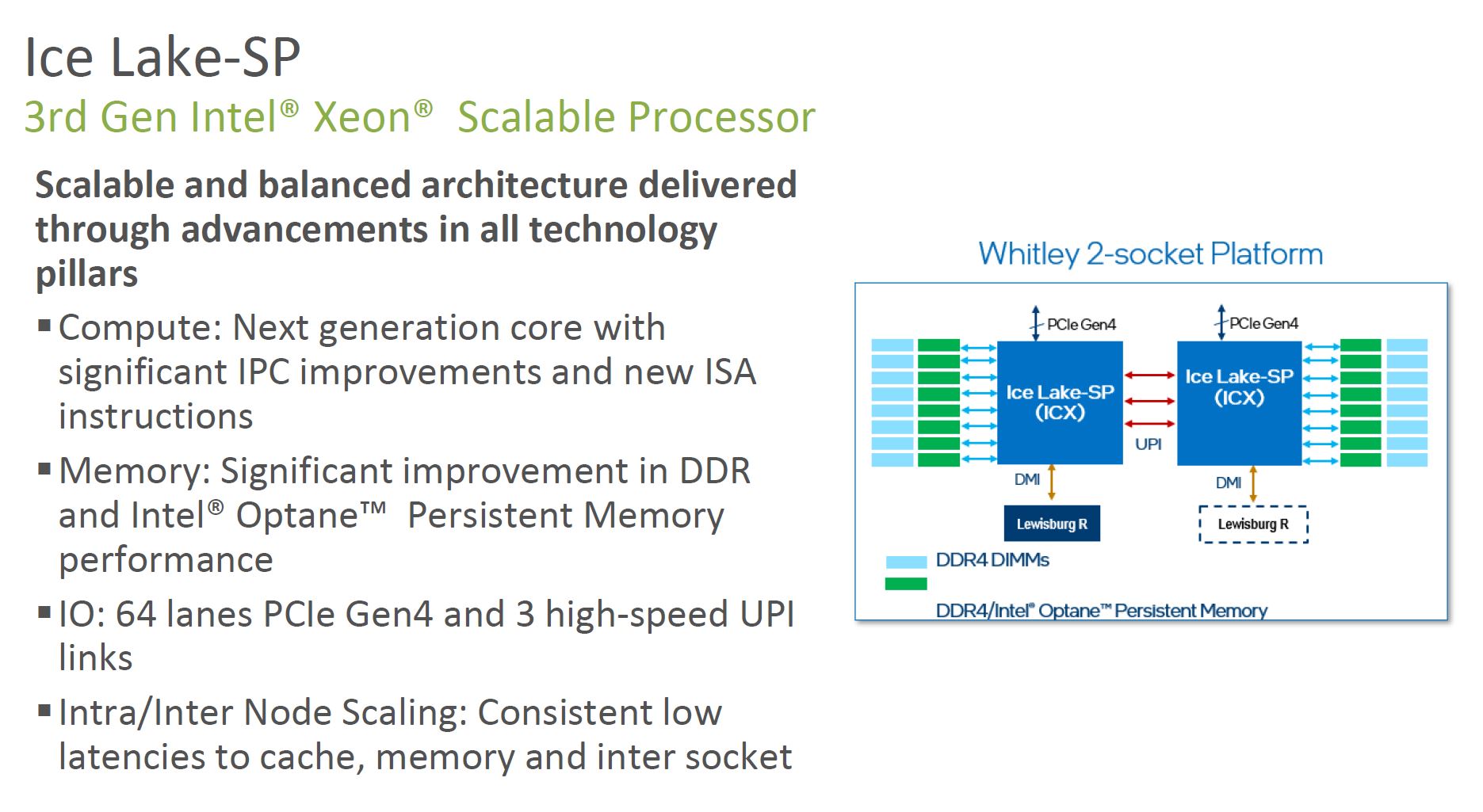
Intel Ice Lake Xeon New Features
Let us get into the new features of the new CPUs. First and foremost, Intel has shaken the 28 core era from 2017 to 2021 and now has up to 40 cores per processor. The new 10nm parts offer higher IPC and new features as well.

Intel is launching these chips as the cornerstone of a new portfolio of PCIe Gen4 devices. Intel has NAND SSDs, the Optane P5800X, Optane PMem 200, new 100GbE and 200GbE Columbiaville NICs. These are enabled by the move to 64 PCIe Gen4 lanes per socket along with the move to 8-channels of DDR4-3200 memory (in Xeon Gold 6300 and Platinum 8300 SKUs.)

