The “Gotchas” of QAT
Performance is very good with Intel QAT. That is frankly what we would expect with any acceleration technology, even AI accelerators in that domain. All of this is not without a few “gotchas”.
- QAT is not static. Over time, there are new ciphers added as an example. That means, a cipher you want to use, may require a specific version of QAT. WireGuard has become popular and its default bulk encryption transform is ChaCha20/Poly1305. That was not supported by QAT until what we call the QAT v3 generation. WireGuard has become massively popular, but the QAT hardware offload support for the main cipher folks use did not come until recent hardware. So if you have a remote endpoint on an Atom C3000 as an example, it is a QAT platform that is supported for several more years, but it does not have the correct cipher support.
- QAT still requires enablement. Today, we think of things like AES-NI as being “free” and they “just work” with most software. QAT is a technology we first started seeing at STH in 2013, but it is also one that is nowhere near transparent today. Work needs to be done and it is still very much an Intel technology.
- If you do very little encryption/ decryption or compression/ decompression then you will not get a large benefit from this. For example, if you are running computational fluid dynamics farms or rendering farms, then this is going to have a relatively minimal impact on your workloads.

These are actually quite important for the overall discussion. The more Intel pushes QAT into its product line, we would expect to see better product enablement. At the same time, that enablement has been slow thus far. The caveat is that the adoption is actually fairly good in the markets that use a lot of crypto/ compression acceleration. Moving beyond today’s adoption levels requires a step function in accessibility.
Intel Sapphire Rapids Next-Gen QAT Integration
Since one of the “gotchas” of QAT has been the difficulty of getting an accelerator, we can now show that the next-generation of mainstream Xeons will have this technology. We showed this in a recent article, but it is also important to show the next-gen accelerator performance is another level entirely. This is really the impact when it comes to compression:
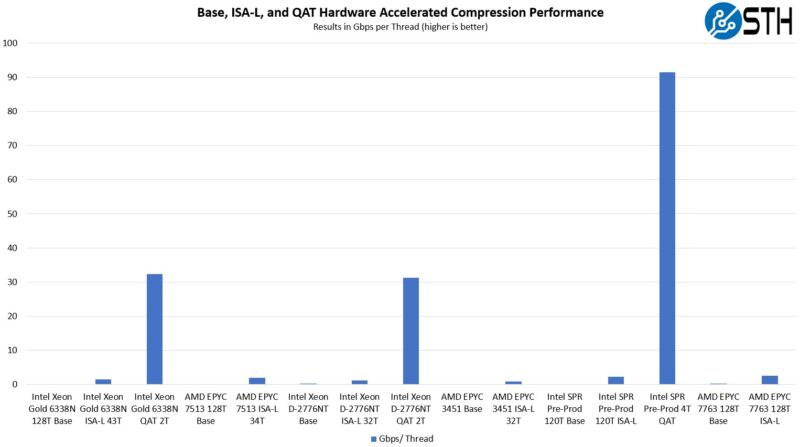
Here is the scale of the impact of having a next-generation accelerator in Sapphire Rapids compared to what we are looking at today with Xeon D-2700:
While at 60 cores per CPU one can argue to just keep workloads on cores. At lower core counts, the accelerators will have an outsized impact since the accelerators only need a minimum number of threads to capture their performance. That means more resources to do other work.

