Testing Intel QAT Encryption: IPsec VPN Performance
IPsec VPN performance is another great example of where commercial providers figured out that QAT hardware acceleration was a huge performance boost. IPsec VPNs are a mature and widely deployed technology, and a big part of establishing secure connections over the public Internet is encryption. As a result, we took a look at the IPsec VPN performance using a few cases.
- Intel Xeon D-2776NT with:
- QAT Engine Software Acceleration using the Intel Multi-Buffer Crypto for IPsec library that you can find on GitHub.
- QAT Hardware Acceleration
- AMD EPYC 3451 with:
- AES offload, but not VAES since Milan does not support AVX-512 VAES
On this one, we include the AMD EPYC 3451 numbers to stay consistent. Many of the instructions the QAT Engine’s software acceleration uses are not present in the EPYC 3000 series. Still, we are going to show the results, but perhaps the most important point to look at is the Intel scaling for this.
Here is the basic diagram. We are using the DPDK IPSec-secgw to measure how many packets/ Gbps we can process per second using IPsec. We are using the DPDK libraries here since DPDK is widely used in Intel, AMD, and Arm solutions at this point. We are using Cisco T-Rex as our load generator, and we are using an acceptable packet drop rate maximum of 0.00001%.
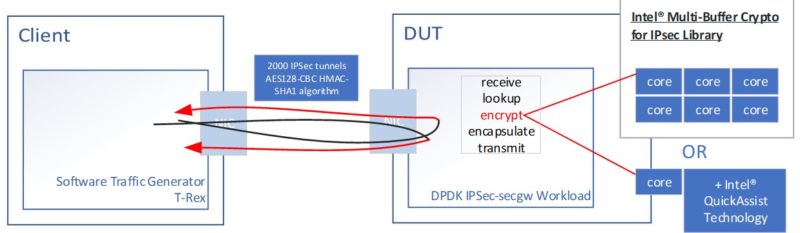
When we talk about the QAT Engine here, we are using the cores and utilizing things like VAES (vectorized AES) instructions on the Ice Lake cores. This is different from using the Intel QAT hardware accelerator, even though one could call it a form of acceleration.
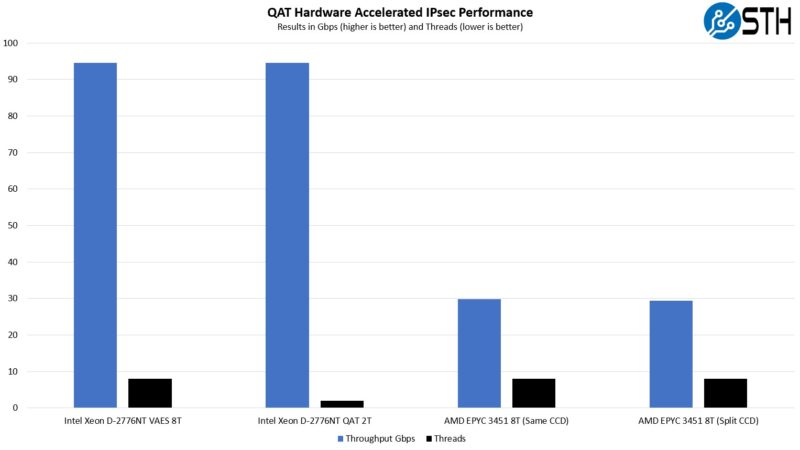
Here, we see the use of VAEX helps Intel quite a bit. We are using eight threads max here because I wanted to show something that many people discuss but do not show data on. What happens when we cross CCDs. So instead, we are keeping eight cores constant and just using the best acceleration we can.
Here is a look at this result in a similar Gbps/ core view.
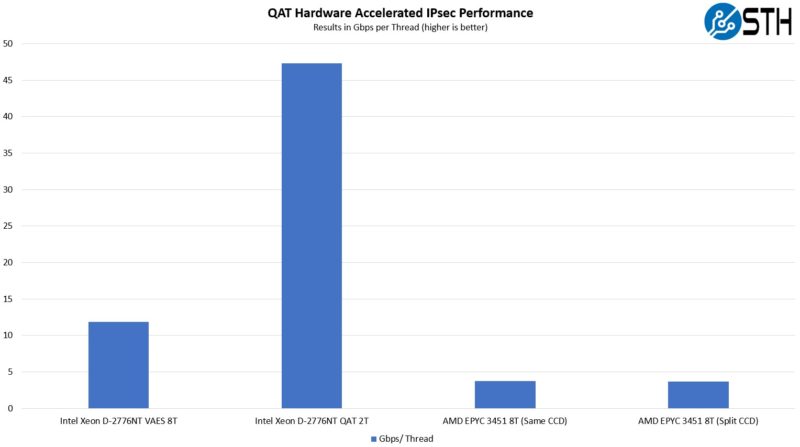
What we can see is that the QAT accelerator helps a lot here, as do the VAES, versus just using traditional acceleration like AES-NI, like the AMD EPYC Milan CPU is using.
This will make more of an impact in a future piece we are going to show you, but for now, the Gbps per thread jump from using QAT is much larger than Intel versus AMD without the acceleration.
