
Kioxia has something new and very cool coming. At FMS 2024, the company is showing off a SSD with an optical interface. This is one where hopefully Patrick, George, or Virginia will snap a few photos later this week, but here are the details before the show floor opens.
Note: We updated this with photos from the show floor.
Kioxia Optical Interface SSD Demoed at FMS 2024
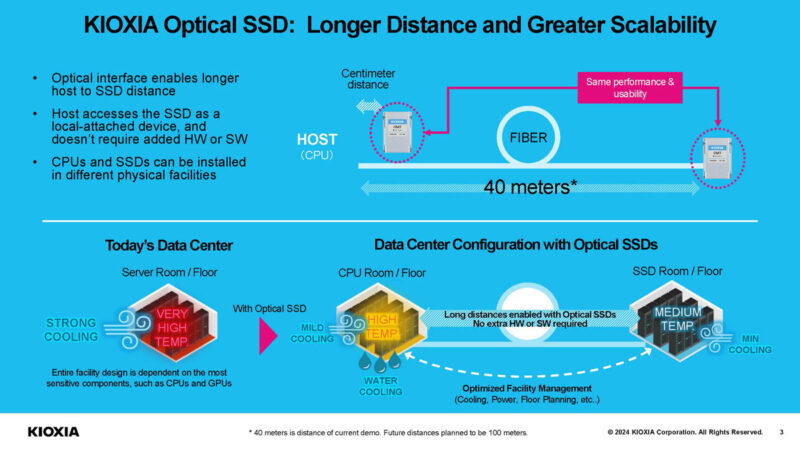
Kioxia is developing an optical interconnect SSD for PCIe Gen8 or later, but is starting to show the technology now.

The current demo is a very short range 40m in distance (~131ft) optical connection, but the company plans to have 100m distance in the future. One of the concepts is that this could allow for SSDs to be placed in locations far away from hot CPUs and GPUs that may be liquid-cooled. Instead, NAND can be placed in a more moderate temperature room or containment area where it performs the best.
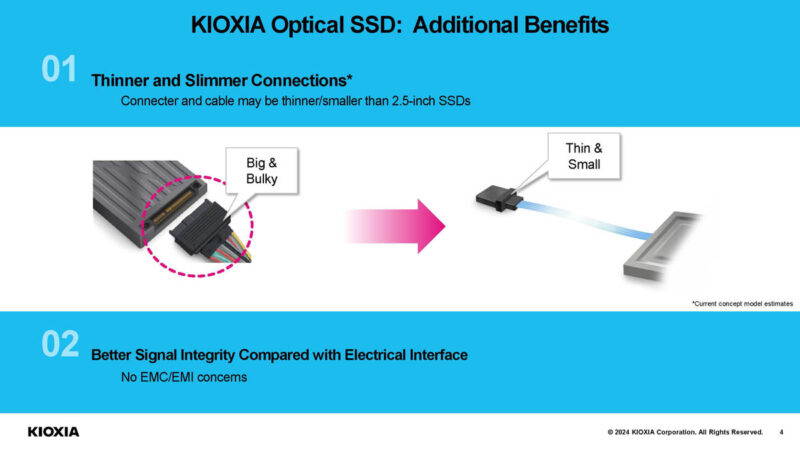
Another idea is that this could be a smaller connector, but we are not sure about this one. A standard MTP/MPO connector is smaller (although we are not sure that is what is being shown since it looks a bit different), but it does not provide power.
Update: Here is the demo running. The SSD connects to a board that converts PCIe signaling to optical signaling.

We asked, and in theory this type of technology can be used for things like GPUs.

We asked and this demo is more like PCIe over optics (without the electrical part) rather than converting it into another protocol like Ethernet.
Another advantage is that it can be switched using optics. To us, this is the big winner, with some caveats. In theory, even using 100m SR optics, one could then use switches to aggregate bandwidth, share devices, and extend the distance between SSDs and host servers.
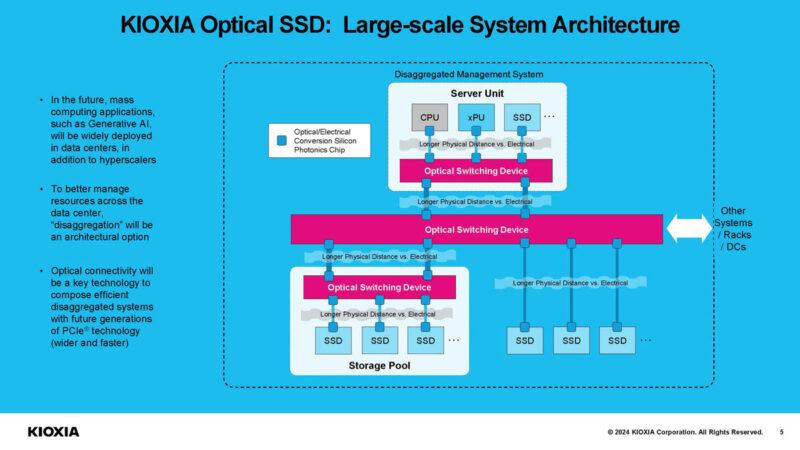
At some point, the question will be how this is done. Currently, optical networking is so much faster than SSDs and increasing at a faster rate that perhaps the option is to use switches to add SSDs to networks, either PCIe, CXL, or Ethernet-based. For some sense of scale, PCIe Gen5 NVMe SSDs are just being rolled out by all major SSD vendors (Kioxia has had PCIe Gen5 NVMe SSDs for some time.) At the same time, it would take around 16 top-end PCIe Gen5 x4 SSDs to fill a single 800GbE port on the Marvell Teralynx 10 51.2T Switch we just reviewed.
At some point with networking like this, the question will be whether we should directly attach SSDs using optical interconnects or if SSDs will move to switches that are then optically connected.
Final Words
This feels like the next frontier of Ethernet SSDs like the older Kioxia EM6 NVMeoF SSD. Although Kioxia has not said if the optical interface SSDs will be Ethernet, PCIe, or CXL-based, at some point the major problem is sharing enough storage with systems in a manner that makes sense. Another opportunity is to share pools of SSDs among larger clusters, especially as we move to an era of CXL 2.0, CXL 3.1, and beyond switches.
If you want to see what feels like a “granddaddy” technology, you can check out the Kioxia EM6 video above. It was a way to solve a similar challenge using older technology.