If there is one slide to open in a larger browser window, it is this one. This has the highlights of the new chips.

As a summary for those who do not want to blow the above image up:
- 8-40 10nm Ice Lake cores with larger caches and up to 270W TDP
- 3x UPI with 11.2GT/s interconnect
- 8-channel DDR4-3200 with up to 4TB of DDR4 or 2TB DDR4 + 4TB of PMem 200 (6TB total) per socket. 2DPC (2 DIMMs per channel) is supported
- Intel Total Memory Encryption (TME)
- 64x PCIe Gen4 lanes per CPU, 128x for a dual-socket server
- 2 FMA AVX-512 and related accelerators throughout the family
- Intel SGX with varying enclave sizes for secure computing
- Crypto acceleration
- Lewisburg Refresh PCH (Intel C62xA series) has some new features but loses the 10GbE networking of the original series.
- Intel Platform Firmware Resilience (Intel PFR) provides a hardware root of trust.
Intel did not go into this in the press call, but the Intel PFR feature provides many of the features that are in AMD’s security processor feature on EPYCs. Here, the hardware root of trust is provided by the Intel Altera MAX 10 onboard.

It is important to remember that while AMD’s solution has a high level of integration, Intel is still using off-chip solutions such as the Lewisburg PCH and this Altera FPGA to provide features. When comparing pricing and TDPs, these must be accounted for so a 270W TDP Intel chip is closer to a 280W AMD EPYC part especially once we account for the PCH. Intel is placing multiple chips on the motherboard to achieve a similar feature set to AMD’s more integrated design. These chips have their own costs and require PCB wiring, and also have their own power consumption that goes along with them. Here is the quick gen/ gen comparison from Intel:

With Ice Lake, we get Sunny Cove cores. So there are new instructions and higher IPC. One item that is not in Ice Lake is bfloat16, but it is in the Cooper Lake 3rd Generation Xeon Scalable parts. Interesting in this slide is that there is an optional second Lewisburg Refresh PCH shown, but we have not yet seen a server with two PCHs.
Intel is offering that it has larger generation/ generation performance gains. One must remember here that Ice Lake has 43% more cores than Cascade Lake and Skylake so that puts some of these gains into context.

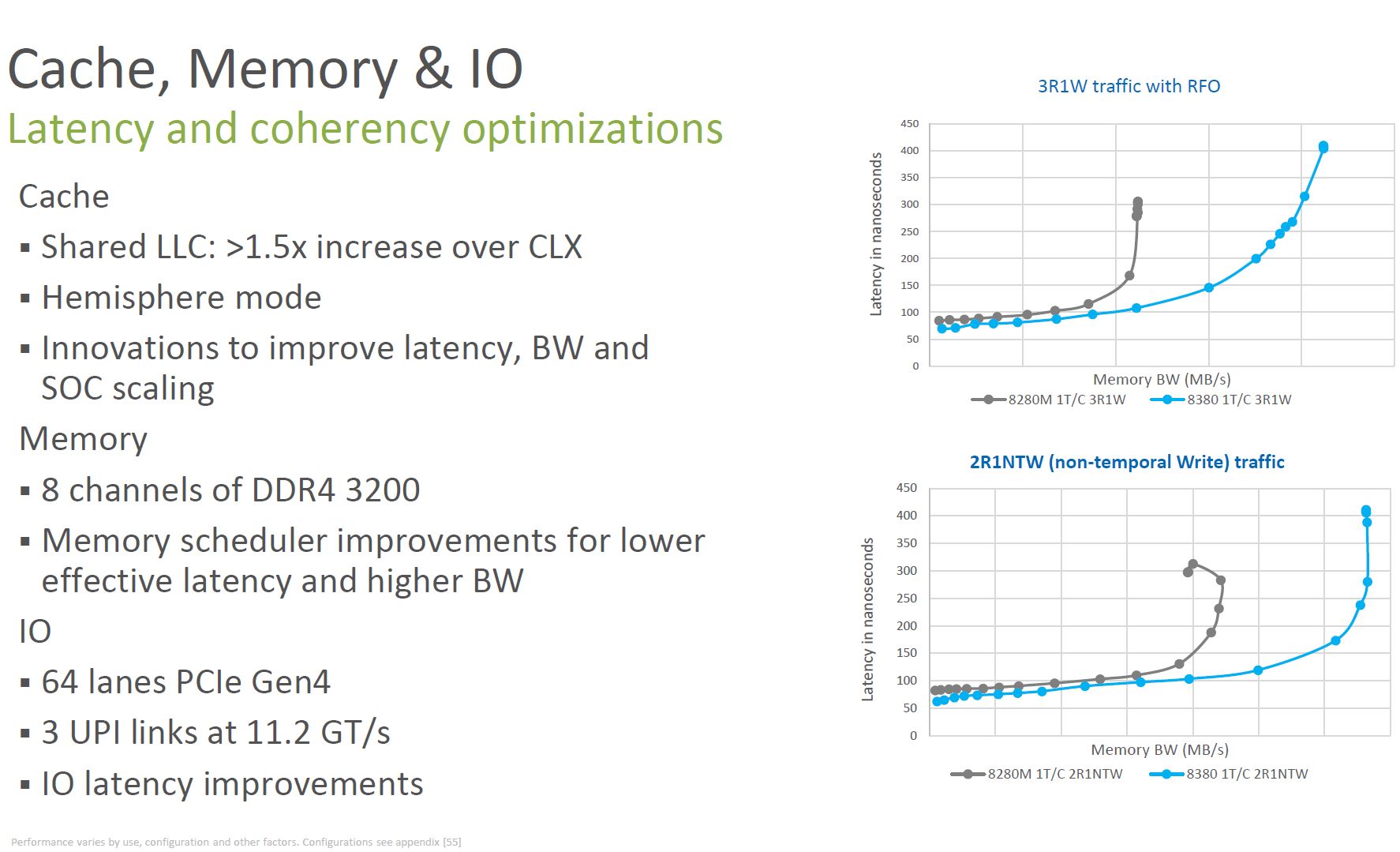
We have covered Intel Sunny Cove Microarchitecture Details previously, but Intel effectively made bigger cores with bigger caches in this generation which means we get more performance.

