Intel Xeon D-2183IT Benchmarks
For this exercise, we are using our legacy Linux-Bench scripts which help us see cross-platform “least common denominator” results we have been using for years as well as several results from our updated Linux-Bench2 scripts. At this point, our benchmarking sessions take days to run and we are generating well over a thousand data points. We are also running workloads for software companies that want to see how their software works on the latest hardware. As a result, this is a small sample of the data we are collecting and can share publicly. Our position is always that we are happy to provide some free data but we also have services to let companies run their own workloads in our lab, such as with our DemoEval service. What we do provide is an extremely controlled environment where we know every step is exactly the same and each run is done in a real-world data center, not a test bench.
We are going to show off a few results, and highlight a number of interesting data points in this article.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read:
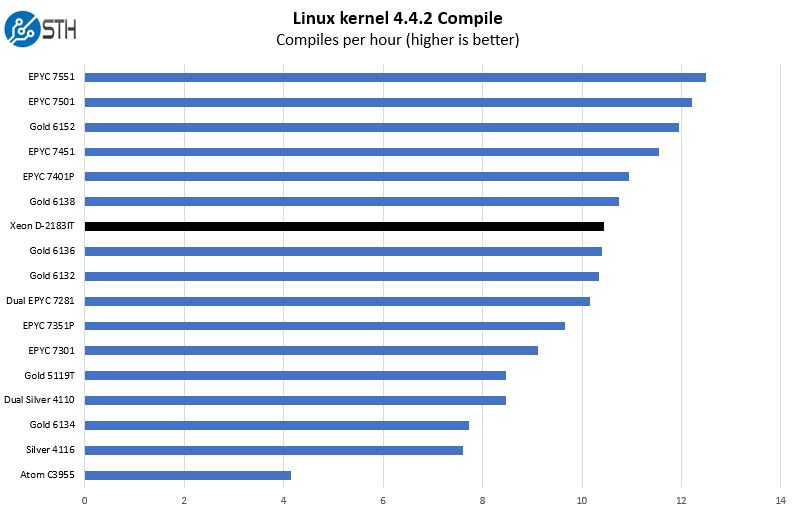
Gone are the days where an Intel Xeon D means lower performance for significantly lower power consumption. Here, the Intel Xeon D-2183IT sits in the middle of the Intel Xeon Gold 613x range in terms of performance. Looking at previous generations and embedded parts, we wanted to show why we are focusing on the broader compute range instead.
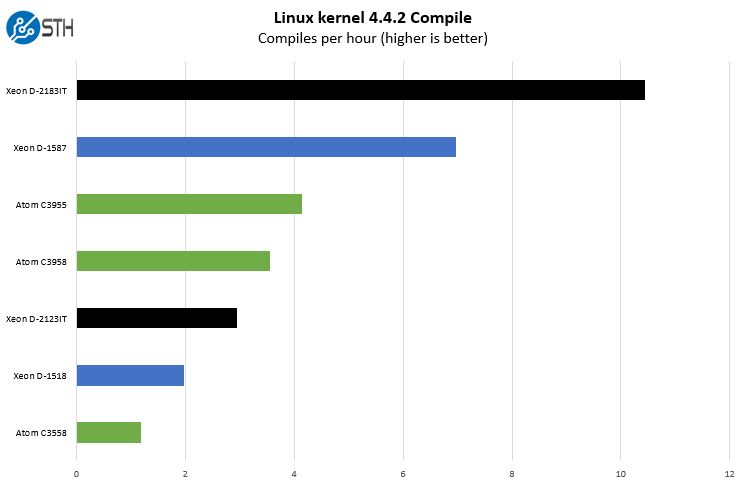
As you can see, there is a massive speed-up over the Xeon D-1587. We will note, and show later, that the Xeon D-1587 is a lower power part and since it is an embedded part, it is still being actively sold. It is probably better to look at the Xeon D-1500 series as a lower power/ performance range between the Intel Atom C3000 series and the Xeon D-2100 series at this point.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads. We are going to use both our legacy 4K result along with our new Linux-Bench2 8K render to show differences.
