Intel Xeon 6780E and Xeon 6766E Performance
Full disclosure on this one. We had these servers for days, not weeks. As a result, there was no time to get the servers photographed, B-roll taken, and then shipped and installed in the data center. Many of the benchmarks take hours to run, and when the schedule is compressed to days/ hours instead of weeks, we simply cannot run everything.
As you may have seen, we are running a Cloud Native Efficient Computing is the Way in 2024 and Beyond series. As part of that, we have been focused on a problem with traditional benchmarks. These processors are not designed to do one task across an entire CPU. Instead, they are designed to run multiple VMs, multiple containers, and microservices simultaneously. Many applications run on portions of older 16, 24, and 32-core CPUs. When one has 144 cores, it is now about running fleets of applications running on several previous-generation systems on a single CPU. An easier way to think about this, single applications can be dependent on single thread portions. On a 144-core CPU, you get strange usage where one core is used, and the rest of the chip is idle for a 0.7% utilization rate. These new high-core count CPUs are designed specifically to have multiple applications running to avoid this. As such, we have been hard at work trying to tease out that usage model in our cloud-native compute series.
We noticed that 100Gbps per CPU was not enough for our application-level benchmarks. Instead, we are now using around 400Gbps of networking per CPU because that impacted our performance results by several percent when going over the network.

Thank you to NVIDIA for sending its NVIDIA BlueField-3 DPUs, which we have featured a few times and used here to provide additional network throughput. These are very high-end cards and a step up from the company’s NVIDIA ConnectX-7 in terms of features.
Intel’s Xeon 6 Performance Comparisons
Before we get too far, to get a bit more coverage, here is Intel’s comparison of gen on gen performance and power efficiency.
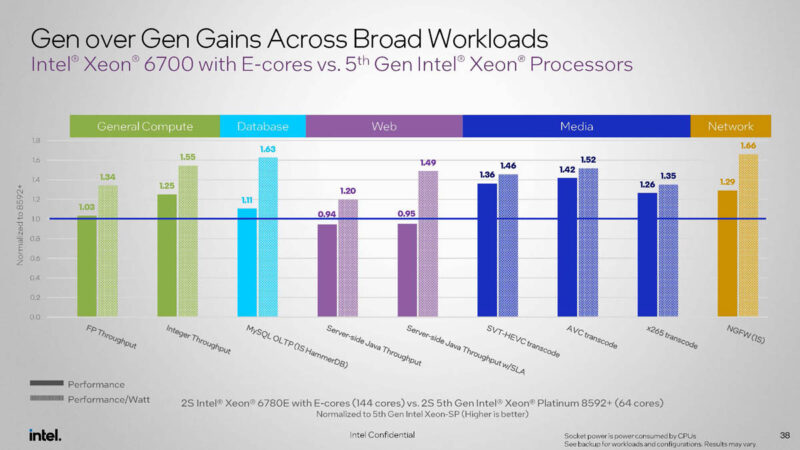
144 Xeon 6E cores are not always faster than 64 5th Gen Xeon P-cores. Put power efficiency is way better. Intel has 1.13x the threads, so when we say a Xeon 6 E-core is more like a Emerald Rapids thread, that is what we mean. Sometimes it is better. Sometimes it is worse. Just note that the comparison points are things that scale well with cores like transcoding (still a very popular CPU application) web workloads, and so forth. What is not here is things like AVX-512 NAMD and GROMACS. Those are not the target applications.
Something cool is that Intel has changed to a 2nd Gen Intel Xeon comparison as we used in our 1st and 2nd Gen Intel Xeon to the 5th Gen Intel Xeon Consolidation piece. Intel is using top-bin Intel Xeon Platinum 8280 here, but in reality that was a low-volume part. We used the Xeon Gold 6252 because Supermicro told us that was their most commonly used SKU. The implication is that the numbers are ~17% higher for the base case than we would generally see.
