Intel Xeon Gold 6132 Benchmarks
For this exercise, we are using our legacy Linux-Bench scripts which help us see cross-platform “least common denominator” results we have been using for years as well as several results from our updated Linux-Bench2 scripts. At this point, our benchmarking sessions take days to run and we are generating well over a thousand data points. We are also running workloads for software companies that want to see how their software works on the latest hardware. As a result, this is a small sample of the data we are collecting and can share publicly. Our position is always that we are happy to provide some free data but we also have services to let companies run their own workloads in our lab, such as with our DemoEval service. What we do provide is an extremely controlled environment where we know every step is exactly the same and each run is done in a real-world data center, not a test bench.
We also wanted to note that our dataset is focused on pre-Spectre and Meltdown results at this point. Starting with our Ubuntu 18.04 generation of results we will have comparison points to the new reality. The Spectre and Meltdown patches to hurt Intel’s performance in many tests. At the same time, as of writing this article, patches are still being worked on. Likewise, software is being tuned to deal with the impacts of the patches. Given this, we are going to give the ecosystem some time to settle before publishing new numbers.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read.
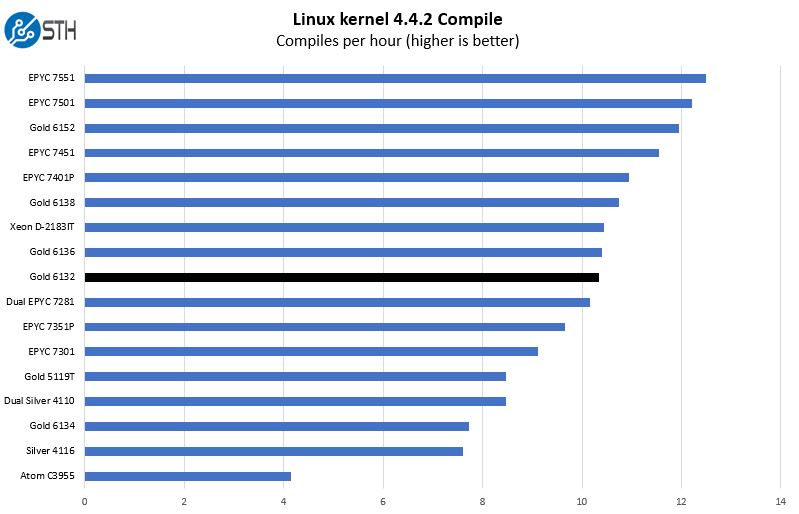
Overall the Intel Xeon Gold 6132 performs very well. We added the dual AMD EPYC and some single EPYC 7000 series options to the chart to give a cross-platform comparison. If you are wondering why the Intel Xeon Gold 6134 is so much lower on this list, those CPUs are designed as frequency and cache optimized parts, much like we saw with the Intel Xeon Silver 4112. The Intel numbering does not reflect linear performance scaling in multi-threaded workloads.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads. Given the speed of this generation of CPUs, our older generation 4K results did not show a large enough difference between CPUs. Instead, we are using our Linux-Bench2 8K results to show differences.