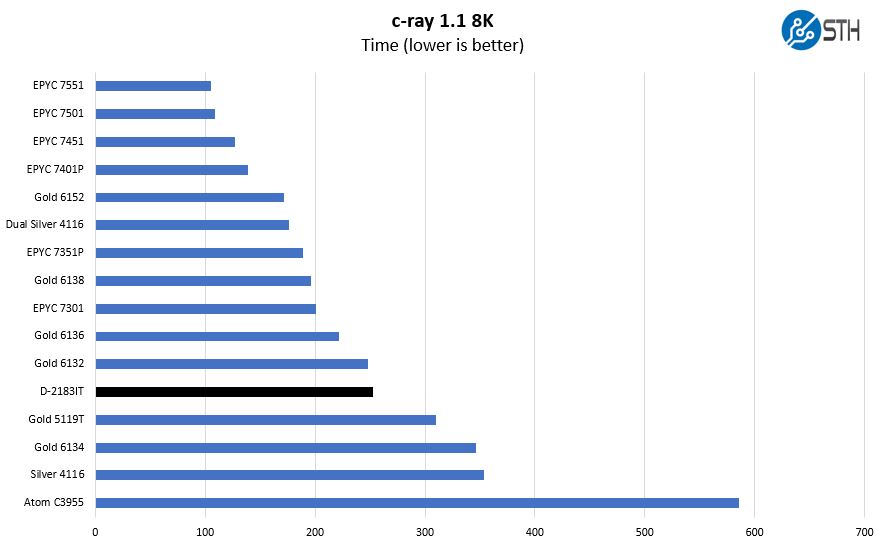
Here the chip falls almost even with the Intel Xeon Gold 6132 in single socket configurations and well ahead of the Gold 5119T.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
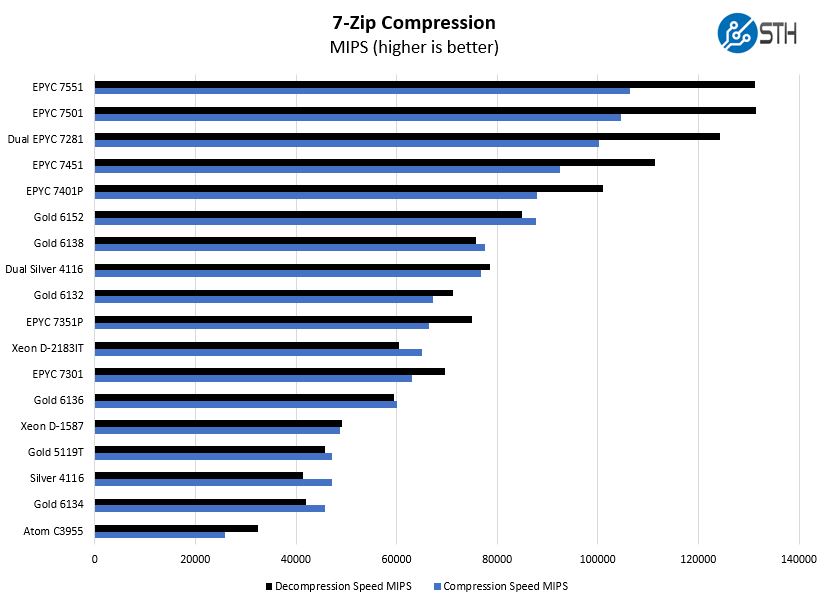
Moving to compression, we can see that the chip is competitive with 16 core AMD EPYC offerings in terms of performance, despite using less power. Being fair, EPYC is designed for bigger platforms and is significantly less expensive. Still, we see the performance about where we would expect from the 16 core Xeon D.