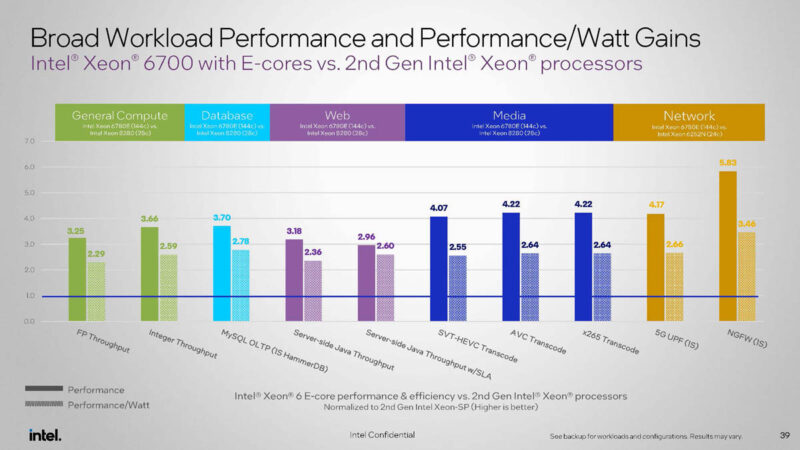
Here is a great one. To be clear, this is the midrange socket, not the big socket Sierra Forest. Instead of using a 128-core/256-thread 360W Bergamo, Intel is using a 128 E-core / 128-thread Xeon 6 to a 64 P-core 128-thread AMD EPYC. This makes a lot of sense just given that the idea here is to have as many vCPUs as possible. Intel’s efficiency would likely be better with the Xeon 6766E. This is a comparison we would not have seen from Intel years ago.
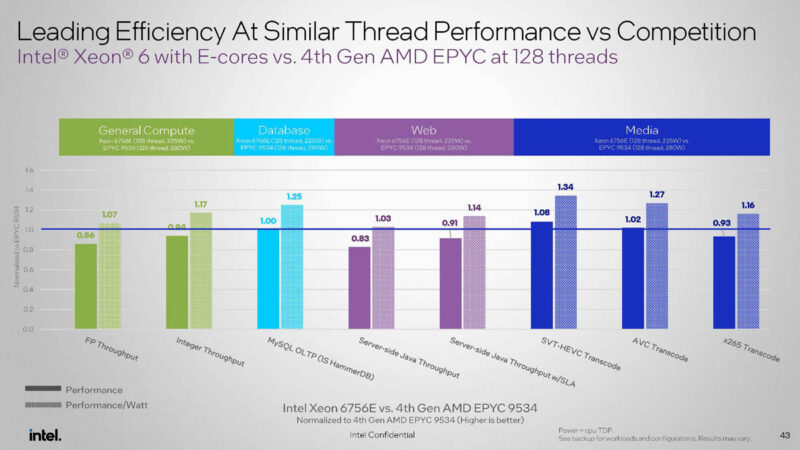
The key to these is that even when the Xeon 6E loses on performance, it notches a win on power efficiency. That is a key point. Intel is not trying to win on raw performance with Xeon 6E. It is winning on performance per watt and maximizing core counts in a server.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple: we had a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and made the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read.
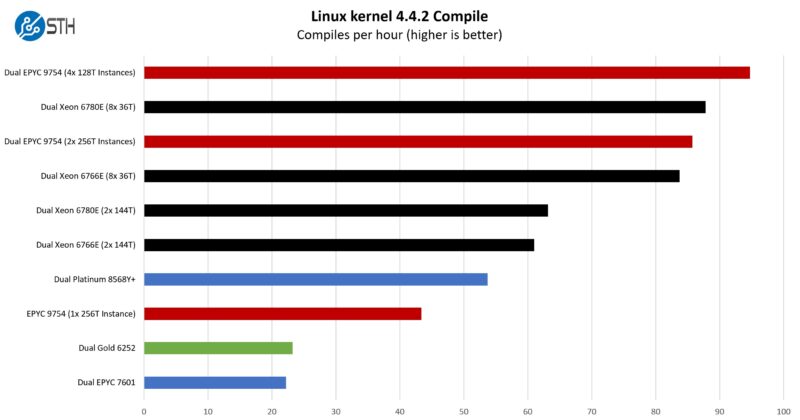
So this is really a cool result. This is one of the first tests that we started breaking up into multiple instances. The reason for that is that there are a few spots where we get the single thread points that just stall large processors, where you get sub 1% utilization. Moving to 4x 36 thread instances per CPU for 8x 36 thread instances per system, we saw a massive jump in performance.