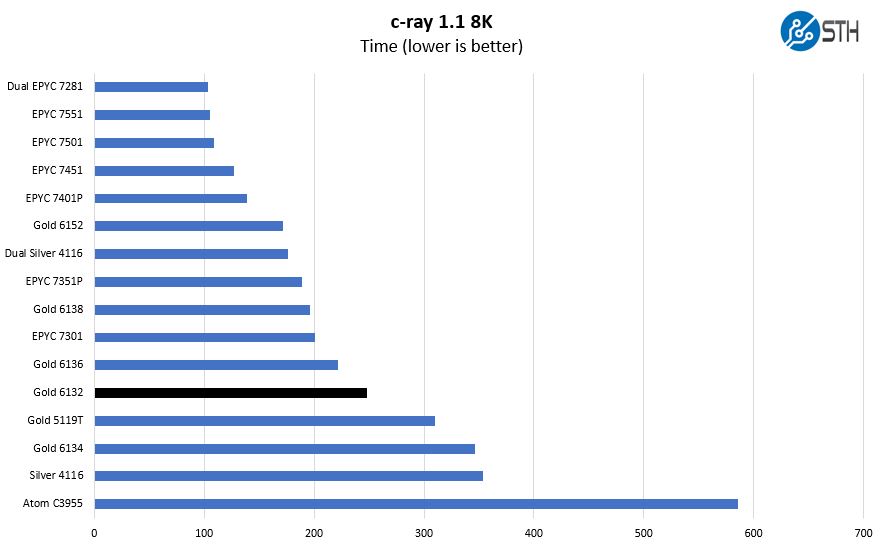
This is highly core, frequency, and cache speed biased as a benchmark. One can see how there is a large performance gain between the Intel Gold 6132 and the Intel Xeon Gold 5119T even though they are both 14 cores. The Intel Xeon Gold 6132 has a higher TDP and higher clock speeds which allow for more performance here.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
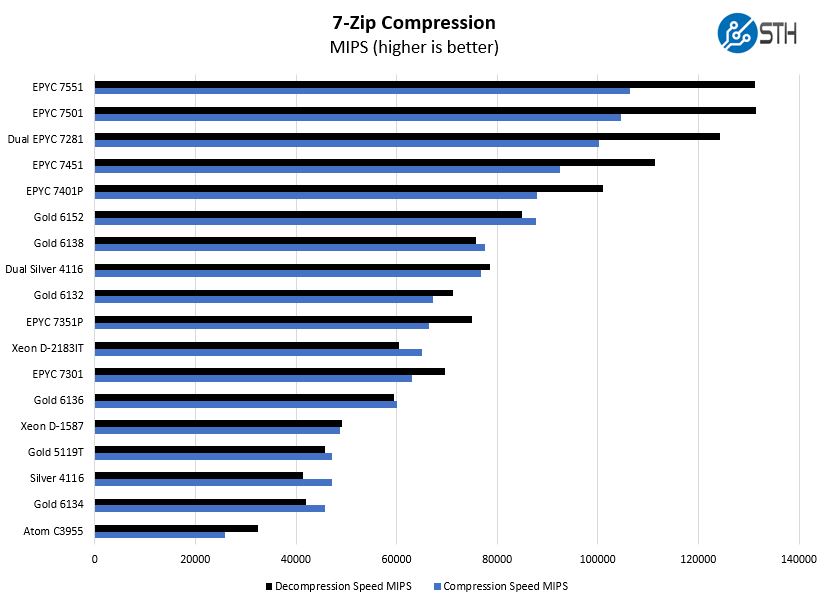
Here the AMD EPYC chips perform very well. The 14 core Intel Xeon Gold 6132 is almost able to keep pace with the dual CPU Intel Xeon Silver 4116 setup that has almost twice the number of cores between the two sockets.
NAMD Performance
NAMD is a molecular modeling benchmark developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. More information on the benchmark can be found here. We are going to augment this with GROMACS in the next-generation Linux-Bench in the near future. With GROMACS we have been working hard to support Intel’s Skylake AVX-512 and AVX2 supporting AMD Zen architecture. Here are the comparison results for the legacy data set:
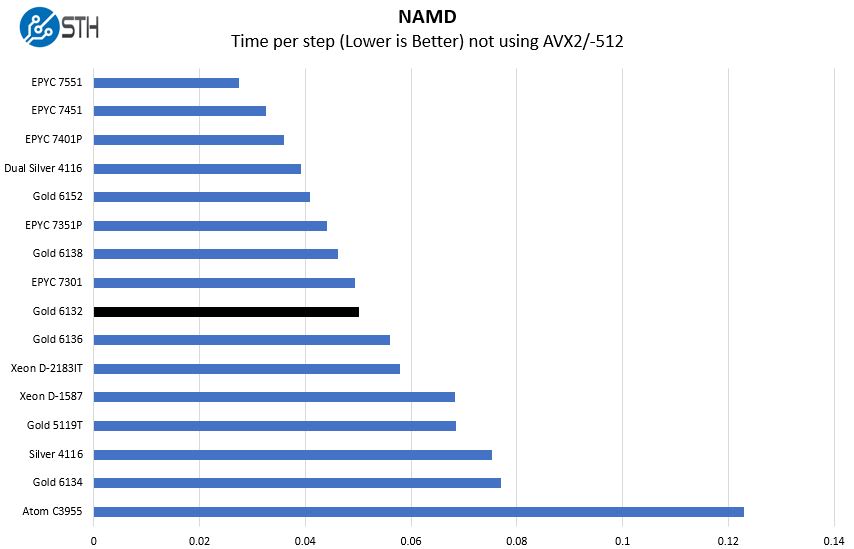
Without AVX-512 the AMD EPYC performs extremely well as does the Xeon Gold 5119T. We are going to see that this picture will change in our GROMACS results.
