
At SC23, Intel had a number of announcements, but it also took a different approach. Instead of having its performance team show off the performance of its new hardware, it let Argonne National Lab show off performance data using the systems it has access to as a major US supercomputing center.
Intel Shows GPU Max 1550 Performance at SC23
Last year we were shown the OAM modules for the Intel Data Center GPU Max Series OAM modules that are the GPU Max 1550 series now.

This year, with Aurora installed, Argonne has performance numbers on portions of its new supercomputer. One way it is showing that is with its performance of the Max 1550 versus the AMD MI250 and the NVIDIA A100 that it has in other platforms.
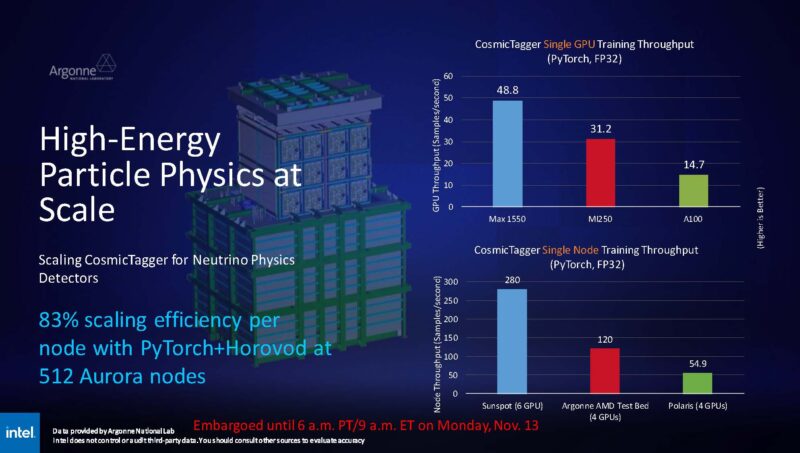
It was a bit of a bummer that we did not get to see H100 numbers here, but with FP64 performance NVIDIA does not get the same generational scaling it can show on the AI side by dropping from FP16 for the A100 to the FP8 Transformer Engine on the H100 (and L40S). As a result, this is a better comparison than using the A100 on the AI side.

Aurora is built, but still being tuned so we are not going to get a full system Top500 submission to crack the #1 spot. Still, that has freed up the capacity to sell the GPUs to other parties and through OAM modules.

We saw a number of these during our Touring the Intel AI Playground: Inside the Intel Developer Cloud piece. We are even using one of the Max 1100 series Sueprmicro systems from the IDC tour as the YouTube cover image.
Still, a big focus is on AI with Gaudi.
Intel Gaudi2, Gaudi3, and Falcon Shores at SC23
Intel just had a big win with Gaudi2 with NVIDIA’s marketing slide showing Intel Gaudi2 is 4x better performance per dollar than its H100. We are not going to cover that again, but here is another test from MLPerf Inference. On GPT-J-6B inference it is in the same ballpark as the current NVIDIA H100 generation with both the Gaudi2 and the Max 1550 series is a step beyond the A100.
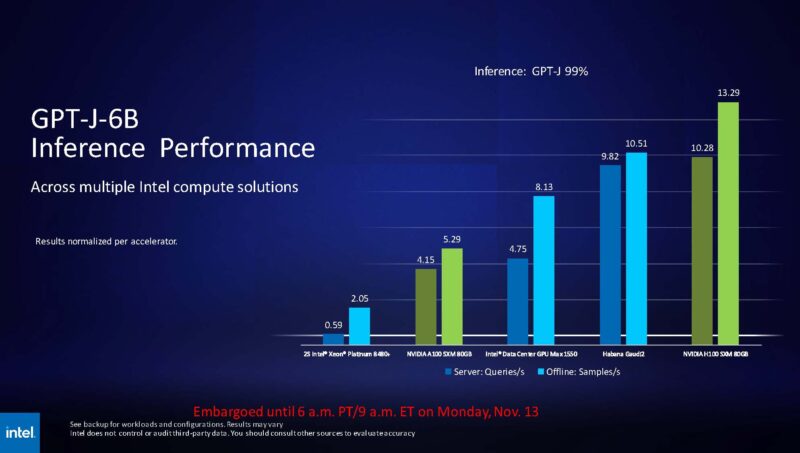
Intel showed off the 96GB HBM2E Gaudi2 architecutre.

Today, NVIDIA H200 with 141GB of HBM3e was launched at SC23. What should be interesting for folks is that Intel will have its own 144GB part in 2024 with Gaudi3. Update 2024-11-15: There was a mistake on the original slide that said 1.5x HBM Capacity. That is now “BW” or Bandwidth. 144GB (96GB x 1.5x) seemed strange in the eight HBM packages shown. Our best guess is that Gaudi3 might be targeting 8x 16GB stacks for 128GB, but it would be exciting if we were incorrect on that.
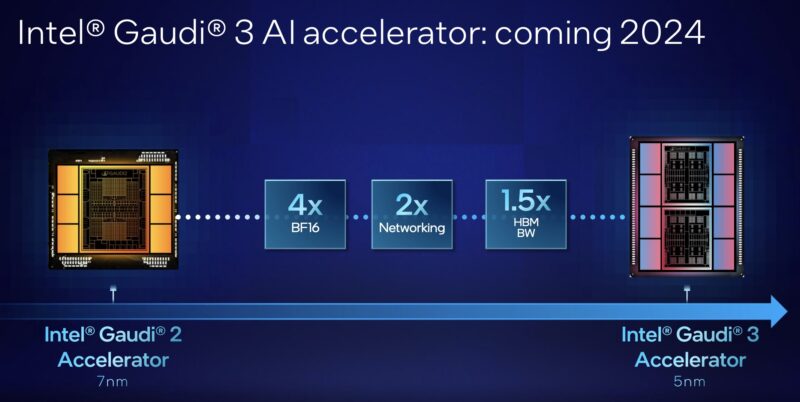
That could make things really interesting on the AI side. What should give us pause is the Gaudi3 diagram above. It has eight HBM stacks in that photo so getting 1.5x HBM capacity with 1.33x as many HBM stacks puts us into an interesting capacity point. The networking side is important since unlike NVIDIA solutions where one generally uses Infiniband, Gaudi’s approach from the outset was to run over Ethernet and integrate that in the accelerator.

Something that seems a bit odd in the announcement is that Falcon Shores, the unification of the GPU and AI lines of today, is still HBM3, not HBM3e. It is still some time off in ~2025 so perhaps that will change, but NVIDIA should be past the first-gen HBM3e equipped H200 at that point and AMD is not sitting still. Update 2024-11-15: There was a mistake on the original slide that said HBM3. Intel updated the slide to say HBM3e.
Final Words
Overall, it is a bummer that Aurora is not going to take the #1 spot on the Top500 this week, but it is great to see Intel get more competitive on the accelerator side.
Intel also trumpeted the benefits of the Data Center MAX CPU series, but we already did an Intel Xeon MAX 9480 Deep-Dive with 64GB HBM2e onboard.



{kind=link}