When we discuss how benchmarking a single application on entire cloud native processors feels a bit wrong, this is a great example of why. If you are lift-and-shifting workloads from lower core count servers, then this is more like how they would run on the cloud-native processors. It is strange, but they perform better as work gets distributed and single-threaded moments do not induce sub 1% utilization.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular for showing differences in processors under multi-threaded workloads. Here are the 8K results:
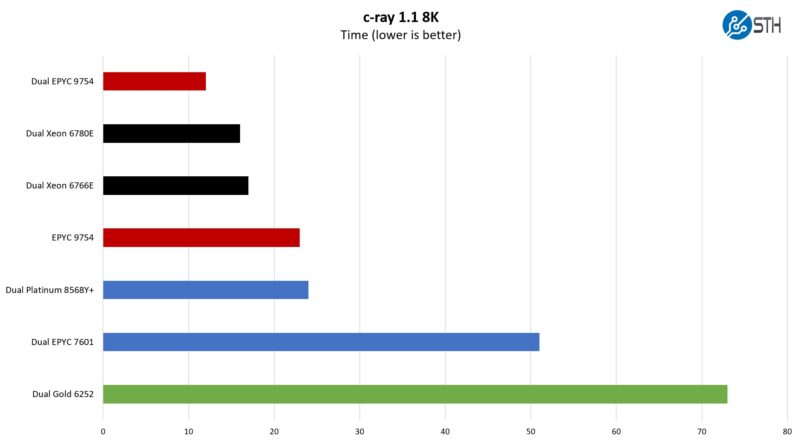
This is one where we are going to have to split it up. Scaling with these larger CPUs is starting to get wonky.
SPEC CPU2017 Results
SPEC CPU2017 is perhaps the most widely known and used benchmark in server RFPs. We do our own SPEC CPU2017 testing, and our results are usually a few percentage points lower than what OEMs submit as official results. It is a consistent ~5% just because of all of the optimization work OEMs do for these important benchmarks. Since there are official numbers at this point, it feels right to use the official numbers if we are talking about a benchmark.
Note: We lost a DIMM and are working to get a new set, which is slow right now. In the meantime, we expect/ estimate a dual Xeon 6780E system on officially submitted results will top 1300 SPEC CPU2017 Int Rate score.
STH nginx CDN Performance
On the nginx CDN test, we are using an old snapshot and access patterns from the STH website, with DRAM caching disabled, to show what the performance looks like fetching data from disks. This requires low latency nginx operation but an additional step of low-latency I/O access, which makes it interesting at a server level. Here is a quick look at the distribution:
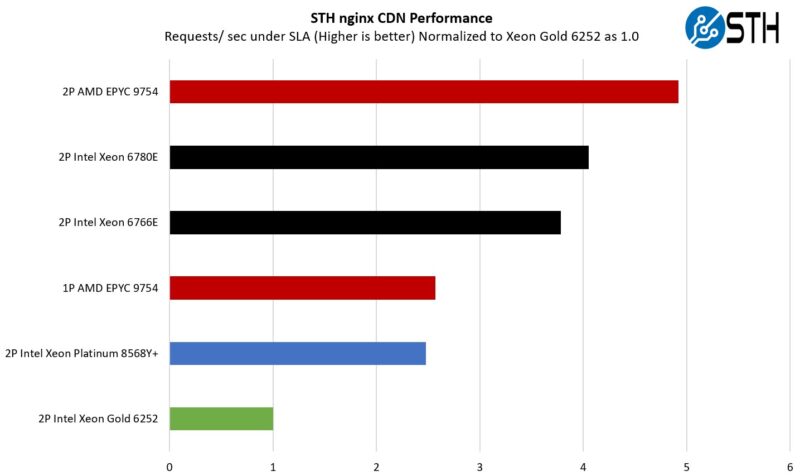
Here, we are seeing a familiar pattern. There are a few items to note, though. The Intel CPUs are doing really well. We are not, however, doing Intel QAT offload for OpenSSL and nginx. If you do not want to use acceleration, then this is a good result. If you are willing to use accelerators, then this is not ideal since there is silicon accelerators not being used. It is like not using a GPU or NPU for AI acceleration.
See Intel Xeon D-2700 Onboard QuickAssist QAT Acceleration Deep-Dive if you want to see how much performance QAT can add (albeit that would only impact a portion of this test.)
