
When the news of the Intel L1TF security vulnerability hit, STH covered it in Foreshadow Flaw Targets Intel SGX and Virtual Machines. Foreshadow utilized a level 1 cache terminal fault (hence L1TF) as a side channel vector attack. There were a few major implications of Foreshadow. One is that an attacker could get information out of Intel’s SGX secure enclave. A second is that since the L1 cache is shared among hyper-threaded cores. If untrusted virtual machines are run on different hyper-threaded cores, then data can leak from one virtual machine to another. Intel has put out performance data on the impact of this on some industry standard benchmarks.
For those still looking for answers on L1TF, see our earlier piece or this video from Intel.
Intel L1TF Foreshadow Performance Impact Data
Most teams we speak to say that bare metal mitigations are a relatively low-performance impact. Intel’s data generally shows no more than a 1% performance impact if any at all. What was more interesting was what happens when you cannot mitigate simply through bare metal patches. In cases such as cloud providers, VPS providers, and enterprise clouds, one can have two VMs running on the same hyper-threaded core. Both Microsoft and Google said their cloud schedulers do not schedule VMs across hyper-threads on the same core. For small VPS providers, this is still common practice. The mitigation in those cases is turning off hyper-threading.
Intel published some startling numbers, in-line with our expectations, about the impacts of turning hyper-threading off.
As some context, we would not expect SPECfp2017, STREAM Triad, and Linpack to not be impacted by turning hyper-threading off. When vendors ask us to run Linpack, we are often asked to disable SMT.
For those Hyper-V shops, here are the Microsoft numbers.
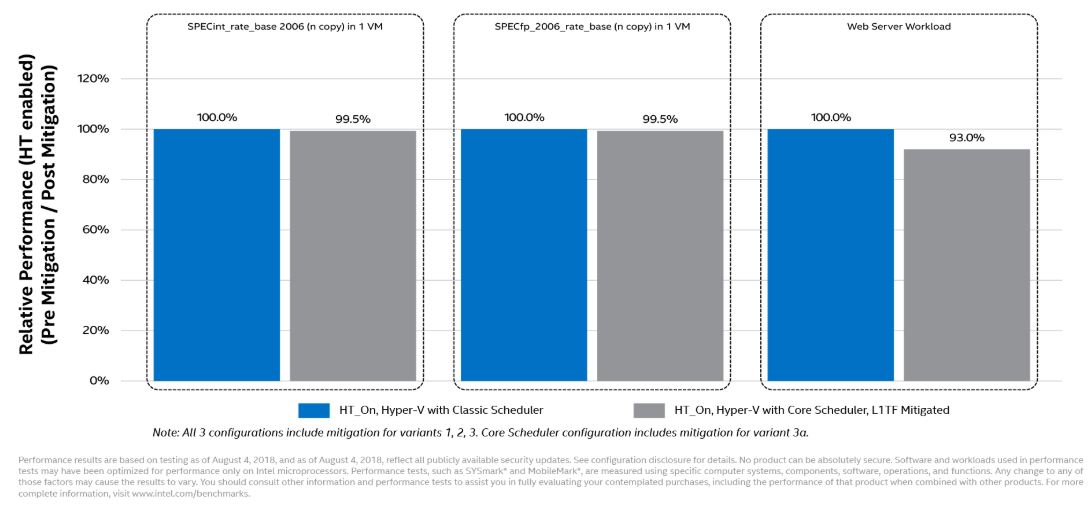
Overall a low impact, but the Web Server workload is starting to get to one server per rack level of impact.
For those who want to cross-reference, here were the numbers when Intel offered Enterprise Meltdown and Spectre Fix benchmarks.
The Other Cost
We covered RedHat’s response to L1TF. At Hot Chips 30, Jon Masters on stage said that L1TF has already cost RedHat over 10,000 hours of engineering time.

That is an enormous industry cost. Meltdown and Spectre variants have already used over 10,000 hours of engineering time according to the talk.

Final Words
For companies like Google and Microsoft with the ability to get custom chips, and with custom schedulers that can ensure that VMs to not cross hyper-threading boundaries, this is something that can be relatively easily mitigated. For enterprise virtualization clouds, this may increase utilization of underutilized servers, and cause more server purchases in the future.
The more interesting impact is the average VPS provider. Very few users are running Linpack like workloads on VPS providers. For the average VPS provider without access to custom hardware and software, mitigation will mean turning off hyper-threading. These companies often run at a lower margin where seeing a 10-30% performance impact will kill their economic model. That means they will have to choose between turning off hyper-threading and mitigating L1TF / Foreshadow and keeping hyper-threading on to preserve their economic model. That is a dangerous wire to walk.



{kind=link}
I wasn’t expecting the VPS call-out here. Your right. We have a 16% GM and our performance data says turning HT off means too many more servers to stay above our 10% minimum for viability. We cannot turn HT off
It’s a good thing we now have an alternative with AMD EPYC. No meltdown or foreshadow impact and the more cores should actually increase GM per server. Seems like a no brainer for new server refreshes. What am i missing here?
After this disclosure we’re looking at selling VPS VMs mapped to EPYC die. It gets rid of the hyperthread issues. Less vulnerability. Lower costs. We we’ve been an Intel shop for a decade but we now need to change.
The critical and even more serious problem is how many “not following the specs” still in the “Bug Inside” chips! As of now, people have been peeling the onions, and keep going and going …
Not scheduling other VMs on the same hSMT sibling is only solving halve the problem, since you also don’t want unrelated kernel threads to be scheduled without a cache flush (Meltdown mitigation is likely not enough). There is some work in the kernel currently going on in using Spectre Mitigation to Flush sensitive data before context switches [1]. This seems to have bene a feature of Hyper-V for a longer time.
Of course, due to the selective disclosure smaller companies are once again left holding the bag when it comes to mitigating these types of attacks.
I however wonder how the burstable Instance Types (t2.*) at Amazon prevent those scheduling conflicts without darmatically changing the cost effectiveness.
[1] https://lwn.net/ml/kernel-hardening/20180815235355.14908-4-casey.schaufler@intel.com/
Intel is becoming a doomed sad company
There is a new license term applied to the new microcode: “You will not, and will not allow any third party to (i) use, copy, distribute, sell or offer to sell the Software or associated documentation; (ii) modify, adapt, enhance, disassemble, decompile, reverse engineer, change or create derivative works from the Software except and only to the extent as specifically required by mandatory applicable laws or any applicable third party license terms accompanying the Software; (iii) use or make the Software available for the use or benefit of third parties; or (iv) use the Software on Your products other than those that include the Intel hardware product(s), platform(s), or software identified in the Software; or (v) publish or provide any Software benchmark or comparison test results.”
@Misha
Didn’t take them long to walk it back, luckily, but this is a strong reminder of their idiotic PR reaction to Meltdown.