NAMD Performance
NAMD is a molecular modeling benchmark developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. More information on the benchmark can be found here. We are going to augment this with GROMACS in the next-generation Linux-Bench in the near future. With GROMACS we have been working hard to support Intel’s Skylake AVX-512 and AVX2 supporting AMD Zen architecture. Here are the comparison results for the legacy data set:
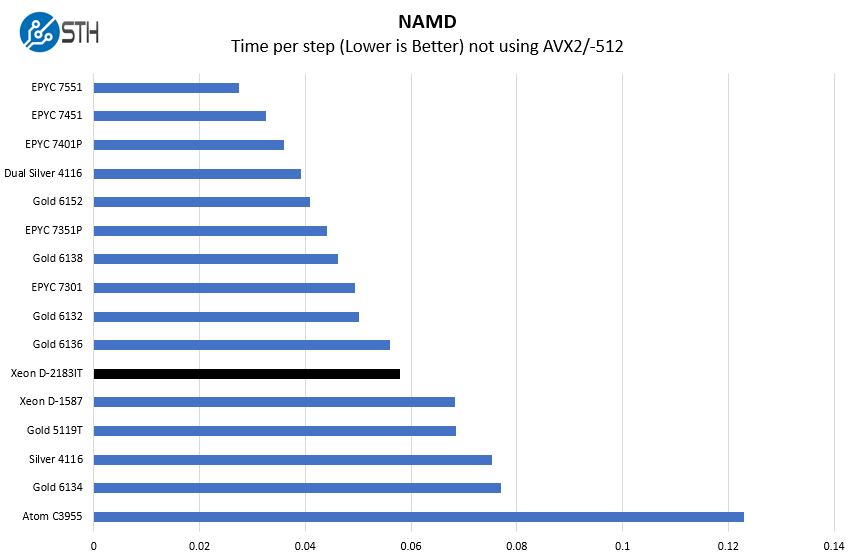
We again get performance around the Intel Xeon Gold 613x line. One can also see a speedup of more than 2x over the highest performance Intel Atom C3955.
Sysbench CPU test
Sysbench is another one of those widely used Linux benchmarks. We specifically are using the CPU test, not the OLTP test that we use for some storage testing.
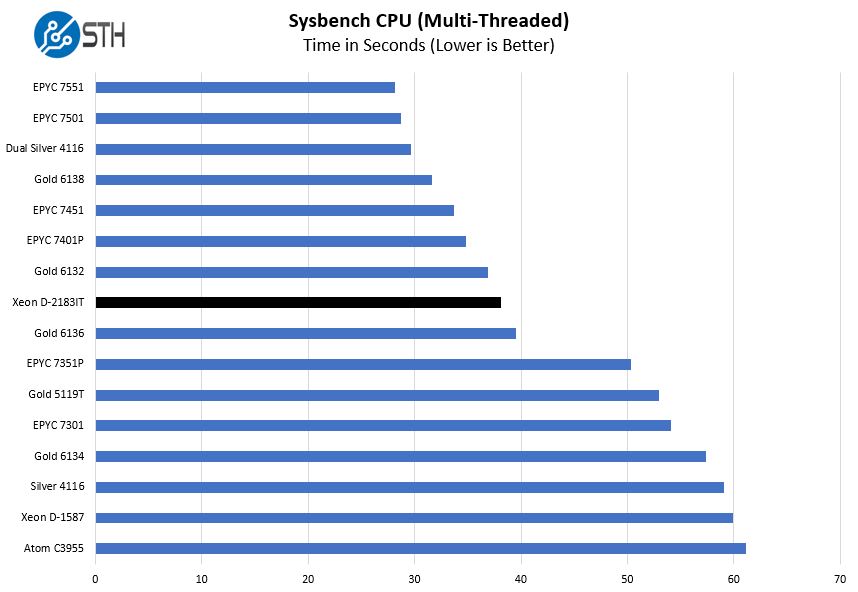
Again, this chip sites just between the Intel Xeon Gold 6136 and Gold 6132.