Even without QuickAssist and looking at cores only, Intel is doing really well. Imagine a 288 core part.
MariaDB Pricing Analytics
This is a very interesting one for me personally. The origin of this test is that we have a workload that runs deal management pricing analytics on a set of data that has been anonymized from a major data center OEM. The application effectively looks for pricing trends across product lines, regions, and channels to determine good deal/ bad deal guidance based on market trends to inform real-time BOM configurations. If this seems very specific, the big difference between this and something deployed at a major vendor is the data we are using. This is the kind of application that has moved to AI inference methodologies, but it is a great real-world example of something a business may run in the cloud.
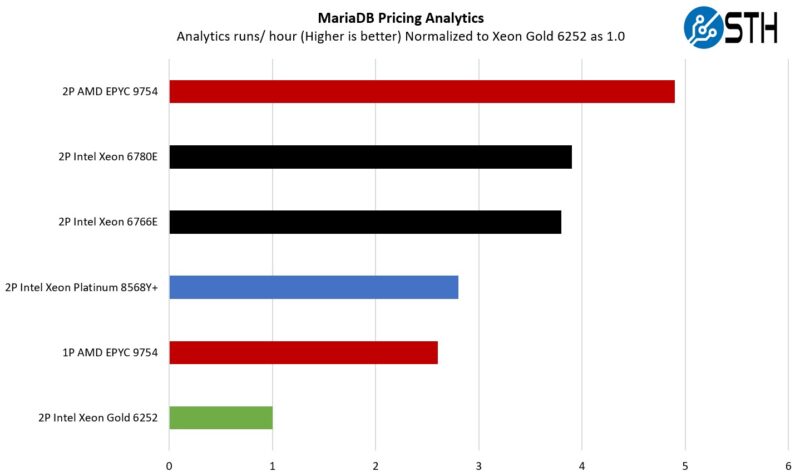
Here SMT helps, but it is a lower percentage gain per thread. AMD still has a considerable lead with Bergamo since it is winning with 256 Zen 4c cores versus 288, but the E-cores are holding their own.
STH STFB KVM Virtualization Testing
One of the other workloads we wanted to share is from one of our DemoEval customers. We have permission to publish the results, but the application itself being tested is closed source. This is a KVM virtualization-based workload where our client is testing how many VMs it can have online at a given time while completing work under the target SLA. Each VM is a self-contained worker. This is very akin to a VMware VMark in terms of what it is doing, just using KVM to be more general.
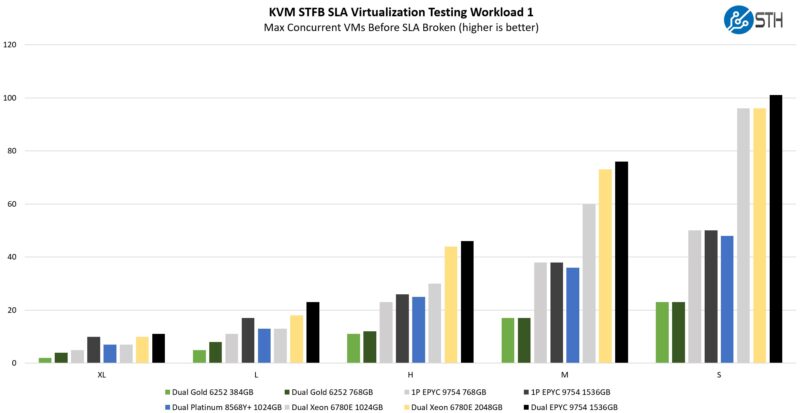
These are really great figures for Sierra Forest. Bergamo is still winning, and in some of the larger VM sizes, simply having 512 threads instead of 288 in a dual-socket server is really helping a lot here. Memory sizing does have some impact on the larger tests as well. Still, Sierra Forest is doing really well, and it is doing it at a lower power of 330W. The reason we are using the Intel Xeon 6780E here, not the Xeon 6766E, is simply that this takes too long to run, but our sense is that some of the results will be indistinguishable when they are memory and core-bound. Our guess is that would be the big winner from a performance per watt basis.
Overall, this is not AMD EPYC Bergamo-level consolidation. On the other hand, there is a big benefit over 5th Gen Intel Xeon both on a performance and power side, as well as raw performance.
