Dual Intel Xeon Platinum 8280 Benchmarks
For this exercise, we are using our legacy Linux-Bench scripts which help us see cross-platform “least common denominator” results we have been using for years as well as several results from our updated Linux-Bench2 scripts. Starting with our 2nd Generation Intel Xeon Scalable benchmarks, we are adding a number of our workload testing features to the mix as the next evolution of our platform.
At this point, our benchmarking sessions take days to run and we are generating well over a thousand data points. We are also running workloads for software companies that want to see how their software works on the latest hardware. As a result, this is a small sample of the data we are collecting and can share publicly. Our position is always that we are happy to provide some free data but we also have services to let companies run their own workloads in our lab, such as with our DemoEval service. What we do provide is an extremely controlled environment where we know every step is exactly the same and each run is done in a real-world data center, not a test bench.
We are going to show off a few results, and highlight a number of interesting data points in this article.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read:
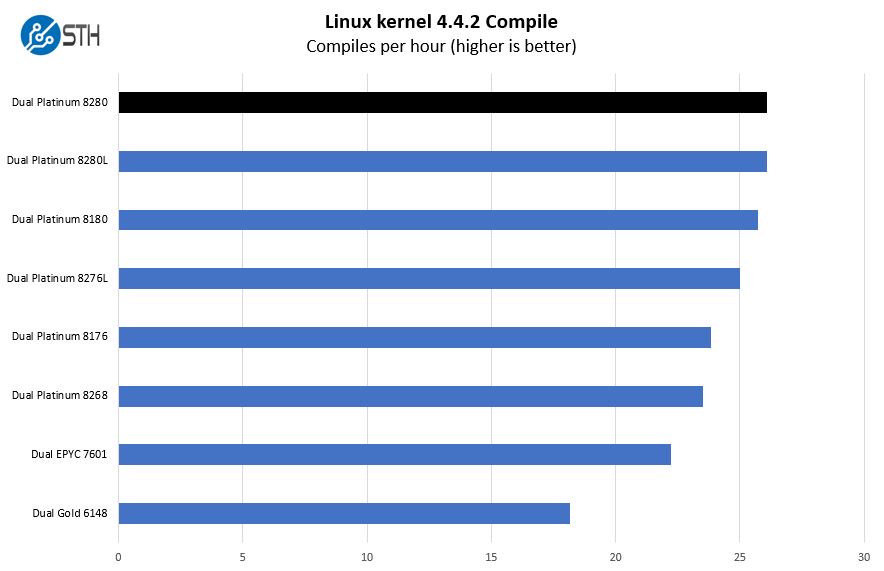
Here we can see a performance improvement over the Intel Xeon Platinum 8276L CPUs we tested and even a slight generational improvement over the previous generation Intel Xeon Platinum 8180.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads. We are going to use our 8K results which work well at this end of the performance spectrum.