Some folks are going to ask about the performance of the EPYC 3451 because there are two logical ways one can set it up. One can test either with all eight threads running on one CCD’s cores. The other way is to split them with four on each CCD. As part of this entire exercise we looked at thread placement as well. This was an extra step, but it is part of the reason this took ~2-3 days just to get these few test cases optimized for the mainstream server and embedded parts. Here are the two test cases for AMD:
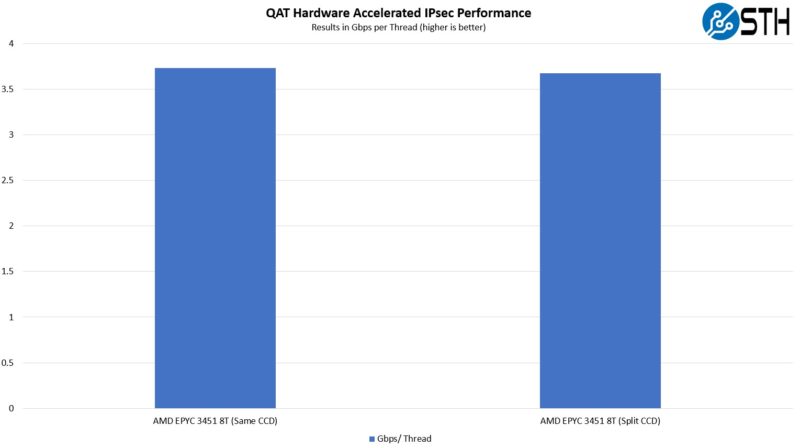
The impact of splitting the workload across CCDs had only a ~2% loss in performance. The Infinity Fabric link between the two CCDs was not saturated by any means at 30Gbps, but there was a performance impact. Some (AMD) would likely say that the proper way to look at this is the higher number, and that makes a lot of sense since that is the best possible, and we are looking at Intel with accelerators. Others would point to the fact that in many real-life scenarios, the IPsec VPN may not be pinned to specific cores on the CCD attached to the NIC, so the slightly lower figure is more realistic. Since we actually underwent the optimization search effort, we have both data points for you.
Next, let us take a look at nginx performance.



{kind=link}
You are probably under NDA but did you learn something about the D-2700 ethernet switching capabilities? Like for example dataplane pipeline programmability like the Mount Evans/E2000 network building block ? As THAT would be a gamechanger for enterprise edge use!!!
Hi patrik, also a follow up question did you try to leverage the CCP (crypto co-processor) on AMD EPYC 3541 for offloading cipher and HMAC?
Hi patrik, thanks for the review. couple of pointers and query
1. Here we are getting better performance with two cores instead of using the entire chip for less performance.
– A physical CPU is combination of front-end (fetch, decode, opcode, schedule) + back-end (alu, simd, load, store) + other features. So when SMT or HT is enabled, basically the physical core is divided into 2 streams at the front end of the execution unit. While the back end remains the same. with help of scheduler, outof order and register reorder the opcodes are scheduled to various ports (backend) and used. So ideally, we are using the alu, simd which was not fully leveraged when no-HT or no-SMT was running. But application (very rarely and highly customized functions) which makes use of all ports (alu, load, store, simd) will not see benefit with SMT (instead will see halving per thread).
2. is not Intel D-2700 atom (Tremont) based SoC https://www.intel.com/content/www/us/en/products/sku/59683/intel-atom-processor-d2700-1m-cache-2-13-ghz/specifications.html . If yes, these cores makes use of SSE and not AVX or AVX512. Maybe I misread the crypto-compression numbers with ISAL & IPSEC-MB, as it will make use of SSE unlike AMD EPYC 3451. hence CPU SW (ISAL & IPSEC_MB) based numbers should be higher on AMD EPYC 3541 than D2700?
3. did you try to leverage the CCP (crypto co-processor) on AMD EPYC 3541 for offloading cipher and HMAC?
people don’t use the ccp on zen 1 because the sw integration sucks and it’s a different class of accelerator than this. qat is used by real world even down to pfsense vpns.
D-2700 is ice lake cores not Tremont. They’re the same cores as in the big Xeon’s not the Tremont cores. I’d also say if they’re testing thread placement like which ccd they’re using, they know about SMT. SMT doesn’t halve performance in workloads like these.
I’ve learned AMD just needs new chips in this market. They’re still selling Zen 1 here.
@nobo `if you are talking about ccp on zen 1` on linux, this could be true. But have you tried DPDK same as ISAL with DPDK?
@AdmininNYC thank you for confirming it is icelake-D and not Tremont cores, which confirms it has AVX-512. Checking Nginx HTTPS Performance, Compression Performance comparison with SW accelerated libraries, show AMD EPYC 3451 (avx2) is on par with Xeon-D icelake (avx512). Only test cases which use VAES (AVX512) there is a leap in performance in SW libraries. It does sound really odd right?
Running ISAL inflate-deflate micro benchmarks on SMT threads clearly shows half on ADM EPYC. I agree in real use cases, not all cores will be feed 100% compression operation since it will have to run other threads, interrupts, context switches.
Something is wrong with this sentence fragment: “… quarter of the performance of AMD’s mainstream Xeons.”