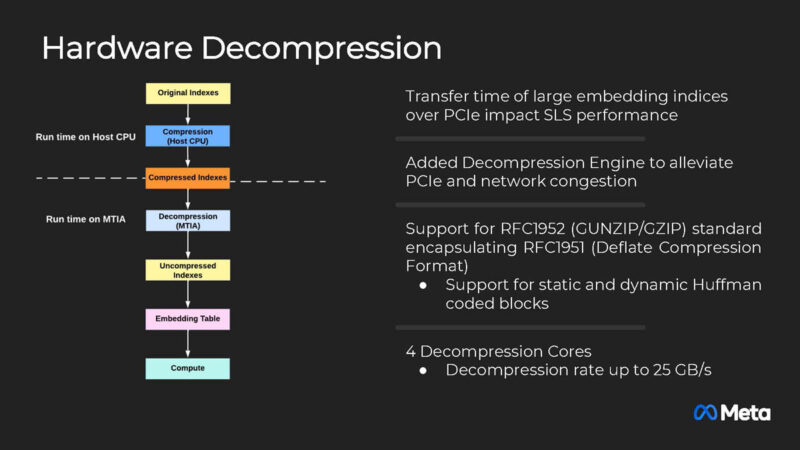
Meta is building a hardware decompression engine so that it can move compressed data through its systems saving on bandwidth.
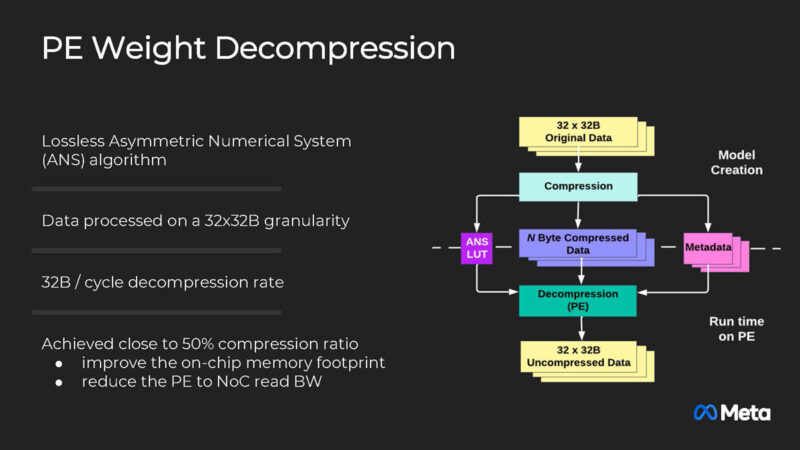
Meta is also doing weight decompression.
The new Table Branch Embedding (TBE) Meta says can improve runtime by 2-3x which is a huge jump.

Here is the accelerator module. Each card has two MTIA chips. That is still a relatively easy to cool 220W TDP. It also efficiently uses PCIe lanes since each MTIA can use a PCIe Gen5 x8 interface for x16 total.