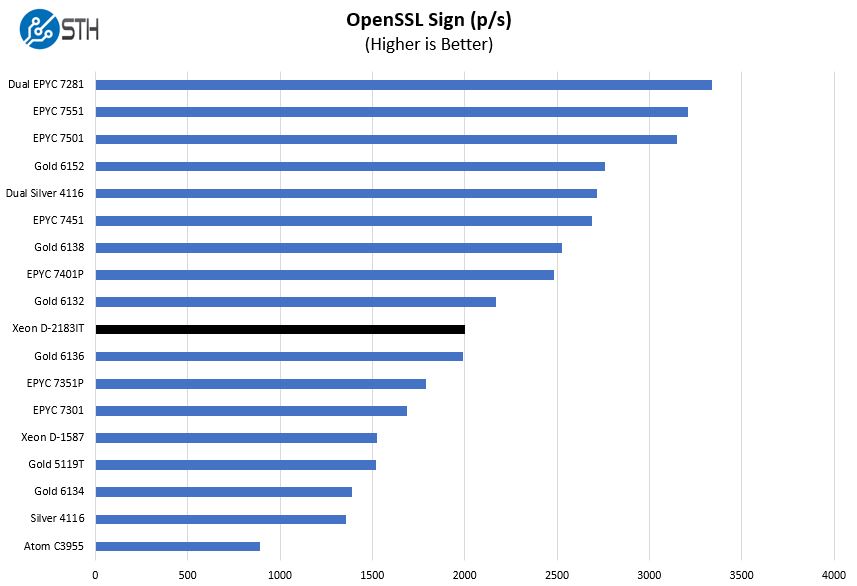
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
here are the verify results:
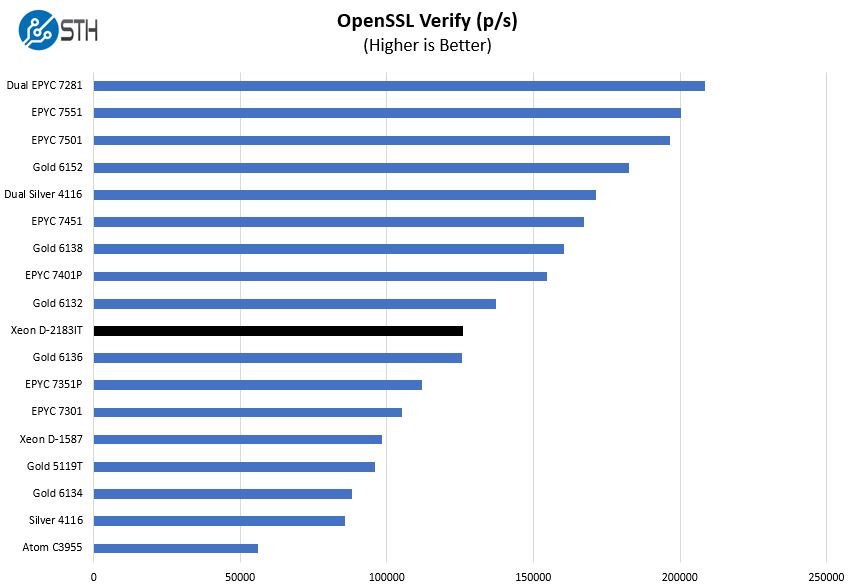
Frankly, this is awesome performance from the Intel embedded part, putting it between the AMD EPYC 7351P and AMD EPYC 7401P parts, and Gold 6132 / Gold 6136. Unlike those larger platforms, this is being tested on a FlexATX motherboard which has a 41% smaller footprint than ATX. The form factor is important in embedded applications.