Intel gets better memory bandwidth and lower latency. Part of that is from going from two three-channel controllers to four dual-channel controllers with mesh fabric stops. Other aspects are that Intel now has 33% more memory channels and is using faster memory.
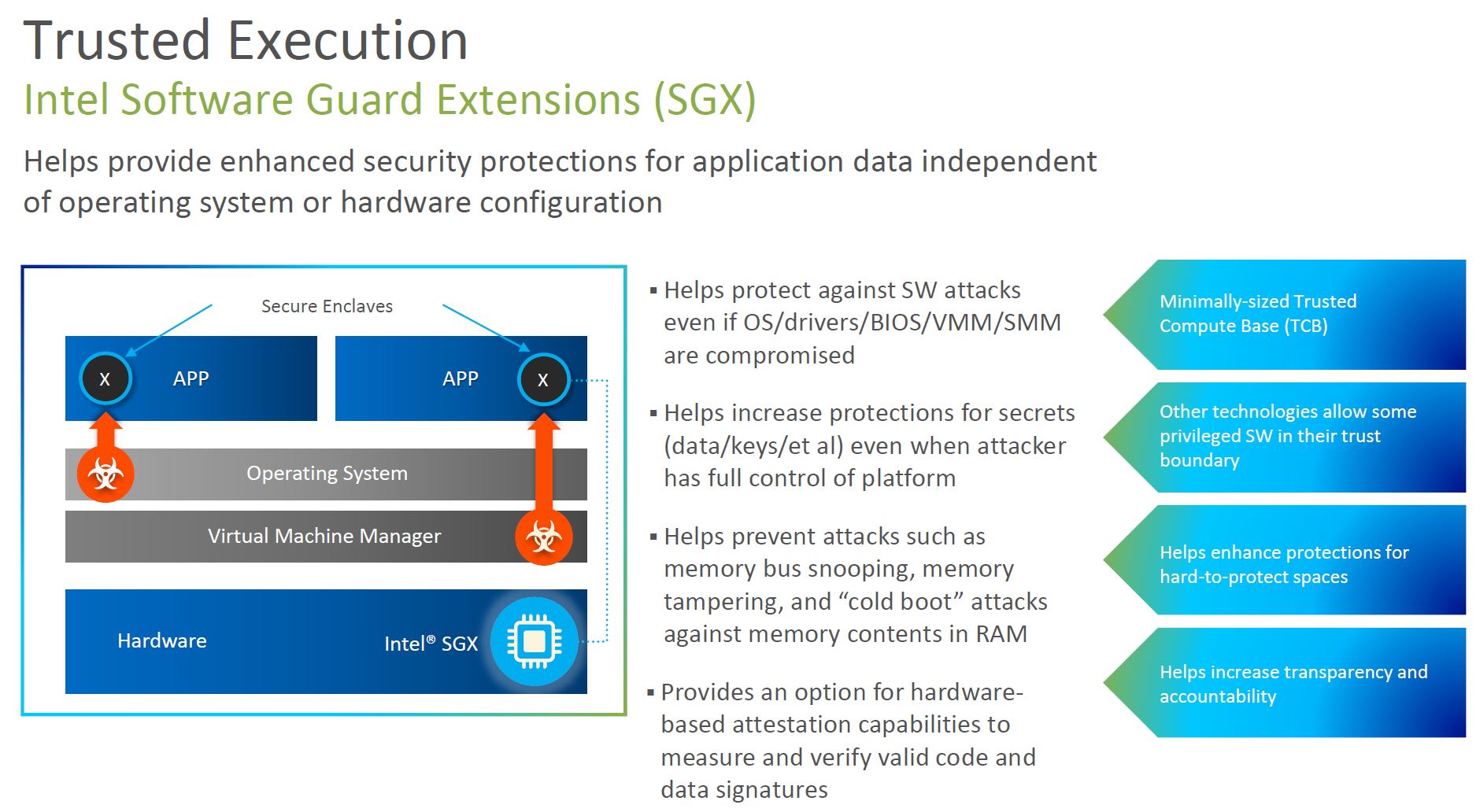
One of the big features of this generation is Intel Software Guard Extensions or SGX. SGX has been available for some time, but often on single-socket CPUs which are not ideal for higher-end virtualization. SGX effectively creates secure enclaves so applications can run securely even if other layers in the stack are compromised. There is a big caveat here which is this is a major feature differentiation point for Intel. We will get to that on the SKU portion of this article.
Another big feature is Intel Optane Persistent Memory. Here we get PMem 200 support which are new faster modules. These modules have a new controller but also operate at DDR4-3200 to match memory speeds instead of DDR4-2666 of the previous generation. Also, having eight channels means we get more DIMMs which means we can get more performance when creating stripes across modules in a socket.