Meta is using dual CPUs, but WOW! What is that Memory Expansion connected to the PCIe switch and the CPUs? This is a 2024 architecture, so is this CXL or something?
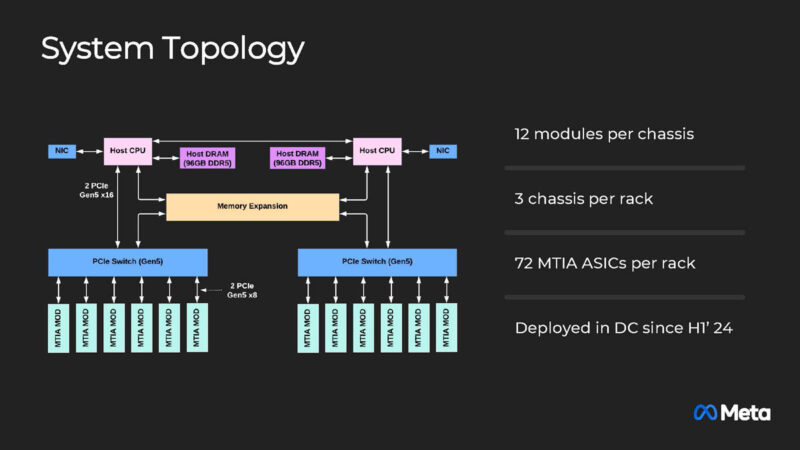
Ok I asked my first Hot Chips question after many years. Meta said it is an option to add memory in the chassis, but it is not being deployed currently.
Meta is also using twelve modules per chassis but seems to be in lower power density racks with only 3 chassis per rack and 72 MTIA accelerators (about 16kW of accelerators, and likely sub 3kW from CPUs.) These seem not be designed for 40kW+ racks.
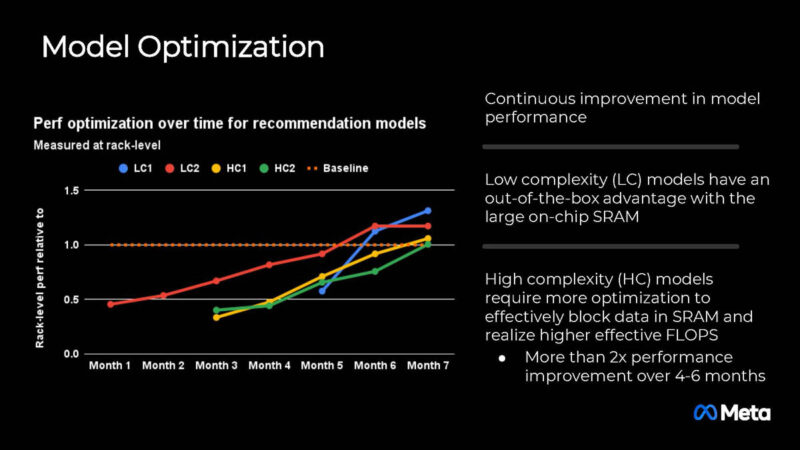
Here is the model performance to baseline on Meta’s internal workloads.
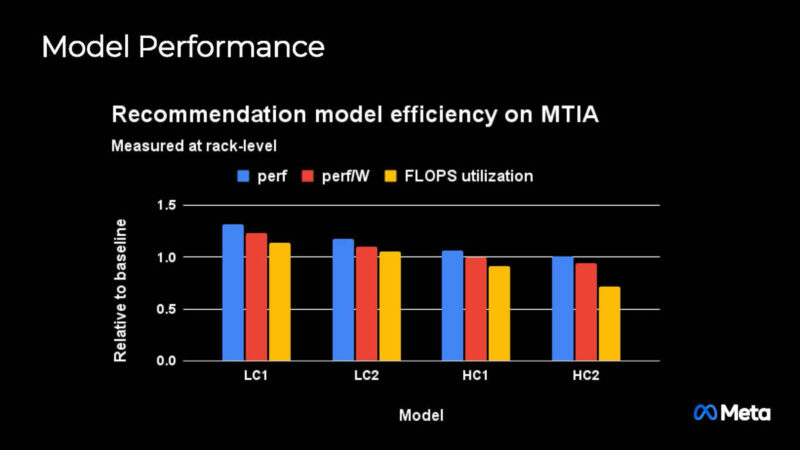
It is a bit hard to know if this is good since we do not know what the baseline is.
Final Words
Overall, it is super cool to see Meta’s new recommendation accelerator. The fact they are using some sort of shared memory over PCIe in the system architecture is very cool. Likewise, they are using RISC-V, which is a very modern approach. Meta is one of the hyperscalers most open about its hardware, which is super cool.



{kind=link}
There is a typo in sram size.
Your estimated power consumption for the card seems inaccurate. Given that each card has 36 modules (2 MTIA per module) with a TDP of 220W, the total power consumption per card is approximately 8kW. This suggests that the entire rack would draw significantly less than 20kW, which is a typical rack power limit. Which is a breeze compared to Blackwell-based racks.