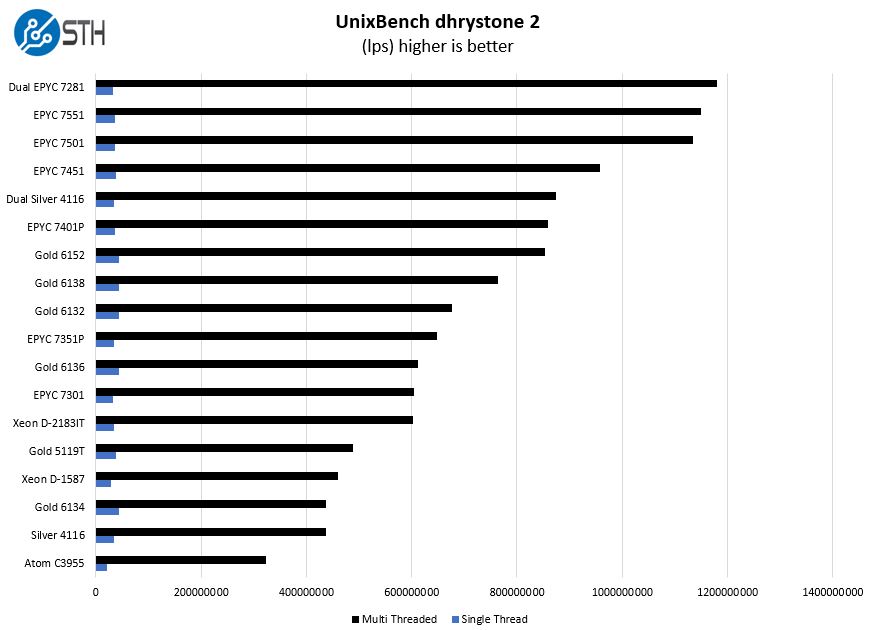
UnixBench Dhrystone 2 and Whetstone Benchmarks
Some of the longest-running tests at STH are the venerable UnixBench 5.1.3 Dhrystone 2 and Whetstone results. They are certainly aging, however, we constantly get requests for them, and many angry notes when we leave them out. UnixBench is widely used so we are including it in this data set. Here are the Dhrystone 2 results:
Here are the whetstone results:
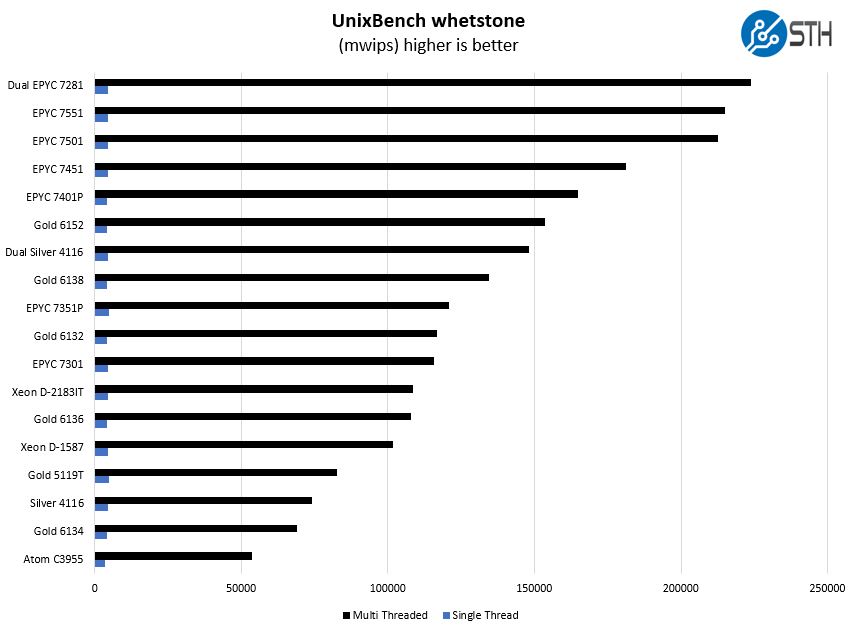
Again, we see a solid showing from the Intel Xeon D-2183IT. Next, we have the most intriguing result.
