
This week Intel released their initial Meltdown and Spectre performance impacts. The ranges were essentially 0-25% in what is a complete gift to AMD. Unlike years past, Intel has a real competitor in the market with AMD EPYC which has more cores, more RAM capacity and more PCIe lanes in 1P and 2P configurations. Meltdown and Spectre are the hot topics of January 2018 and Intel has been providing updates on how the design flaw that led to the vulnerability impacts performance.
Now that Intel has initial performance results, we are going to sanity check them against Red Hat’s numbers and then explain why this is important for AMD EPYC.
Intel’s Initial Response to Meltdown and Spectre Design Flaw Performance Impacts
Before we get into this too deeply, we wanted to say that we are happy that Intel is showing that in most cases performance is going down with the patches. The first step in the process is acknowledging the slower performance. Here are Intel’s results:
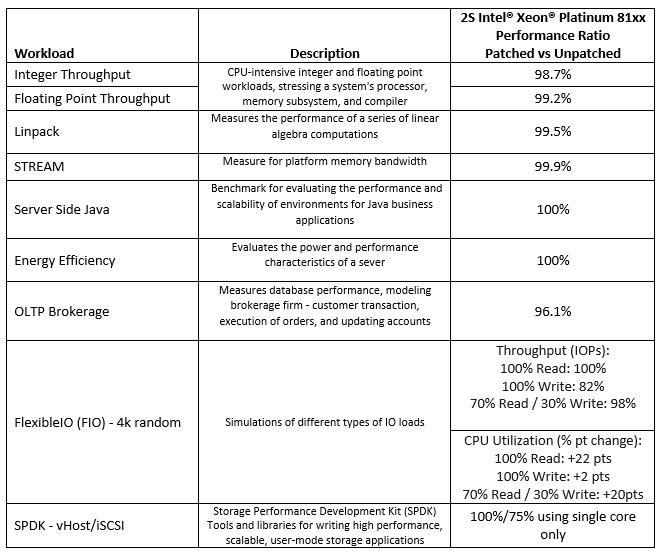
Here is the source document with all of the testing specs.
Validating Intel’s Numbers With Red Hat’s Numbers
Our readers will notice that this somewhat jives which what Red Hat suggested it saw with the design flaw patches:
- Measurable: 8-19% – Highly cached random memory, with buffered I/O, OLTP database workloads, and benchmarks with high kernel-to-user space transitions are impacted between 8-19%. Examples include OLTP Workloads (tpc), sysbench, pgbench, netperf (< 256 byte), and fio (random I/O to NvME).
- Modest: 3-7% – Database analytics, Decision Support System (DSS), and Java VMs are impacted less than the “Measurable” category. These applications may have significant sequential disk or network traffic, but kernel/device drivers are able to aggregate requests to moderate level of kernel-to-user transitions. Examples include SPECjbb2005, Queries/Hour and overall analytic timing (sec).
- Small: 2-5% – HPC (High Performance Computing) CPU-intensive workloads are affected the least with only 2-5% performance impact because jobs run mostly in user space and are scheduled using cpu-pinning or numa-control. Examples include Linpack NxN on x86 and SPECcpu2006.
- Minimal: Linux accelerator technologies that generally bypass the kernel in favor of user direct access are the least affected, with less than 2% overhead measured. Examples tested include DPDK (VsPERF at 64 byte) and OpenOnload (STAC-N). Userspace accesses to VDSO like get-time-of-day are not impacted. We expect similar minimal impact for other offloads.
- NOTE: Because microbenchmarks like netperf/uperf, iozone, and fio are designed to stress a specific hardware component or operation, their results are not generally representative of customer workload. Some microbenchmarks have shown a larger performance impact, related to the specific area they stress.
At the top of Intel’s table are Integer, Floating Point, Linpak and STREAM results which showed essentially a 0-1.3% impact. Red Hat put these into the category of “Small” impact with 2%-5% impact.
The Server Side Java workload is a SPECjbb2005 workload. Red Hat has this in the “Modest” 3-7% impact category so we see Intel and Red Hat diverge here.
For the “Energy Efficiency” benchmark Intel uses SPECpower_ssj2008 which is a good one for Intel to use here as it shows no loss from patches. This is not a benchmark Red Hat addressed.
Intel says fio will see 0-22% impact with fio while Red Hat says 8-19%. Red Hat also mentions that fio “results are not generally representative of customer workload.” This is a big deal for storage customers and the entire hyper-converged industry.
With that sanity check out of the way, let us look for a second at what Intel previously presented in terms of Skylake-SP performance.
