Intel Xeon Max 9480 Conceptual Diagrams
Bringing this back to a set of conceptual diagrams to help our readers who do not deal with CPU tiles every day, here is the Intel Xeon Platinum 8480+ conceptual core and memory diagram.
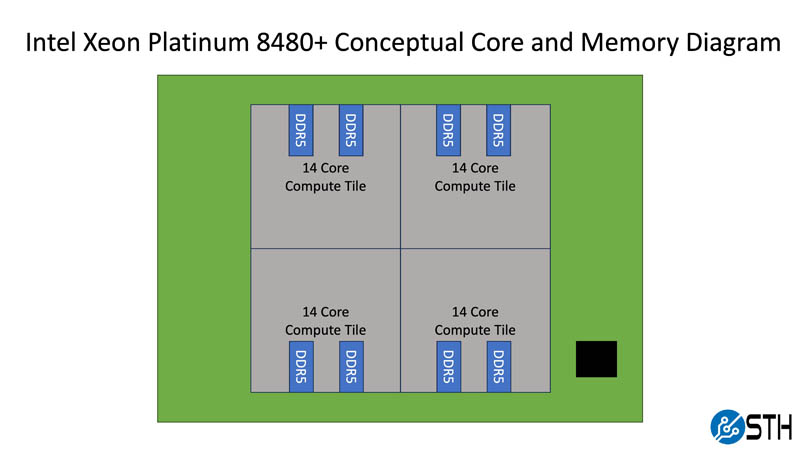
One can see that there are four 14-core tiles each with two channels DDR5 memory. The compute tiles also have features like PCIe Gen5/ UPI lanes and accelerators, but we are focusing on cores and memory for this discussion. Combined, these four 14-core tiles give us 56 cores and 8 channels of DDR5 memory. Each die is connected via EMIB to tie the chips together in an advanced packaging methodology that is a step ahead of what AMD and companies like Ampere are doing at present.
Before we get too far, EMIB stands for embedded multi-die interconnect bridge and one can think of it as a way to densely populate I/O channels between chiplets. It is a central technology to Intel’s current and near-future chipmaking.

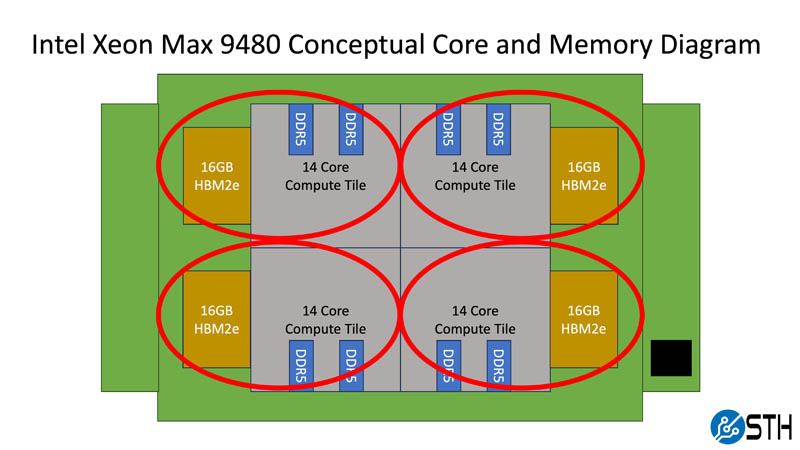
In many ways, the Intel Xeon Max 9480 is an extension of the Xeon Platinum 8480+. We get four 14-core compute tiles and the package is using EMIB. The addition is the 16GB HBM2e package connected to each die. Four packages give us 64GB of HBM2e onboard, more than something like the NVIDIA A100 40GB GPUs had as an example.