{kind=link}
What about power?
They showcase a SAS cable, thats 80% powerwires, due to backwards comptability to the SATA standard, and showcase it can be replaced by a single fiber line.
But, they dont transfer power over that fibercable.
Can someone please tell Kioxia, that their marketing is flawed?
I’m curious about the economics of pushing the fiber all the way to the drive(vastly more so if it doesn’t end up being an industry standard or a more-or-less-at-cost board swap variant of their other drive models rather than some sort of premium offering); rather than to the backplane or the enclosure.
A fiber interface will be a bit slimmer than a copper one for SAS or NVMe; but the difference will be pretty modest once you factor in providing power in both scenarios(and if you are willing to break backwards compatibility there’s no reason to judge the fiber option vs. the clunkiest because 3.5in SATA drives did it that way copper option); and the benefits of longer reach/disaggregation are real; but will be running up against competition from normal drives in enclosures of one flavor or another(iSCSI if you want cheap and totally ubiquitous; Fibre channel if you are expensive in a slightly old-school way; NVMeoF if you are expensive in a contemporary way); and, unless newer PCIe flavors are really murder on backplane prices, those seem like they’ll remain a plausible alternative to running a fiber pair and optics per drive.
@mras But…but… thin and small vs. big and bulky!
@fuzzy, I think the selling point is distance. You just can’t run PCIe for 10s of meters without the price skyrocketing. Fibre is cheap by comparison. Fibre can run kilometers if you want.
@fuzzy #2 re mobo specifically… the price of a PCIe5 mobo vs PCIe3 mobo, same IO config already double the price.
If the industry moves to integrated optics and does away with PCIe slots and on board repeaters for coming PCIe gens, you should see prices actually fall.
Surely this topology has already been tried with SCSI Fibre Channel? There you could connect hosts directly to storage kilometres away, but few people ever did because you had to run a dedicated fibre for each device. So then they invented FC switches, which were much the same as Ethernet switches with a few extra bells and whistles, but then you had to duplicate your Ethernet infrastructure just for storage only.
It seems like today reintroducing a direct host-to-device optical interconnect is not going to be particularly popular, unless the interface can also be plugged into an Ethernet switch. *That* would see much more demand, because then you would no longer have a limit to how many devices a host could communicate with. Instead of a limited number of SATA or SAS ports, you could put in a 100G Ethernet NIC and add more and more disks to external 100G Ethernet disk arrays (kilometres away if you wanted) until the links are saturated (or even beyond that if you’re after capacity rather than speed).
All the pieces are already in place for that, with copper and optical Ethernet being everywhere, fast 100G+ links existing, the ability to add multiple links to hosts, and protocols like iSCSI that can handle the transport over these networks. Seems a no brainer to integrate a 25G or 100G Ethernet link onto the SSD along with iSCSI firmware and call it done.
Difficult to imagine a use-case for this, unless the latency is less than/equal to a directly attached drive and even then why put the connector on the drive instead of a shelf of drives?
Not compairing apples with apples for that connector are they?
Anybody wanting remote drives capacity would also have more than one drive so direct to the drive is wrong as it would be a shelf with a backplane
Looks more Thin and Fragile to me.
Copper is running into issues being able to be leveraged even at short distances and speed. Optical is dominate in data center networking but even the copper traces to the optical transceiver to the switch chip is an issue. The coming SFP112 modules is at the edge with faster speeds looking like copackaged optics will be necessary. PCIe 7.0 is around the similar limit of 128 GT/s per lane. At this point, it is looking increasingly likely that fiber will be used between devices running across a motherboard in a few short years.
At the same time as copper is reaching its limit, additional functionality is being added both to Ethernet and PCIe with some overlapping ideas. DMA is a key idea so that individual devices be it on the network or PCIe bus can safely transfer data without needing CPU supervision. Fabric design and being able to have multiple active paths between end points is a major feature in both Ethernet and PCIe topologies. Despite increasing bandwidth per link, there is not a fast enough single bus to serve as a traditional single backbone so fabrics are a necessity. How these are implemented between Ethernet and PCIe is distinct for their respective base protocols. With a potential unification of the physical interface on high speed optical all that way to the chip package, it is worth exploring the idea of unifying the data link protocols running over it for baseline interoperability. Networking is going first with the UltraEthernet standard whose formal 1.0 definition is due later this year, though focused on RMDA and direct device communication. If there isn’t an overlapping single standard, I would predict a standardized frame encapsulation to permit PCIe/CXL over UltraEthernet, though at a slight performance/latency hit.
While a far on the horizon, it is seemingly likely we will have processor (CPU/GPU/NPU/FPGA etc.), memory, storage, peripheral and networking all on a single interface. Convergence is coming.
@Evan Richardson
Thin and small, and with no power, is whats called a brick.
Utterly useless.
But i am sure the marketing had a great day, sad they didnt understood what they compared.
New announcement on this from yesterday: https://global.kyocera.com/newsroom/news/2025/001029.html