Intel Xeon Skylake-SP Instruction Set Changes Featuring AVX-512
Perhaps the most impactful change, from a business perspective, is the addition of AVX-512 into Skylake-SP’s instruction set. Beyond AVX-512, Intel added virtualization and security architecture enhancements.
We wanted to focus energy on AVX-512. AVX-512 allows 512-bit wide vectors to be computed which greatly improves speed.

AVX-512 was formerly an Intel Xeon Phi x200 exclusive and popular in the HPC space. During Intel’s HPC overview, the rationale for adding the instruction set into the mainstream Xeon line was that those wanting to do general purpose compute workloads in HPC can use Xeon instead of GPUs or Xeon Phi chips.
The AVX-512 instruction set is not the same as the Knights Landing AVX-512 instruction set. If you are using gcc, you will likely need to compile using different flags versus what is used for Xeon Phi.
Here is Intel’s performance and efficiency side on AVX-512.
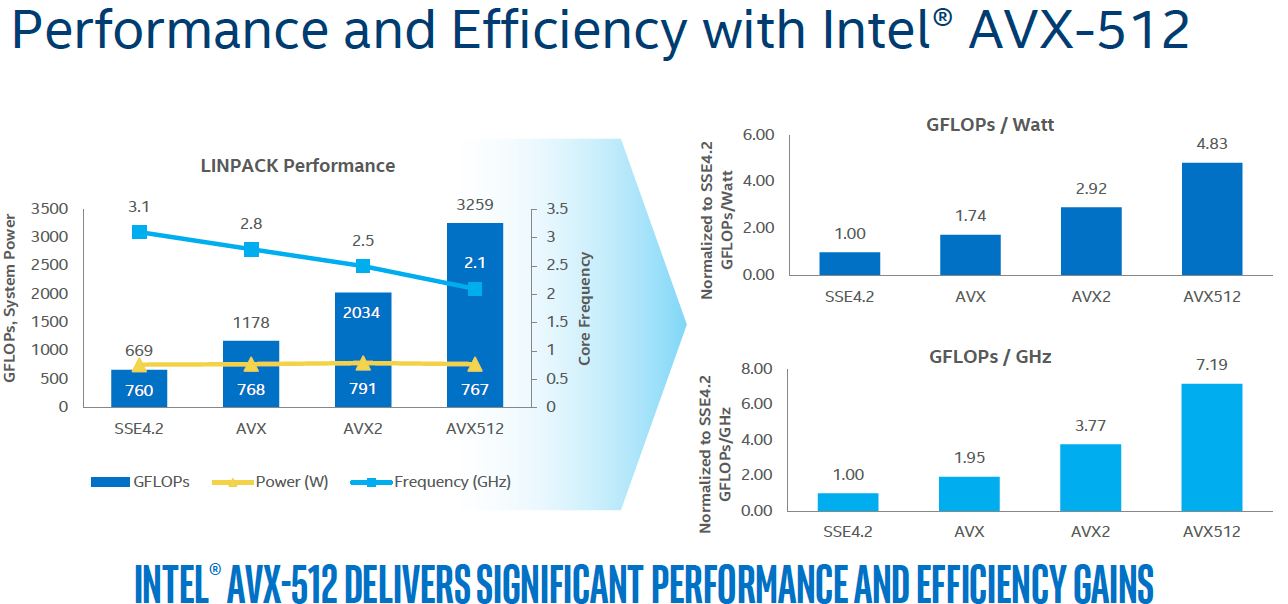
With AVX and AVX2 we saw power consumption and power draw rise at a given clock speed. As a result, Intel downclocked cores while running AVX code.

With Skylake-SP cores running different AVX code can run in different frequency bound ranges. In older CPU versions running AVX on a single core meant all cores would down clock. Intel has come a long way to its current implementation of clocking in AVX workloads.
Final Words
The cache changes are huge as it gives Intel some transistor budget to use elsewhere. Likewise, the FMA and AVX-512 changes are very significant. We do believe that the AVX-512 inclusion may have a profound effect:
Intel Xeon Phi may be on the road to an untimely phase out.
We make this prediction for a few reasons. First, by moving AVX-512 to the CPU, Intel gives its HPC customers a migration path that they can use alongside GPUs and/ or FPGAs. With alternative HPC architectures like the ARM-based Cavium ThunderX2 and GPUs doing massive floating point performance, Intel needed to beef up its standard compute cores.
For the emerging AI/ deep learning workloads, Intel acquired both Altera and Nervana. Both have high-performance solutions better suited to solving deep learning type problems. The HPC and deep learning infrastructure look very similar these days. Despite Intel’s efforts workloads are not moving to Xeon Phi.
AVX-512 was the killer feature of Xeon Phi Knights Landing alongside the MCDRAM and on-package Omni-Path. As Xeon chips bring AVX-512 to general purpose compute cores, it gets very difficult to choose Knights Landing over Intel Skylake-SP if they are offering similar performance. If Knights Mill and the future roadmap does not change the picture, Intel Xeon Phi may be a casualty of the Intel Xeon Salable Processor Family.



{kind=link}
“Intel Xeon Phi may be on the road to an untimely phase out.”
It does leave Xeon Phi in bit of a pickle. However, all is not lost.
First, the MCDRAM advantage means most applications that are bound by memory bandwidth will have an advantage to the Xeon Phi. A not insignificant number I hear.
Second, the peak Flops is still noticeably higher on the Phi. The 8180 with 2.5GHz AVX-512 frequency would have 2.2TFlops of performance. Xeon Phi 7250 has 2.6TFlops and 7290 has 3TFlops.
In DL workloads we’ll see Knights Mill in a quarter or so. While the DP performance is said to be somewhat reduced, you get Quad Vector extensions for 32-bit to double SP FP performance and also half-precision vector support for yet another 2x increase in DL performance for a total of 4x. That would result in 6-7TFlops in SP FP and 12-14TFlops in 16-bit FP.
The real threat is Nvidia. Volta is already out and beats Knights Mill in SP and 16-bit FP a bit, trounces it in DP FP, and crushes it on Tensor flops.
Xeon Phi also has second OmniPath connections for better scaling on mass scale.