GROMACS STH Small AVX2/ AVX-512 Enabled
We have a small GROMACS molecule simulation we previewed in the first AMD EPYC 7601 Linux benchmarks piece. In Linux-Bench2 we are using a “small” test for single and dual socket capable machines. Our medium test is more appropriate for higher-end dual and quad socket machines. Our GROMACS test will use the AVX-512 and AVX2 extensions if available.
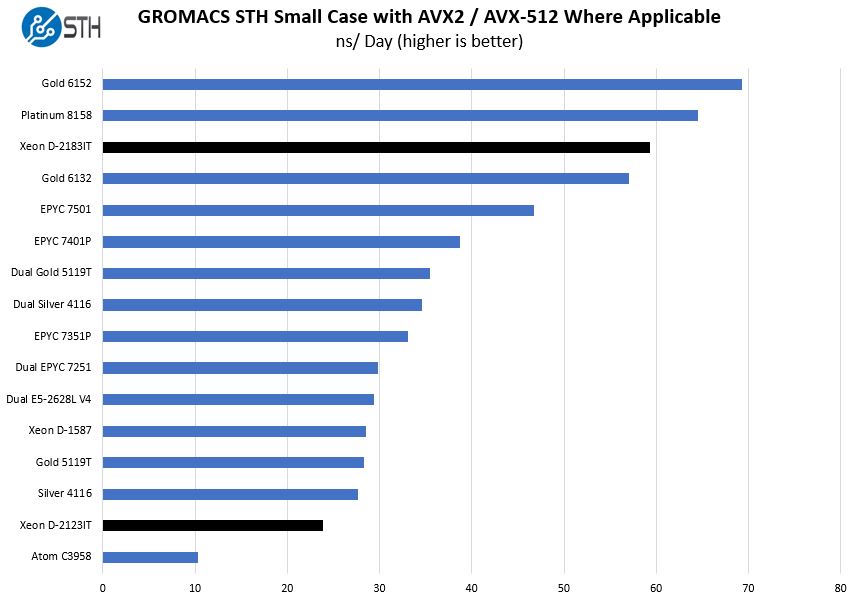
This is where things get really strange. Here we have a sub $1800 embedded chip that is only supposed to support single port FMA AVX-512 performing in the Xeon Gold 6100 range. Just to verify, here is a slide form our Intel Xeon D-2100 Architecture and Platform Overview:

That shows the same thing as Intel’s ARK spec page, Intel AVX-512 with up to 1 FMA support. That makes our GROMACS result bizarre since the Intel Xeon D-2183IT performs in-line with dual port FMA AVX-512 implementations (Gold 6100/ Platinum 8100), not single port (Gold 5100/ Silver) implementations.
To get a second data point, we added in the lowest end Intel Xeon D-2123IT part we have in the lab, based on a Gigabyte MB51-PS0. That serves two purposes. First, it will validate if we are seeing a SKU specific optimization, for example, if the high-end SKU has a different feature. Second, it lets us validate that the performance we are seeing is due to a vendor-specific option.
That 4 core/ 8 thread Intel Xeon D-2123IT beats the Intel Xeon Silver 4114 (10 core/ 20 thread, single FMA AVX-512) here. You can see that this benchmark is clearly sensitive to pick up dual port FMA AVX-512, and we have dozens of Intel Xeon Scalable and AMD EPYC single and dual socket configurations run through this exact test. We also checked the Xeon D-2100 in HPL and Linpack is showing performance per core on par with the Xeon Gold 6100 / Platinum 8100 series.
A possible explanation is that the Intel Xeon D-2100 series actually supports dual-port FMA AVX-512 not single port. At first, this may seem strange, but if you wanted to do inferencing at the edge without a GPU, perhaps that is a feature Intel snuck in.