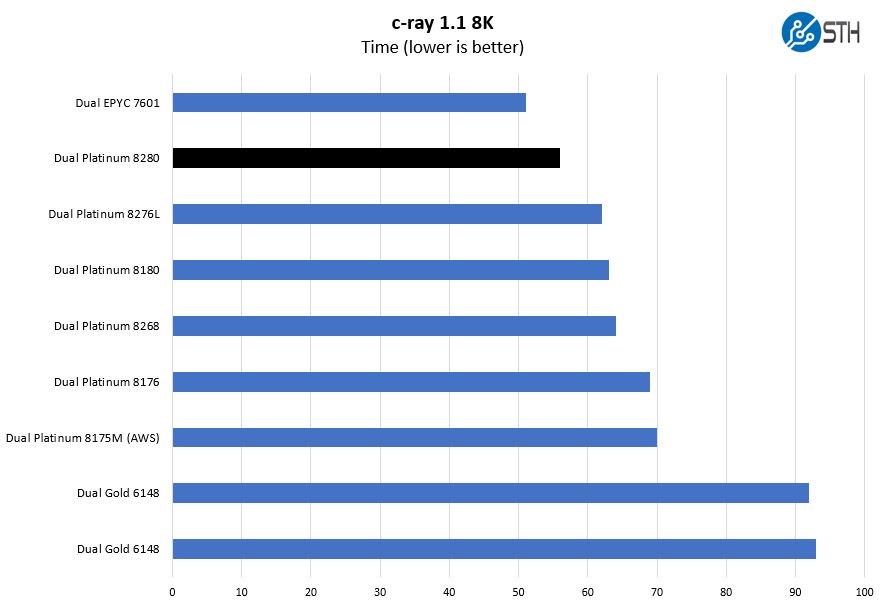
Here the AMD EPYC 7601 performs very well simply due to having more cores and fast caches. This is an architectural win for AMD’s 2017 “Naples” generation which will be replaced one quarter after the Intel Xeon Platinum 8280 launch with a Rome generation with twice as many cores.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
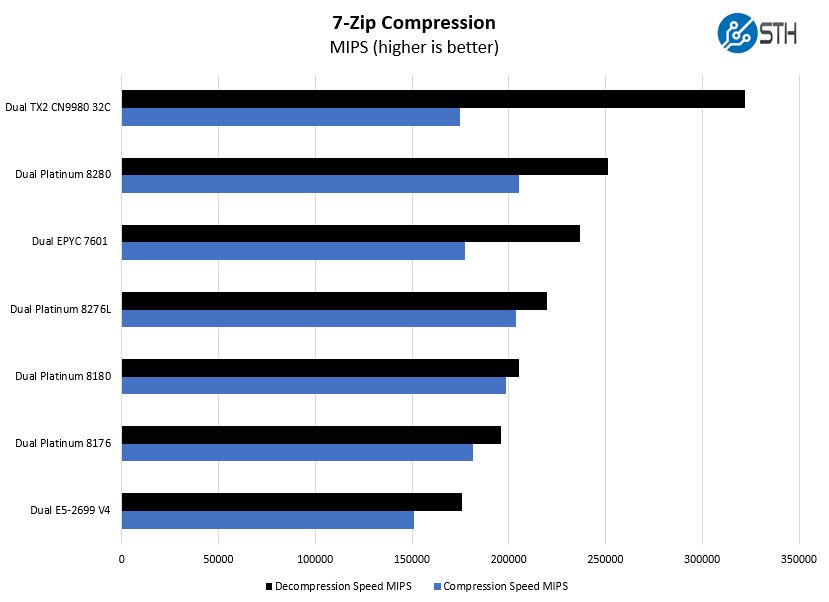
On the compression side, we pulled in results from the older generation dual Intel Xeon E5-2699 V4 setup to show generational improvements. We also were able to compare dual Marvell ThunderX2 CN9980 32 core, 128 thread ARM CPUs.