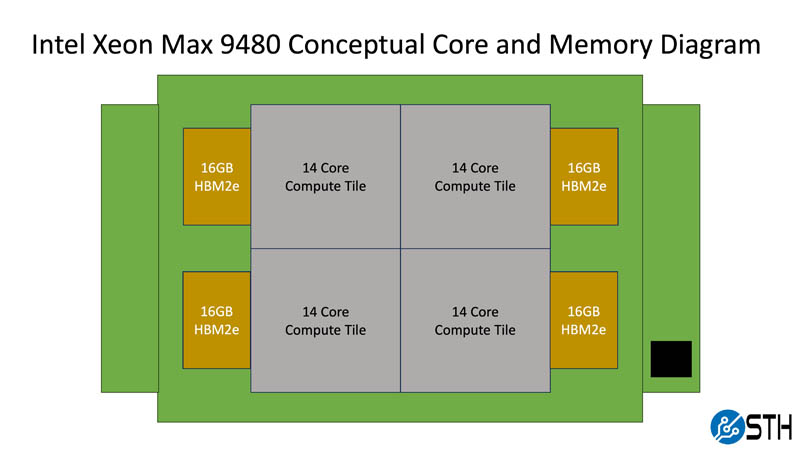
As we will show, the above configuration without populating DDR5 is a valid configuration for the Xeon Max. However, the DDR5 controllers are still present and active on the 14-core compute tiles.
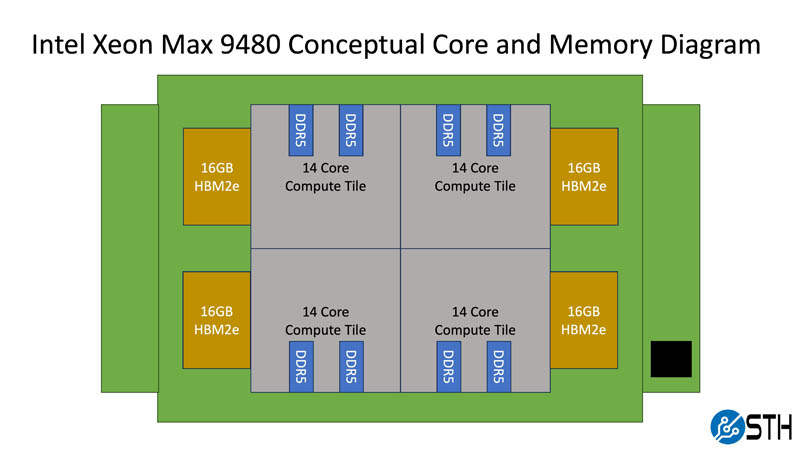
In that way, we can think about each compute tile as having 14 performance cores, two DDR5 channels, and 16GB of HBM2e memory. That presents an opportunity. Since compute tiles have HBM2e and DDR5 local to each tile, one can often get more performance by treating each compute tile as its own partition. That localizes memory access and reduces pressure on the EMIB die-to-die interconnects between each compute tile.
At this point, we have set up one of the key challenges of Xeon Max. Just how many options there are. To be clear, you can put the CPUs into a system, without DDR5, and the system boots up normally. Likewise, you can then add DDR5 and it will work normally, but the Xeon Max has extra options for tuning. Just taking the cases where one can boot the system with or without DDR5, and either treat the CPU as one set of resources with 64GB of HBM2e memory and 8x DDR5 channels or splitting those up into four sets gives us a 2×2 matrix of configuration options.

That is not all though. Intel has two different modes called “HBM Flat Mode” and “HBM Caching Mode” when using a system with DDR5. The easy way to think about this is that flat mode looks like two separate pools of memory, one HBM2e and one DDR5 with total capacity additive between the two pools. The HBM caching mode stores hot data in HBM while using the DDR5 as the primary DDR5 store. Of course, the amount of DDR5 memory installed in a system is another dimension that we are going to conveniently skip since 128GB of DDR5 and 64GB of HBM2e per socket as we have here is a 2:1 ratio, but using 128GB DDR5 DIMMs that would clearly be different.

Here is an example of the chip split into quadrants with 16GB of HBM2e and 32GB of DDR5 (2x 16GB DDR5-4800 DIMMs) per quadrant. One can see that our total memory capacity is 128GB even though we have 64GB of HBM2e and 128GB of DDR5.
Adding that wrinkle, our 2×2 matrix becomes a 2×3 matrix as we have to split the DDR5 into cache mode and flat mode.