Perhaps the bigger impact is that bringing QAT to a broader set of chips will hopefully help adoption. This is going to be the performance that one gets going forward without adding cards. One can also get integrated acceleration without having to add a PCIe accelerator.
Final Words
So after a lot of testing, I walked away with several key takeaways:
- I reached out to AMD before using the EPYC 3451, but it still felt strange using it. The first time we reviewed the EPYC 3451 was in 2020, so one can say it is “not that old” for the embedded space. On the other hand, it certainly feels old now.
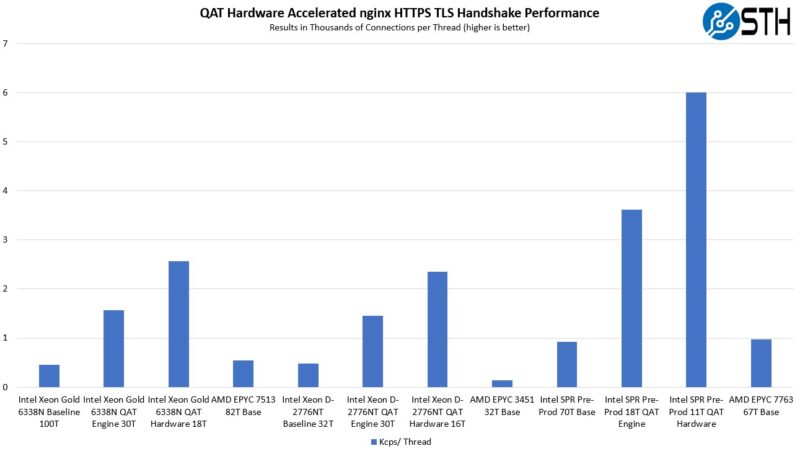
- The built-in QAT acceleration does very well. Intel has different levels of built-in QAT acceleration, but I wanted to test the maximum performance that I could so we were using a higher-end SKU.
- Much of the performance gains that are available actually do not need QAT. Instead, things like using ISA-L gave big gains for both AMD and Intel. QAT Engine is an example where that is available for Ice Lake and newer CPUs. These gains are a GitHub journey away.
- My hope is that in the future, more workloads will start to take advantage of QAT. As it transitions into a more mainstream feature with Sapphire Rapids, the accelerator will become available to many more users. A big part of scaling compute in the future will be accelerators, whether for things like AI or what we showed here with compression and crypto performance. There are areas where we can get outsized performance gains and lower data center power consumption by using them.
One of the challenges for STH going forward is handling the complexity of showing new accelerators and just the sheer number of them that will be utilized in the future. For our longtime readers, hopefully, this is becoming apparent. QAT is one of those areas that has been around for some time, is in use by companies every day, and so it is a bit easier to show than some of the future pieces we are working on. Acceleration in the data center is a key trend.

This was a fun opportunity to show the Xeon D series that STH has been working with since its launch, with a built-in accelerator that is a major industry trend.



{kind=link}
You are probably under NDA but did you learn something about the D-2700 ethernet switching capabilities? Like for example dataplane pipeline programmability like the Mount Evans/E2000 network building block ? As THAT would be a gamechanger for enterprise edge use!!!
Hi patrik, also a follow up question did you try to leverage the CCP (crypto co-processor) on AMD EPYC 3541 for offloading cipher and HMAC?
Hi patrik, thanks for the review. couple of pointers and query
1. Here we are getting better performance with two cores instead of using the entire chip for less performance.
– A physical CPU is combination of front-end (fetch, decode, opcode, schedule) + back-end (alu, simd, load, store) + other features. So when SMT or HT is enabled, basically the physical core is divided into 2 streams at the front end of the execution unit. While the back end remains the same. with help of scheduler, outof order and register reorder the opcodes are scheduled to various ports (backend) and used. So ideally, we are using the alu, simd which was not fully leveraged when no-HT or no-SMT was running. But application (very rarely and highly customized functions) which makes use of all ports (alu, load, store, simd) will not see benefit with SMT (instead will see halving per thread).
2. is not Intel D-2700 atom (Tremont) based SoC https://www.intel.com/content/www/us/en/products/sku/59683/intel-atom-processor-d2700-1m-cache-2-13-ghz/specifications.html . If yes, these cores makes use of SSE and not AVX or AVX512. Maybe I misread the crypto-compression numbers with ISAL & IPSEC-MB, as it will make use of SSE unlike AMD EPYC 3451. hence CPU SW (ISAL & IPSEC_MB) based numbers should be higher on AMD EPYC 3541 than D2700?
3. did you try to leverage the CCP (crypto co-processor) on AMD EPYC 3541 for offloading cipher and HMAC?
people don’t use the ccp on zen 1 because the sw integration sucks and it’s a different class of accelerator than this. qat is used by real world even down to pfsense vpns.
D-2700 is ice lake cores not Tremont. They’re the same cores as in the big Xeon’s not the Tremont cores. I’d also say if they’re testing thread placement like which ccd they’re using, they know about SMT. SMT doesn’t halve performance in workloads like these.
I’ve learned AMD just needs new chips in this market. They’re still selling Zen 1 here.
@nobo `if you are talking about ccp on zen 1` on linux, this could be true. But have you tried DPDK same as ISAL with DPDK?
@AdmininNYC thank you for confirming it is icelake-D and not Tremont cores, which confirms it has AVX-512. Checking Nginx HTTPS Performance, Compression Performance comparison with SW accelerated libraries, show AMD EPYC 3451 (avx2) is on par with Xeon-D icelake (avx512). Only test cases which use VAES (AVX512) there is a leap in performance in SW libraries. It does sound really odd right?
Running ISAL inflate-deflate micro benchmarks on SMT threads clearly shows half on ADM EPYC. I agree in real use cases, not all cores will be feed 100% compression operation since it will have to run other threads, interrupts, context switches.
Something is wrong with this sentence fragment: “… quarter of the performance of AMD’s mainstream Xeons.”