NAMD Performance
NAMD is a molecular modeling benchmark developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. More information on the benchmark can be found here. With GROMACS we have been working hard to support Intel’s Skylake AVX-512 and AVX2 supporting AMD Zen architecture. Here are the comparison results for the legacy data set:
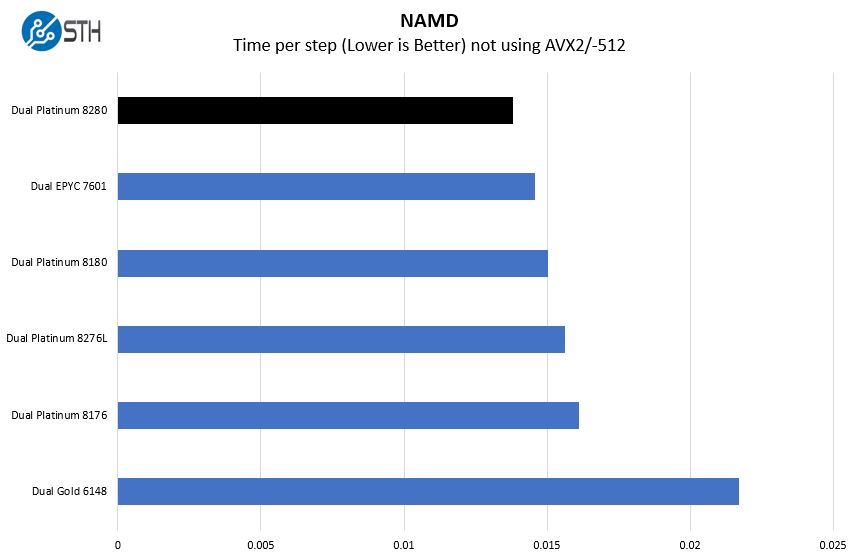
The impact of clock speeds has meant that the Intel Xeon Platinum 8280 performs better than the previous generation. It also pushes the Intel parts beyond the current generation AMD EPYC 7601. Again, we are not running these in the highly optimized configurations that AMD and Intel were using around Computex 2019 which stirred up some controversy. See AMD EPYC Rome NAMD and the Intel Xeon Response at Computex 2019.
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
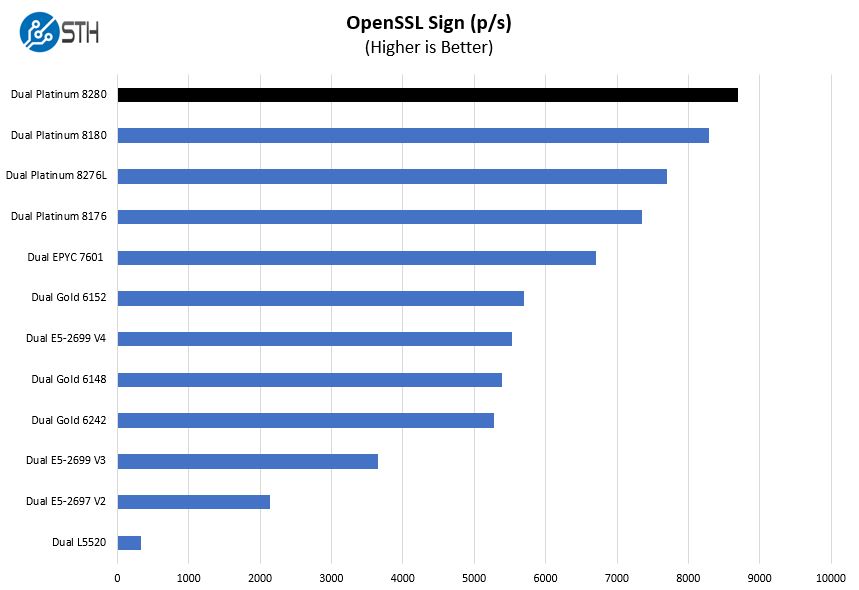
Here are the verify results:
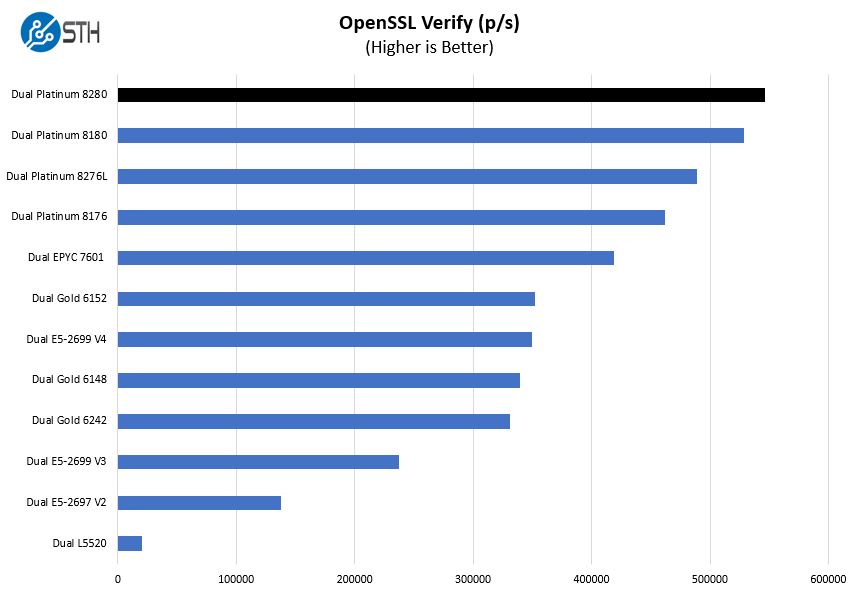
OpenSSL is a foundational technology in enterprise applications. Here we see the performance is again between the dual Intel Xeon Platinum 8280 configuration provide a nice generational improvement.