Intel Xeon Scalable v. AMD EPYC
When we turn our attention to the Intel Xeon Scalable v. AMD EPYC numbers Intel published late last year, we see why this is a gift to AMD. Here is our full discussion of the benchmarks. First, we wanted to pull Intel’s third-party workloads:
When we look at SPECrate2017_fp_base, AMD was already ahead on this benchmark by a narrow margin. Adding a 0.8% performance decrease will slightly increase AMD EPYC leadership here. Likewise, on the SPECrate2017_int_base number, Intel will lose ground to AMD EPYC as it will see a 1.3% decrease in performance.
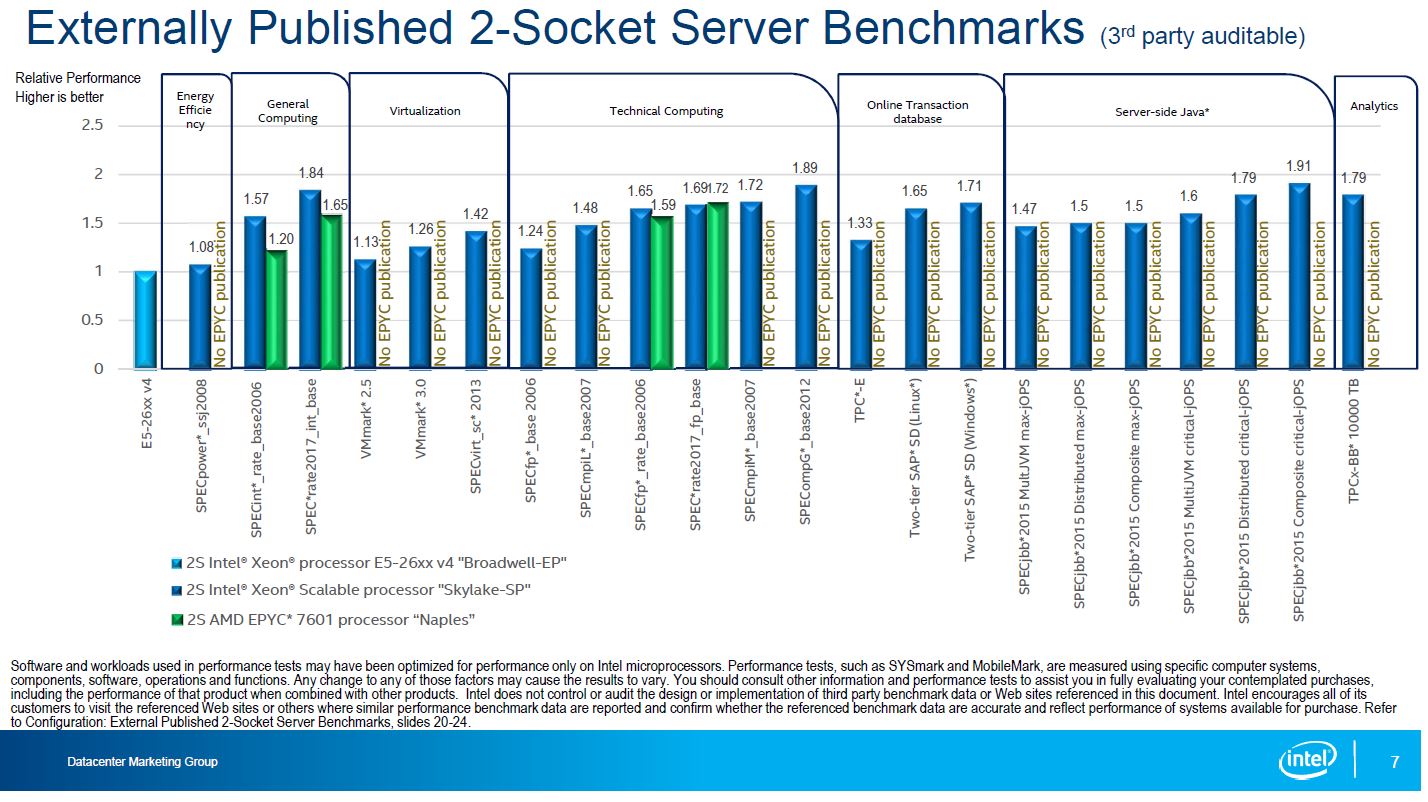
From that we are going to pull Intel’s summary chart of enterprise workloads from Intel’s internal testing:

The light blue bar shows the Intel Xeon Platinum 8160 compared to the AMD EPYC 7601 in dual socket configurations. They are in the same ballpark price wise. Note here that the Intel Xeon Platinum 8160 was exactly 1.00 in the Server Side Java benchmark. Conveniently, this is also an area where Intel claims no Meltdown or Spectre impact. Here is what is interesting, Red Hat says a modest 3-7% impact in this type of workload. If you use Intel’s estimate, it is still on part with AMD EPYC. If you use Red Hat’s number, then AMD EPYC is now ahead.