If you want to learn more about Optane PMem 200, check out our Glorious Complexity of Intel Optane DIMMs and Micron Exiting 3D XPoint article and the video here:
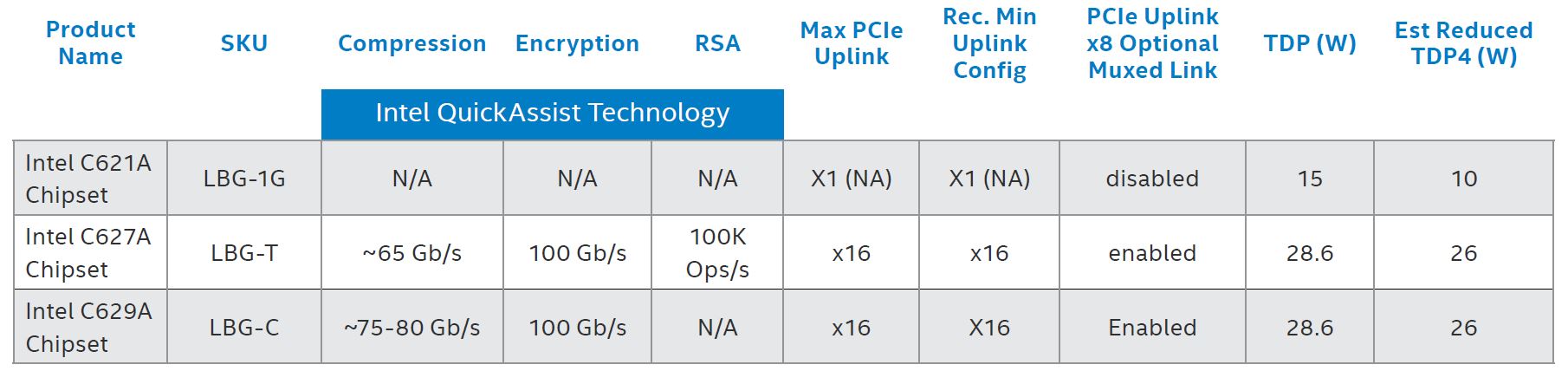
On the PCH side, we get the Lewisburg Refresh PCHs that end in “A”. Intel has fewer SKU options but one can get these with accelerators built-in. A big omission here is that these SKUs no longer have 10GbE MACs as we saw with the pre-refresh versions.
A feature Intel is touting highly is its new instructions and accelerators. Here are the new instructions:

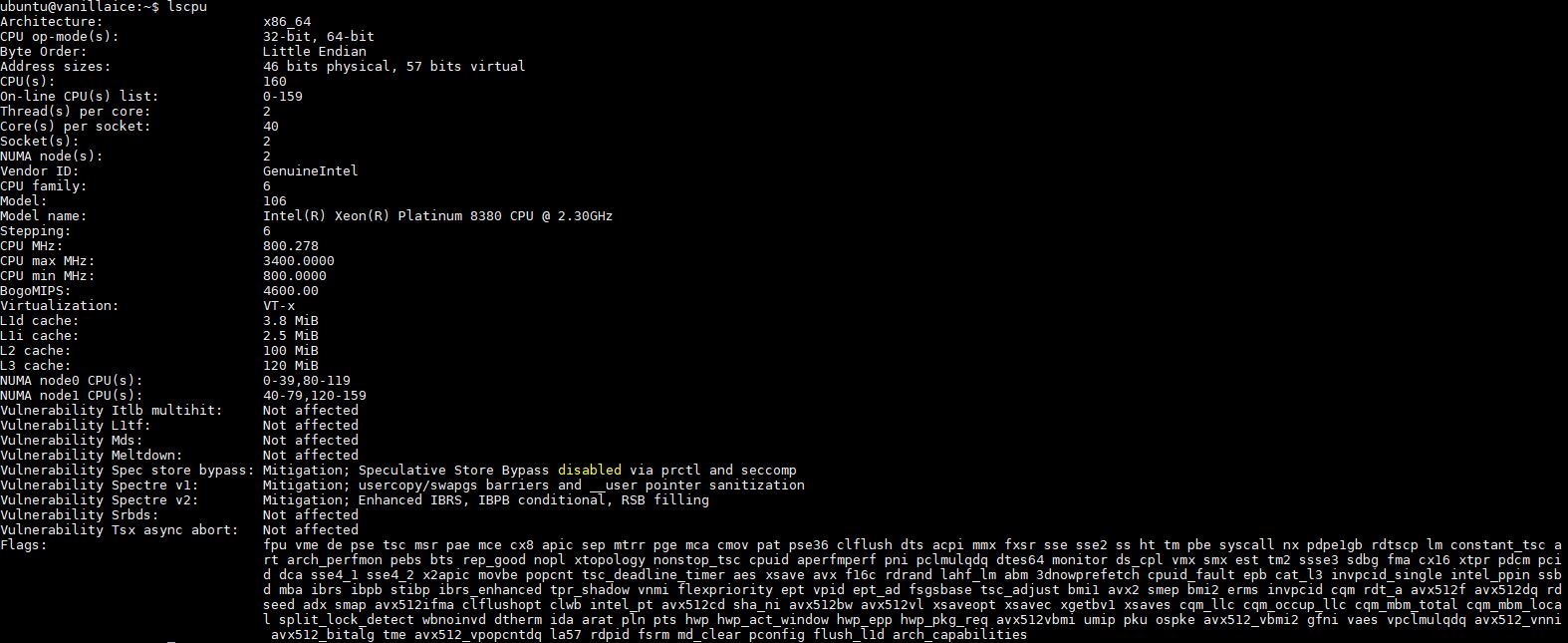
Here is a lscpu output from a platinum 8380:
Intel also discusses its new accelerators often in its presentation materials.

We are just going to acknowledge it has accelerators, and if one has software that uses a specific acceleration pipeline, a workload will be accelerated.
Of course, with Intel, there is what is being launched, but there are caveats. Some of these features work differently depending on the SKU that is being offered. Next, we are going to take a look at those SKUs.