Sysbench CPU test
Sysbench is another one of those widely used Linux benchmarks. We specifically are using the CPU test, not the OLTP test that we use for some storage testing.
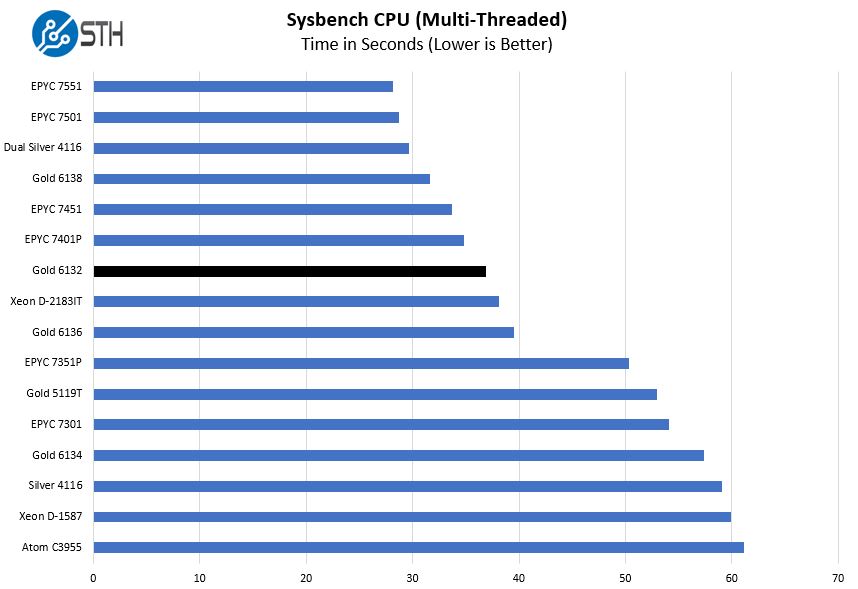
Overall, performance is excellent. We can see strong multi-threaded performance due to high clock speeds and 14 cores. Even with only 14 cores it is able to sit between the AMD EPYC 7351P and EPYC 7401P single socket options. Although the EPYC chips are less expensive, if you are in a per-core licensing model, there is a good chance Xeon Gold 6132 will be less expensive on a TCO basis.
We also wanted to take a look at results for single threaded performance.
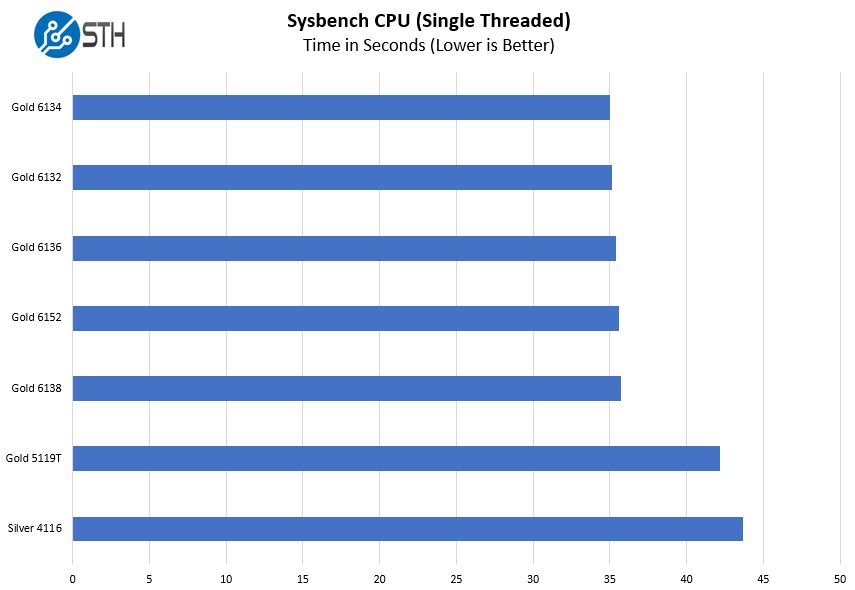
These Xeon Gold 6100 series parts are limited to 3.7GHz maximum turbo clock. As a result, we get a fairly consistent line across the boards with some allowances for test variations. You can also see the significant performance gains in single threaded versus the lower-series chips.