UnixBench Dhrystone 2 and Whetstone Benchmarks
Some of the longest-running tests at STH are the venerable UnixBench 5.1.3 Dhrystone 2 and Whetstone results. They are certainly aging, however, we constantly get requests for them, and many angry notes when we leave them out. UnixBench is widely used so we are including it in this data set. Here are the Dhrystone 2 results:
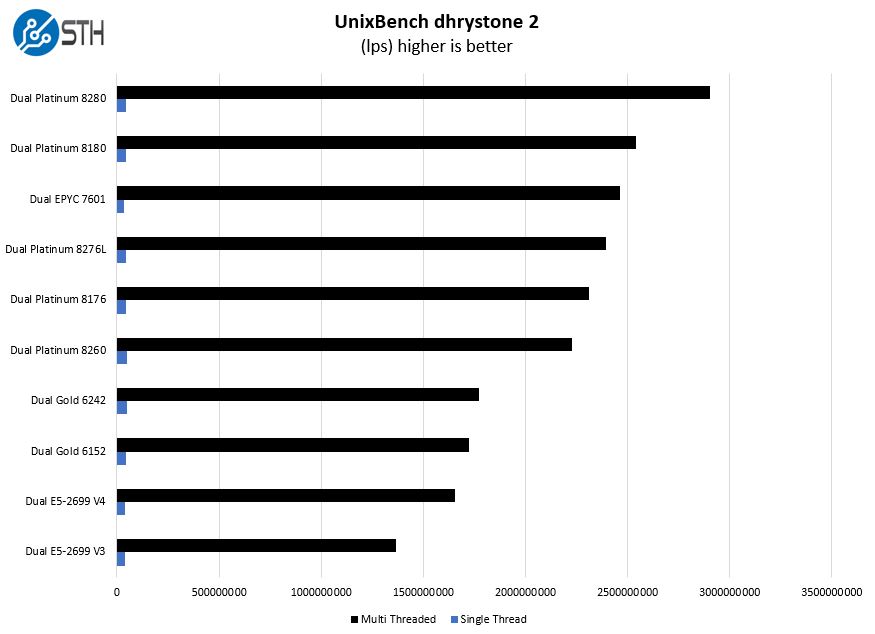
Here are the whetstone results:
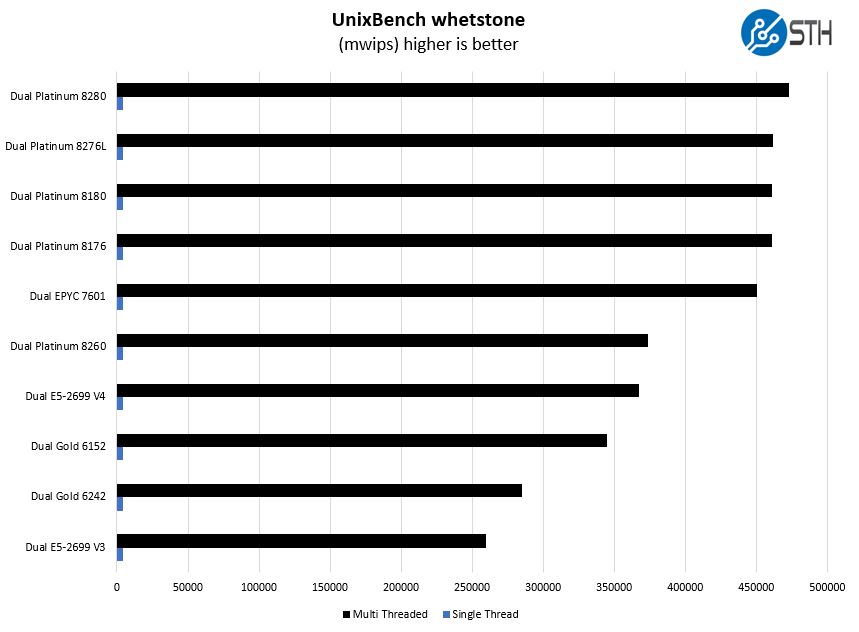
Again, we see the pattern where the chips are incrementally faster than the previous generation. Here, the difference is largely attributable to small clock speed increases.