We reached out to Intel to confirm this, and we received a response from an Intel spokesperson after conferring with the product team:
“[T]he Xeon D-2100 supports AVX-512 with 1 FMA”
On the other hand, the Intel Xeon D-2100 series AVX-512 application workload aligns much better to the dual port FMA results we have seen than the single port results that the parts list in their spec sheets.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and are ready to start sharing results:
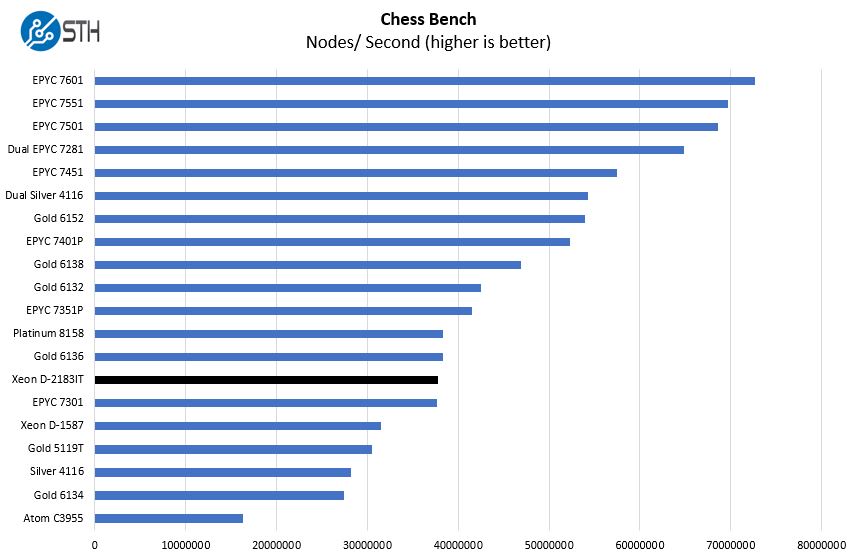
Here we have good performance, but not necessarily groundbreaking performance from the chip.
Next, we are going to have the power consumption, market positioning, and our final words.



{kind=link}
Don’t I remember reading that the dual-FMA gold/platinum SKUs drop the AVX clock-rate by half, due to power/thermal issues? Maybe these are single-FMA but maintain full AVX clocks due to fewer cores/lower clocks? Could that explain the FMA workload performance here?
Haven’t tried it myself but,
https://software.intel.com/sites/default/files/managed/9e/bc/64-ia-32-architectures-optimization-manual.pdf
15.20 SERVERS WITH A SINGLE FMA UNIT
“The following example code shows how to detect whether a system has one or two Intel AVX-512 FMA
units. It includes the following: …”
Michael – they do lower clocks, but not by enough to explain what we are seeing, especially on the Gold SKUs.
Kyle Siefring – tried to do a quick gcc compile and it failed. Will try icc later. Things that I know are using AVX-512 (e.g. Linpack) are performing much better than one would expect which is a similar idea to the two loops.
“Still, months after the AMD EPYC 3000 series launch they are still virtually impossible to find in a channel board in the market. ”
AMD, we’re waiting here guys, can’t support the underdog if the product isn’t on shelves
Interesting results re AVX512 – thanks for posting the findings!
Are you able to run a full instruction latency/throughput test?
Agner has some test scripts here: http://www.agner.org/optimize/#testp
If you’re able to run Windows, you can also try AIDA64 (which would be compatible with all the details here: http://users.atw.hu/instlatx64/ )
Also are you able to post the clock rate during AVX512?
According to the information here [ https://twitter.com/InstLatX64/status/963046768849113088 ] the Xeon-D throttles slightly less than the Scalable Xeons, but not by much.
It was initially reported that some Core-X models only had 1x 512b FMA, but this turned out incorrect, so I wouldn’t be too surprised if there’s a reporting error here too.