Intel suggests that the OLTP workload is about 4% lower performance. OLTP workloads tend to be the ones we are seeing, and Red Hat sees as a high-impact area. Still, if the Intel Xeon Platinum was 27% faster pre-patch, we would expect it to be no faster than 22% faster now.
The one we really want to see the results of is the “Storage bound workload” for the NoSQL database. Intel claimed a 27% lead over AMD EPYC but it is showing that some storage bound workloads using fio can see a 22% decrease. If Intel had a 22% decrease there, it would actually push Intel below AMD EPYC on that benchmark. Unfortunately, Intel did not release this result.
Final Words
The real takeaway here is that in Intel’s first set of performance impact numbers, it focused heavily on workloads that Meltdown and Spectre patches are not as meaningful. We want to see the Intel v. AMD EPYC chart again updated with Meltdown and Spectre patches. Until Intel produces this, it is open season for EPYC. We understand why Intel has not done this. Proper benchmarking takes weeks and the software and tuning sides are still being worked out. That is to be expected with impacts of this magnitude so we think it is prudent for Intel to hold off on publishing too many numbers. With that said, this is a game changer in the market.
Essentially all of the numbers produced for Intel v. AMD are going to be reset and that is great for AMD. AMD has a strong I/O story and it can now point to Intel’s numbers as another reference point as to why it has a better platform. It now has more PCIe lanes, more RAM capacity and more cores that Intel cannot point to as easily and say “our cores are faster” and dismiss.
As the performance impact evidence piles up, this is an absolute gift to AMD.
Feel free to share your perspective on the STH forums.



{kind=link}
One important note: AMD is not vulnerable to Meltdown, but is vulnerable to at least type 2 of spectre IIRC. So comparing intel patched for all (if ever possible!) and unpached AMD is not entirely fair.
Personally I’m very glad where AMD is now, but feel a need for correctness… Anyway, the big question mark is if we’re ever able to patch against whole Spectre…
I expect the I/O intensive workload slowdowns are almost entirely due to KPTI (meltdown). Type 2 Spectre fixes get around indirect branch predictors and this will show in compute-intensive workloads like SPEC. (The impact of indirect branch prediction on I/O intensive workloads will be negligible because it’s dominated by I/O). I think it’s pretty clear that the highest slowdown for intel is for I/O bound workloads, something AMD says it is not affected by, because it doesn’t allow speculative accesses that require higher privileges to succeed.
Yeah but 24/28 cores compared to 32 and Intel still kicks its ass.
If we were to compare 32 cores vs 32 cores, the story would be even better for Intel.
According to the Intel CPU design, the White House (Kernel) need to relocated for the security issue (Meltdown)!
According to Intel CEO, relocating the White House is the intended design (with no privilege level checking)!
So far, Intel isn’t liable for INTENTIONALLY selling the faulty (not checking and not correctly handling the privilege level) CPU chips designed basing on the specifications with the INTENDED flaw of the privilege level handling, unbelievable and amazing!!!
Wonder how much compute power is left, after intel closed all the known bugs and loop-holes, Linus Torvals is pretty critical.
The other ‘good and bad’ for AMD is that they are likely delaying Epyc 7 nm (Zen 2) until 2H of 2018 to ensure top performance while avoiding these 2 issues and anything similar they can foresee.
The (forgivable) bad is that it delays the hoped for (at least by me) release in the next few months.
At least once they are out it’s expected that they will work (nearly) perfectly without errata and patches.
Good for them going forward, bad for CPUs released last month where a short delay would have left them a chance to patch on tape.
A big mess but there was talk over a year ago by ‘other countries’ developing their own CPUs to avoid any ‘hidden problems’ from affecting them – like a backdoor during war – so no surprise here.
AMD is not delaying 7nm. The foundry (GloFo) just isn’t ready yet. Same goes for TSMC and Intel (@10nm).
AMD was never affected by Meltdown and Spectre vulnerability is patchable without a performance hit. So delaying a product for these two (especially when they have been known for 6months now) is not a correct conclusion IMO.
At this point if EPYC is lower cost and comes with secure memory encryption and more PCIE lanes its a no-brainer unless the customer is an Intel biggot
I think Intel is purposely delaying the correct patches because the performance degradation is even more than they are in the initial patches. Because 99% of data centers use Intel the rest of the big players can’t criticize or complain because it would likely affect their own stock prices but this is going to be a very interesting 2018.