{kind=link}
@Patrick
What you never mention:
The competitor to ICL HPC AVX512 and AI inference workloads are not CPUs, they are GPUs like the A100, Intinct100 or T4. That’s the reason why next to no one is using AVX512 or
DL boost.
Dedicated accelerators offer much better performance and price/perf for these tasks.
BTW: Still, nothing new on the Optane roadmap.it’s obvious that Optane is dead.
Intel will say that they are “committed” to the technology but in the end they are as commited as they have been to Itanium CPUs as a zombie platform.
Lasertoe – the inference side can do well on the CPU. One does not incur the cost to go over a PCIe hop.
On the HPC side, acceleration is big, but not every system is accelerated.
Intel, being fair, is targeting having chips that have a higher threshold before a system would use an accelerator. It is a strange way to think about it, but the goal is not to take on the real dedicated accelerators, but it is to make the threshold for adding a dedicated accelerator higher.
“not every system is accelerated”
Yes, but every system where everything needs to be rewritten and optimized to make real use of AVX-512 fares better with accelerators.
——————
“the inference side can do well on the CPU”
I acknowledge the threshold argument for desktops (even though smartphones are showing how well small on-die inference accelerators work and winML will probably bring that to x86) but who is running a server where you just have very small inference tasks and then go back to other things?
Servers that do inference jobs are usually dedicated inference machines for speech recognition, image detection, translation etc.. Why would I run those tasks on the same server I run a web server or a DB server? The threshold doesn’t seem to be pushed high enough to make that a viable option. Real-world scenarios seem very rare.
You have connections to so many companies. Have you heard of real intentions to use inference on a server CPU?
Even Facebook is doing distributed inference/ training on CPUs. Organizations 100% do inferencing on non-dedicated servers, and that is the dominant model.
Hmmm… the real issue with using AVX-512 is the down clock and latency switching between modes when you’re running different things on the same machine. It’s why we abandoned it.
I’m not really clear on the STH conclusion here tbh. Unless I need Optane PMem, why wouldn’t I buy the more mature platform that’s been proven in the market and has more lanes/cores/cache/speed?
What am I missing?
Ahh okay, the list prices on the Ice Lake SKUs are (comparatively) really low.
Will be nice when they bring down the Milan prices. :)
@Patrick (2) We’ll buy Ice Lake to keep live migration on VMware. But YOU can buy whatever you want. I think that’s exactly the distinction STH is trying to show
I meant for new server application, not legacy like fb.
Facebook is trying to get to dedicated inference accelerators, like you reported before with their Habana/Intel nervana partnerships, or this:
https://engineering.fb.com/2019/03/14/data-center-engineering/accelerating-infrastructure/
Regarding the threshold: Fb is probably using dedicated inference machines, so the inference performance threshold is not about this scenario.
So the default is a single Lewisburg Refresh PCH connected to 1 socket? Dual is optional? Is there anything significant remaining attached to the PCH to worry about non-uniform access, given anything high-bandwidth will be PCIe 4.0?
Would be great if 1P 7763 was tested to show if EPYC can still provide the same or more performance for half the server and TCO cost :D
Sapphire Rapids is supposed to be coming later this year, so Intel is going 28c->40c->64c within a few months after 4 years of stagnation.
Does it make much sense for the industry to buy ice lake en masse with this roadmap?
“… a major story is simply that the dual Platinum 8380 bar is above the EPYC 7713(P) by some margin. This is important since it nullifies AMD’s ability to claim its chips can consolidate two of Intel’s highest-end chips into a single socket.”
I would be leery of buying an Intel sound bite. I may distract them from focusing on MY interests.
Y0s – mostly just SATA and the BMC, not a big deal really unless there is the QAT accelerated PCH.
Steffen – We have data, but I want to get the chips into a second platform before we publish.
Thomas – my guess is Sapphire really is shipping 2022 at this point. But that is a concern that people have.
Peter – Intel actually never said this on the pre-briefs, just extrapolating what their marketing message will be. AMD has been having a field day with that detail and Cascade Lake.
I dont recall any mention of HCI, which I gather is a major trend.
A vital metric for HCI is interhost link speeds, & afaik, amd have a big edge?
Patrick, did you notice the on package FPGA on the Sapphire Rapids demo?
Patrick, great work as always! Regarding the SKU stack: call me cynical but it looks like a case of “If you can’t dazzle them with brilliance then baffle them with …”.
@Thomas
Gelsinger said: “We have customers testing ‘Sapphire Rapids’ now, and we’ll look to reach production around the end of the year, ramping in the first half of 2022.”
That doesn’t sound like the average joe can buy SPR in 2021, maybe not even in Q1 22.
Is the 8380 actually a single die? That would be quite a feat of engineering getting 40 cores on a single NUMA node.
I was wondering about the single die, too. fuse.wikichip has a mesh layout for the 40 cores.
https://fuse.wikichip.org/news/4734/intel-launches-3rd-gen-ice-lake-xeon-scalable/
What on earth is this sentence supposed to be saying?
“Intel used STH to confirm it canceled which we covered in…”