Next, let us get to the power consumption, which is great.



{kind=link}
The 2S core-to-core latency image is too low-res to read unfortunately.
The discussion about needing more instances of the workload for a good kernel compile benchmark is exactly what the concepts of weak scaling vs. strong scaling in the HPC world are. It is a property is the application. If when using N cores, the calculation finishes in 1/Nth the time of a single threaded instance, it is said to have a strong scaling property. If when using N cores, the problem size is also N times bigger and the calculation finishes in the same time as the reference problem on 1 core, it is said to have a weak scaling property. In both cases perfect scaling means that using N cores is N times faster, but for weak scaling that only holds if you also increase the problem size.
I am curious about the PCH. If the PCH goes away will the SATA controller also move into the CPU or will the motherboard manufacturers have to add a SATA controller, or is SATA simply dead?
I see on the diagram the network cards, the M.2 and the other PCIe lanes, but I don’t see the SATA controller that usually lived in the PCH.
Or maybe there will be a simpler PCH?
I hope you’d do more of that linux kernel compile benchmark partitioning. That’s what’s needed for chips like these. If you’re consolidating from old servers to new big CC CPUs you don’t need an app on all cores. You need to take an 8 vCPU VM on old and run it on new. My critique is instead of 36 vCPU I’d want to see 8 vCPU
“Ask a cloud provider, and they will tell you that 8 vCPUs and smaller VMs make up the majority of the VMs that their customers deploy.”
As someone who runs a small cloud hosting data center I can confirm this. We have 9 out of 150VMs that have more than 8 vCPUs. Of those 9 I can tell you that they could easily be cut in half and not affect performance of the VMs at all. However, the customers wanted and are paying for the extra vCPUs so they get them.
OK, auto-refresh of page wiped my comment … a ahem great way to prevent any bigger posts. So will keep the rant and skip analytical part of the comment I wanted to post for others ..
——–
The conclusion is, well, Intel-sponsored I guess.
On one hand you give one to Intel, stating Sierra Forest is really positioned a step below Bergamo – which is correct.
Then, one paragraph later, you criticise Siena for the same fact – that it is positioned (even more so) below Sierra Forrest.
A lost opportunity.
For the Bergamo comparison -“but again, remember, a large double-digit percentage of all infrastructure is determined by the ability to place a number of VMs and their vCPUs onto hardware. 256 threads is more than 144, but without SMT that becomes a 128 v. 144 discussion.” That is such a contrived conclusion. I doubt how many service providers actually think like this/
Divyjot I work at a big cloud provider so my thoughts are my own. You might notice all the cloud providers aren’t bringing SMT to their custom silicon designs. SMT with the side channel attacks is a nightmare. You don’t see scheduling across different physical cores in large public clouds for this reason.
That conclusion that Bergamo’s Zen 4c is too much perf per core is also on target.
I’d say they did a great job, but I’d also say the 288 core is going to be a step up. I’d rather have 288 physical cores than 384 threads using SMT.
AMD needs a 256 core Turin Dense. What they’ve missed is that Intel offers more than twice the E cores than the P. We’re buying Genoa not Bergamo top end even with STH saying Bergamo is great because we didn’t want to hit that low cache case in our infrastructure. 96 to 128 is only 33% more. You’re needing to show a bigger jump in core counts. 128 to 192 is only 50% more. AMD needs 256.
I think this is just an appetizer for Clearwater Forest next year with Darkmont cores on Intel 18A. That would be a serious product for most workloads except ones requiring AVX512.
Oh wow, a truly rare unicorn here, a Patrick/STH article right out of the funny pages, which is great, everybody likes to laugh once in a while!
Hurray, cloud providers are getting more efficient. Meanwhile, I’m not seeing the costs for these low end minimalist servers going down. It’s impressive how many more cores and how much more RAM and how many more gigabits of networking you can buy per $ only for the price from year to year to stay the same…
It would be great if your benchmark suite reflected some more use cases to reflect the weird CPUs, especially for the embedded parts.
Things like QAT for nginx or an opensense router or Tailscale exit node or SMB server. I know they aren’t traditional compute tasks but they do need CPUs and it’s what most STH readers probably actually use the devices for.