GROMACS STH Small AVX2/ AVX-512 Enabled
We have a small GROMACS molecule simulation we previewed in the first AMD EPYC 7601 Linux benchmarks piece. In Linux-Bench2 we are using a “small” test for single and dual-socket capable machines. Our GROMACS test will use the AVX-512 and AVX2 extensions if available.
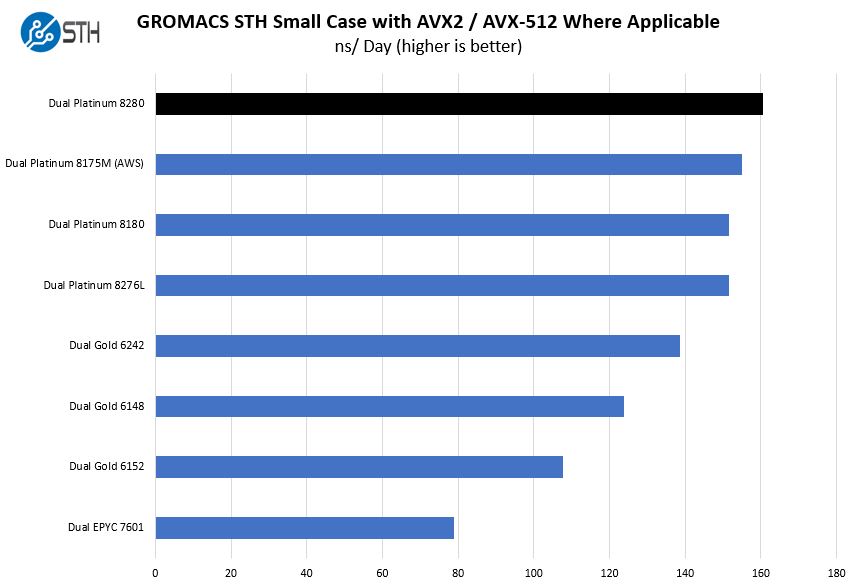
Here performance is excellent. We can see the delta between the Intel Xeon Platinum 8280 and the previous-generation Intel Xeon Platinum 8180. We also added a result for a bare metal dual Intel Xeon Platinum 8175M from the AWS EC2 m5.metal instance type. We get a few requests for adding AWS bare metal instance versus Intel Xeon Platinum 8280 testing so we at least wanted to add a point of view.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and are ready to start sharing results:
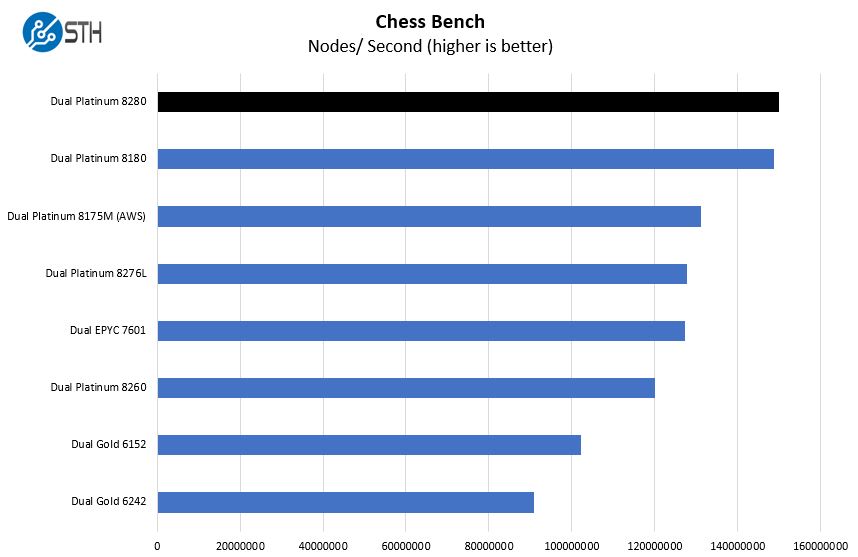
This is another case where the higher TDP parts are able to excel. We see Intel Xeon Platinum 8280 performance above other offerings.
STH STFB KVM Virtualization Testing
One of the other workloads we wanted to share is from one of our DemoEval customers. We have permission to publish the results, but the application itself being tested is closed source. This is a KVM virtualization-based workload where our client is testing how many VMs it can have online at a given time while completing work under the target SLA. Each VM is a self-contained worker.
