
Today, Marvell, along with the three major HBM providers, Micron, Samsung, and SK hynix are taking the next step in customizing XPUs for hyper-scale clients. The Marvell custom HBM compute architecture is designed to drive higher HBM density for next-generation XPUs by customizing the interconnect between the HBM and the XPU.
As a quick note, I am at Marvell Analyst Day 2024, so we are hearing this live. The press release will come out later today, but there is no embargo on this Analyst Day presentation.
Marvell Custom HBM Compute Architecture for Custom Hyper-Scale XPUs
HBM memory trades capacity and expandability for significantly higher bandwidth. Generally, how HBM is deployed next to CPUs and accelerators or XPUs, is that it interfaces through standard wires across a silicon interposer that links the two pieces of silicon. The XPU usually has two or more HBM stacks made up of a stack of DRAM and then a base die.
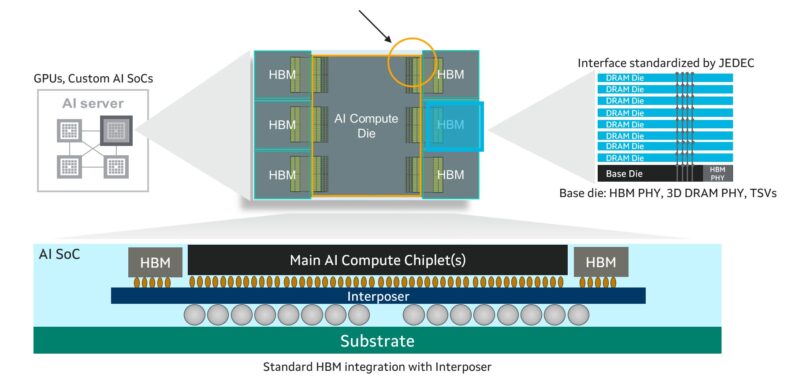
Hyper-scalers along with Marvell and the major HBM players are defining a new customzied interface that takes less space on the compute die. This allows Marvell and its customers to potentially place more HBMs next to XPUs increasing the memory bandwidth and capacity per chip. It can also lower the power requirements for the chips that use the custom memory.
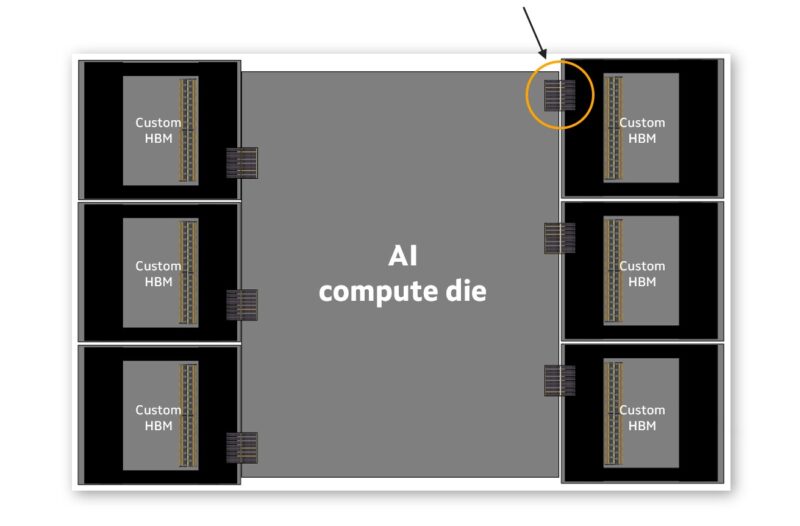
The challenge, of course, is that the standard interconnect version of the HBM uses a lot more shoreline space on the chips. By decreasing the physical space required to connect the HBM and the XPU, the space can be used for other I/O or more HBM. Marvell says that this can increase I/O performance and offer 70% lower interface power as well.

This also means that the custom HBM solution is not the JEDEC solution. Or in other words, the cHBM (custom HBM) will not be standard off the shelf HBM.) HBM4 uses over 2000 pins, or twice that of HBM3. By using a custom interconnect, that removes the need for all of those pins. It also frees die area for adding custom logic like compression and security features.
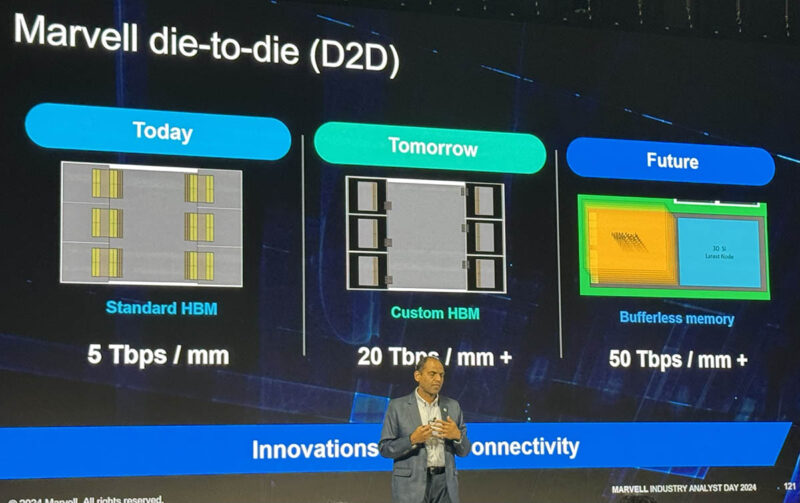
Marvell just showed that it is expecting around a 4x increase in throughput per mm of area. It is also showing the future of 10x beyond today’s bandwidth.
Final Words
For those not in the industry doing this every day, here is the real impact. Hyper-scalers added something like an additional $100B of CapEx spend this year. The next-generation of hyper-scale AI clusters are going to be 10x or more of the 100K GPU xAI Colossus Cluster that we toured using several Gigawatts of power. As these clusters get larger, saving a watt scales into megawatts of savings. Moving memory away from JEDEC standards and into customization for hyper-scalers is a monumental move in the industry. This shows Marvell has some big hyper-scale XPU wins since this type of customization in the memory space does not happen for small orders.



{kind=link}
If I’m understanding this correctly it looks like they are going with a high speed serial interface rather than a broad parallel one(as seems to be periodically tried in RAM, whether with totally different RAM types like what RAMBUS did, or tack-ons like with FB-DIMM).
Do we know whether this arrangement requires a totally different flavor of HBM built from the ground up to suit the serial interface; or is it more FB-DIMM like in being ‘normal’ HBM but having some sort of translator at the bottom of the stack that implements the serial interface (like the ABM on an FB-DIMM which handled abstracting the normal DDR into a serial interface back to the memory controller)?
Also, since this seems to be a thing with let’s-make-memory-serial-because-fast-wide-multidrop-busses-kind-of-suck; are there expected to be latency implications?