@Patrick: Please stop with this ridiculous pro-Intel framing
You say that Bergamo is “above” Sierra Forest but they basically have the same list prices. The 9754S with 1T per core is even cheaper and I would have loved to see a comparison of that 1T1C for both AMD and Intel.
“What Intel has here is something like a Siena”: No, you really need to change your conclusion after Intel published their price list.
BTW
Bergamo 9754 is going for 5400 Euros (including 19% VAT) at regular retailers in Europe and 9734 for 3600 Euro. I really don’t think Bergamo will be “above” Sierra Forest even at “real world” prices for larger customers.
Forget AMD. I think this article is sponsored by Ampere or Arm. Ampere or Arm must have paid to not have its chips in these charts. Intel’s 1G E Core Xeon is more than 30% faster per core than the Altra Max M128 even with more cores in the same power. You’re also not being fair since Sierra’s using DDR5 so that’s gap for memory. PCIe Generation 5 is higher power and faster. So Intel’s 250W is being used some for that. 144 cores at 250W is amazing. We’ve got so much older gear and even still low utilization so BOTE math makes this a big winner. We’ve got renewal at the colo coming. I can’t wait to watch how they’ll take reducing 40 cabs to 4.
I think AMD’s faster on AVX512 but web servers will get much more benefit from QAT than they do AVX512. I don’t think that’s being taken into account enough. You’re handicapping Intel versus AMD by not using that.
If you do the math on the 9754S loss of threads that’s about 14% below the 9754. Intel’s got integer performance 25% above the 8594+ so you’d end up at 19% lower perf for the 6780E than the 9754S, not taking into account QAT which you should but it won’t work for integer workloads.
With that 19% lower performance you’ve got 12.5% more cores on Intel, so that’ll have a larger impact on how many vCPUs you can provision. You’re at a lower perf per core with Intel, but more vCPU capacity.
When we look at power though, that 6780E screenshot is 302W so it’s 58W less than the 360W TDP 9754S since AMD typically uses its entire TDP. That’s just over 16% less power. I’d assume that extra 28W is for accelerators and other chip parts.
So Intel’s 19% less perf than Bergamo without SMT at 16% less power. Yet Intel’s delivering 12.5% more vCPUs and that QAT if you’re enabling it for OpenSSL offload or IPsec will more than outweigh the 3% perf/power difference. I don’t think QAT’s as important on super computer chips, but in this market, it’s aimed directly in target workloads.
If you’re just going vCPU / power and don’t care about 20% performance, then the 6766E is the clear winner in all of this. We’ve got over 70,000 VM’s where I work and I can tell you that we are 97% 8 vCPU and fewer. Less than 15% of those VMs have hit 100% CPU in the last quarter.
What this article fails to cover is the 1 vCPU VM. If you’re a poor cloud provider like a tier 5 one maybe you’re putting two different VMs on a SMT core’s 2 threads. For any serious tier 1 or tier 2 cloud provider, and any respectable enterprise cloud, they aren’t putting 2 different VMs on the same physical core’s 2 threads.
I’d say this is a great article and very fair. I don’t think SF is beating AMD in perf. It’s targeting what we’ve all been seeing in the industry where there’s so many small VMs that aren’t using entire vCPU performance. It’s the GPU moment for Linux virtualization.
@ModelAirplanesInSeattleGuy
“more vCPUs”: Don’t know where you’re working but no company I’ve been at cares about just more VMs. It’s about cost(including power) and performance. We never consolidate to a server where the VMs don’t offer significant performance upgrades. It’s about future proofing.
“since AMD typically uses its entire TDP” : Like all CPUs it depends on the workload. Your calculation is worthless
Regarding QAT: What is the performance of these 2 QAT (at least Xeon 4th/5th gen platinum has 4 units) units when you use 144 VMs(like your example, or just 32) accessing QAT through SR-IOV? The fact that it’s hard to find any information on it shows that very few are using QAT despite all this talk. Anyone looking for such an extreme use case would use DPUs.
xeon 6 is new socket or it can be used in Sapphire rappids motherboards?
Xeon 6 processor is based on a new socket and is not compatible with the Sapphire Rapids motherboard/socket.
I wonder if it wouldn’t have made more sense to pursue higher dimension p-cores, instead of the me-too e-cores
Imagine a 32x P-core with 4 or 8 HTs each.