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
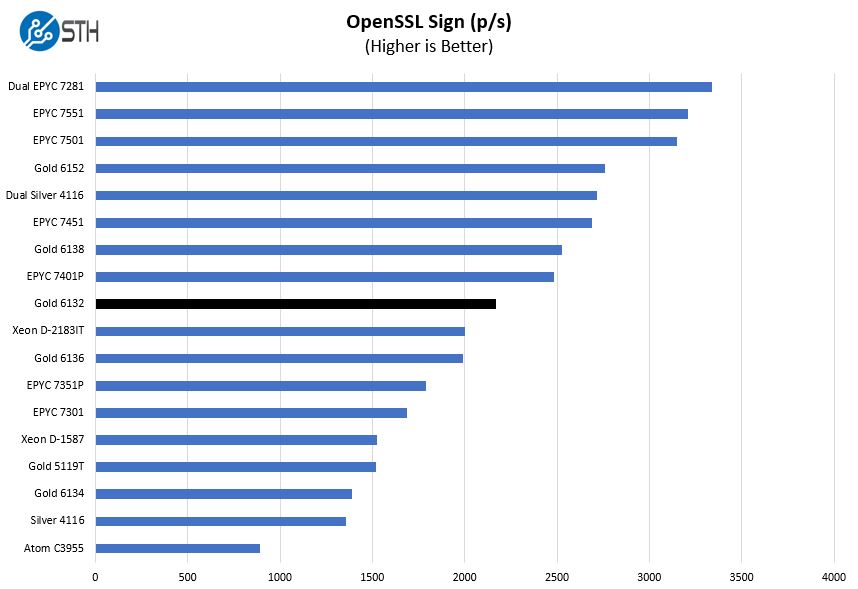
And verify:
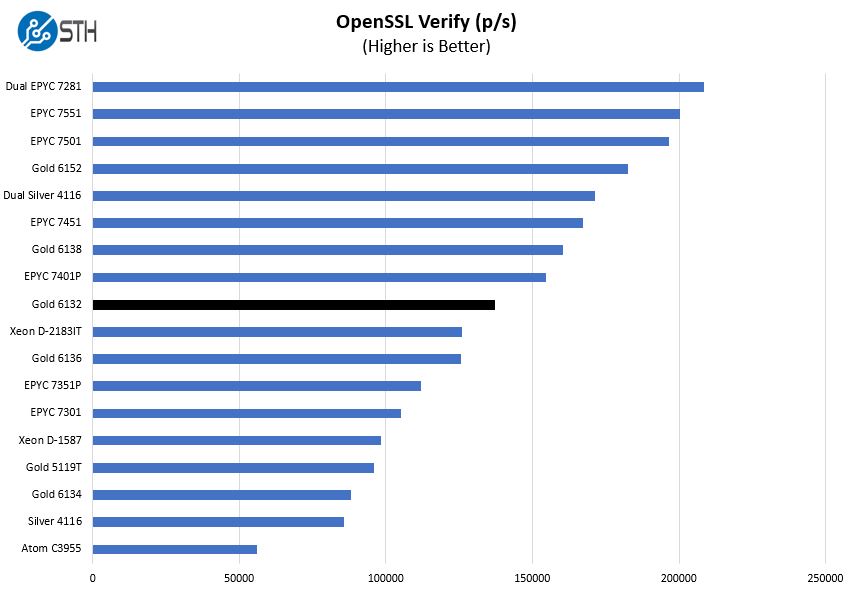
Overall, these are strong results where the Xeon Gold 6132 with 14 cores performs about on par with a 20 core AMD EPYC. Again, if you have OpenSSL and per-core licensing, then these are strong chips.