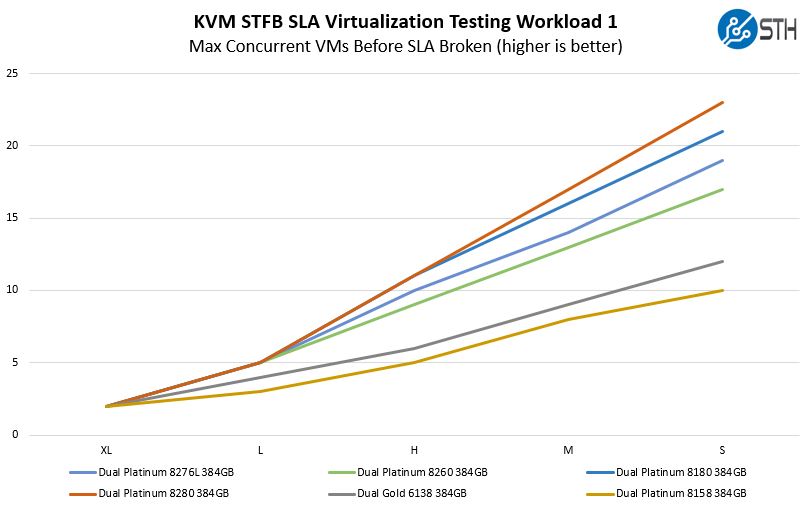
Here we can see performance scale beyond the VM capacity of the quad Intel Xeon Platinum 8280 scale a bit better at a larger number of VMs than the dual Intel Xeon Platinum 8180 setup. This is a newer workload that takes a long time to run, so our data set here is a bit smaller. When we looked at our Workload 2 results, we were severely RAM limited so we did not see a large separation in results.
Next, we are going to discuss the solution’s market positioning and then give our final thoughts.



{kind=link}
Who gets these deep discounts on Intel CPUs? For example, Dell must buy the 8280 in bulk, but they sell it at retail for over $10k (at least for the 7920 workstation).
I’d like to know more about the avx differences between amd and intel.
I see that amd doubled to 256 bit. Do they have one or two execution units per core?
Also, since Cooper Lake has been sampling a while, should we also ask about AMD support for bfloat16? This will double the FP ai training FMAs per cycle for Cooper Lake vs Cascade Lake.
The ai training compute requirements are large, and doubling every 3.5 months according to some articles. Is that still true?