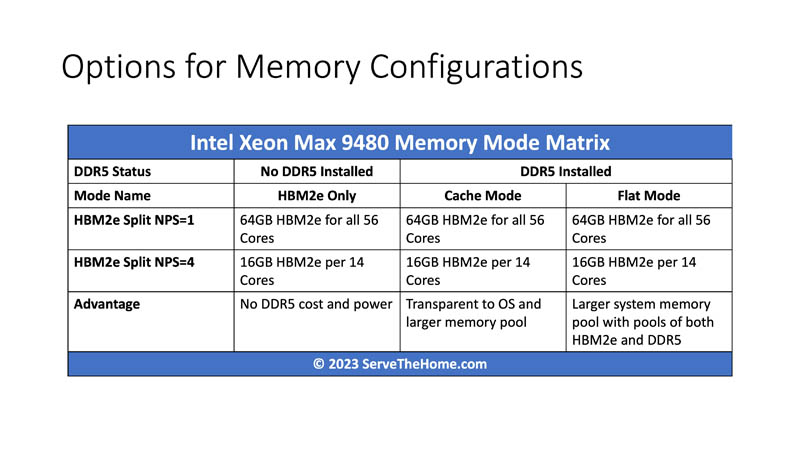
To be clear, most will want to use cache mode for simplicity since it operates transparently to users. If you have a workload that runs on Xeon with DDR5, you can install Xeon Max with DDR5, potentially in the same socket, and get the benefits of having a HBM2e caching layer. Some, however, will want to use flat mode for more capacity and control.
Having six options for performance tuning may seem like a lot, but the actual number is at least twice that. Let us get to performance next.



){kind=link}
Terabyte per second STREAM is spectacular – this is comparable speed from a single server to running STREAM across an entire Altix 3700 with 512 Itanium processors in 2004, and rather faster than the NEC SX-7 which was the last cry of vector supercomputers.
Thanks for the power state info – I was wondering about 14 core/16GB HBM/dual memory consumer version. Oh well!
Despite what Intel stated by power states, I’d have at least tried booting the Xeon Max chip on a workstation board. Worth a try and it would open up a slew of workstation/desktop style benchmarks. While entirely inappropriate a chip of this caliber, I’m curious how a HBM2e only chip would run Starfield as it has some interesting scaling affected by memory bandwidth and latency. Be different to have that HBM2e comparison for the subject.
The open foam results don’t match between the two plots. Where one says hbm2e only is 1.85 times faster and the other says it’s only 1.05 times faster.
Can these be plugged into a normal workstation motherboard socket? as in a few years when these come on the market that mortels can buy off of ebay we wantto play with them in normal motherboards with normal cooling air cooling solutions
I had no idea that they’re able to run virtualization. I remember that I’d seen them at launch but I was under the impression that they’re only for HPC and that they’d done no virtualization and acceleration because of it. We’re not a big IT outfit, only buying around 1000/servers/year but we’re going to check this out. Even at our scale it could be useful
@Todd, Shhhhh! Quiet! Lest Intel hear you and fuse off the functionaility as they used to do…
Is that a real Proxmox VE pic? I didn’t think these could run virtual machines. Why didn’t Intel just call these an option if so. That 32c 64gb part sounds chill
It’s possible virtualization is not an advertised feature because there are too many information-leaking side channels.
At any rate, as demonstrated by the Fujitsu A64FX a couple years ago, placing HBM on the CPU package makes GPUs unnecessary and is easier to program. After the technology has been monetised at the high end, I expect on-package HBM will be cheaper than GPU acceleration as well.
Thank god there’s a good review of this tech that normal people can understand. This is the right level STH. I’m finally understanding this tech after years of hearing about it.
That STREAM benchmark result is impressive.
My 4GHz 16 core desktop computer copies value of double arrays at 58GB/sec, according to my STREAM build with MSVC, and I consider it as pretty decent, because it copies 15 bytes per 1 CPU clock cycle.
intel compiler should optimize STREAM for loop of double array copy with very efficient SIMD instructions