UnixBench Dhrystone 2 and Whetstone Benchmarks
Some of the longest-running tests at STH are the venerable UnixBench 5.1.3 Dhrystone 2 and Whetstone results. They are certainly aging, however, we constantly get requests for them, and many angry notes when we leave them out. UnixBench is widely used so we are including it in this data set. Here are the Dhrystone 2 results:
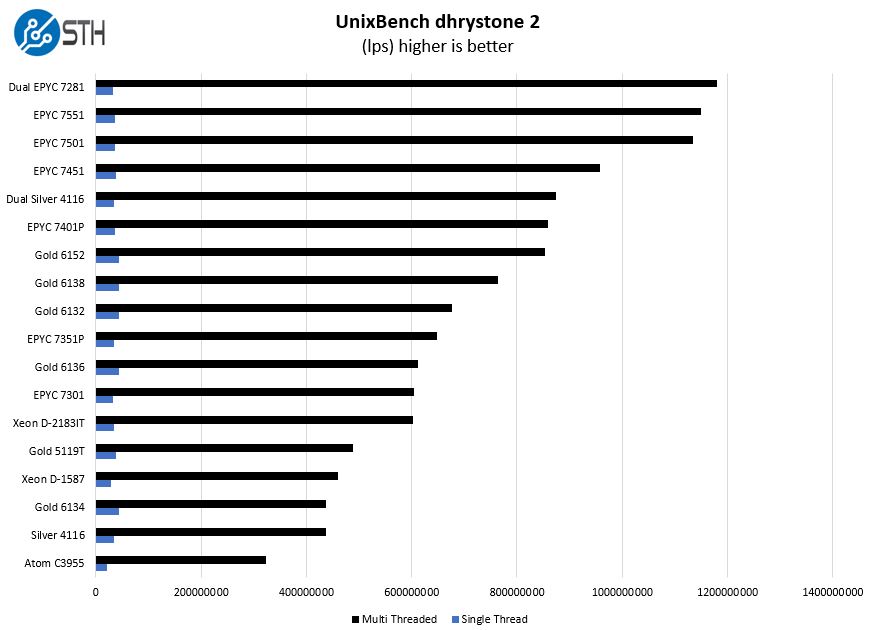
And the whetstone results:
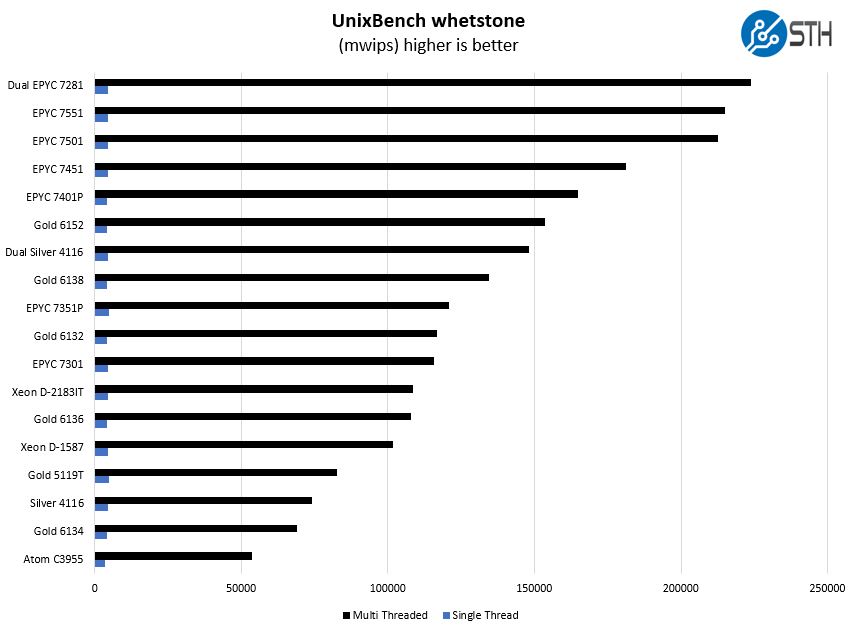
There is not much more to say here. The Xeon Gold 6132 falls in-line which what we expect at this point. Instead, let us look at the GROMACS application case to see what happens when we can utilize the fat AVX-512 pipeline.
GROMACS STH Small AVX2/ AVX-512 Enabled
We have a small GROMACS molecule simulation we previewed in the first AMD EPYC 7601 Linux benchmarks piece. In Linux-Bench2 we are using a “small” test for single and dual socket capable machines. Our medium test is more appropriate for higher-end dual and quad socket machines. Our GROMACS test will use the AVX-512 and AVX2 extensions if available.
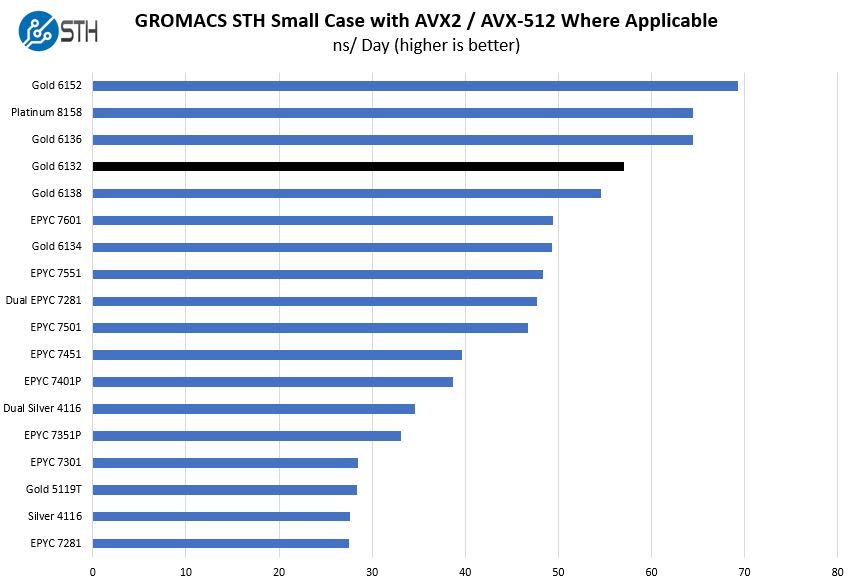
Here you can see the power of the Intel Xeon Gold 6132’s dual FMA AVX-512. If you are using heavy AVX-512 applications for simulation, the Xeon Gold 6100 series is where you want to be in the lineup. Note, this is a contrast to the non-AVX2/ AVX-512 NAMD benchmark.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and are ready to start sharing results:
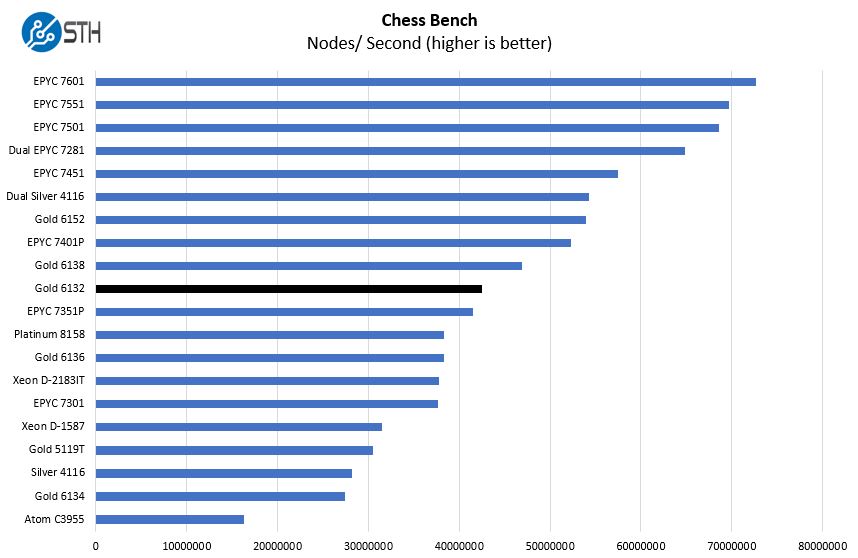
When it comes to our chess benchmark, the Intel Xeon Gold 6132 performs about where we would expect, with slightly better per-core performance than AMD EPYC. The Intel Xeon Gold 5119T is the next-level down 14 core part and you can clearly see where the extra TDP headroom and clock speeds help the Gold 6132.



{kind=link}
When you want some real speed with NAMD, Gromacs etc.. the GPU way is a lot faster and cheaper.
AVX512 is dead on arrival.
https://www.pugetsystems.com/labs/hpc/NAMD-Performance-on-Xeon-Scalable-8180-and-8-GTX-1080Ti-GPUs-1124/
@Misha Do remember that if you can’t use GeForce GPUs, professional GPUs cost as much as or more than two high-end CPUs, will consume equal amount of power, and will often end up as a bottleneck for strong-scaling. For NAMD AVX512 may not be worth it, but NAMD does not have tuned AVX512 SIMD kernels.
However, in GROMACS we have i) redesigned the algorithms from ground-up for wide-SIMD architectures (rather than shoehorning old algorithms into wide SIMD units) ii) implemented and tuned SIMD code (note that tuning here means *both* choosing the right algorithm parameters and the right SIMD intrinsics) for a dozen+ SIMD architectures which makes our code very efficient. While GPUs will win in non-scaling runs, in strong-scaling use-cases CPU nodes are still very strong and if you consider the cost of a simulation on Tesla rather than GeForce, the advantage of GPUs will not be huge.