
Intel Knights Mill is the company’s offering for deep learning. CPU design takes many years. By the time Intel Knights Landing (see STH’s hands-on piece here) was being deployed, the HPC market moved towards supporting deep learning applications. In Q4 2017, we will see Intel Knights Mill which builds on Knights Landing and is specifically targeting deep learning applications. Interestingly enough, Intel is pushing Integer for deep learning with this release.
Intel Portfolio for Deep Learning
Before we get too far covering this story, Intel also made two acquisitions. Altera and Nervana. Altera brings leading FPGA technology for Intel to market FPGAs to deep learning shops. FPGAs Intel is targeting at the inferencing market given their programmability and low latency. The upcoming Nervana CPUs will likely be around in time to displace Intel Knights Hill for deep learning training.
About Intel Xeon Phi Knights Mill
Let us get down to some figures. Here is the new architecture overview:
One takeaway is the 384GB limit. That is twice what Knights Landing could support. Intel is also using DDR4-2400 instead of the newer DDR4-2666. On the other hand, there is the same 16GB MCDRAM that we saw on the previous generation KNL part.
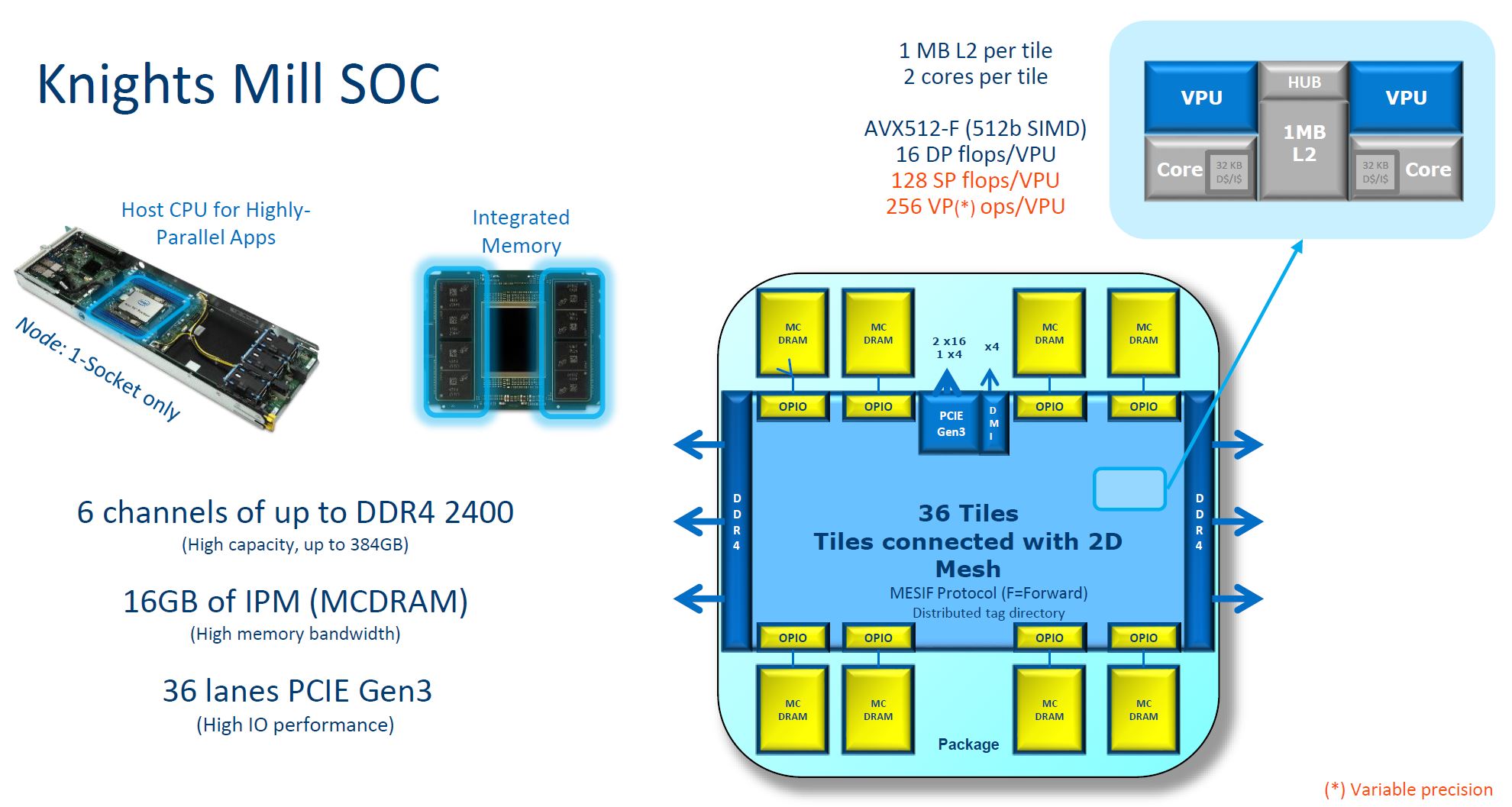
There are a total of 36 tiles connected using a 2D mesh architecture, similar to what Intel Xeon Scalable uses.
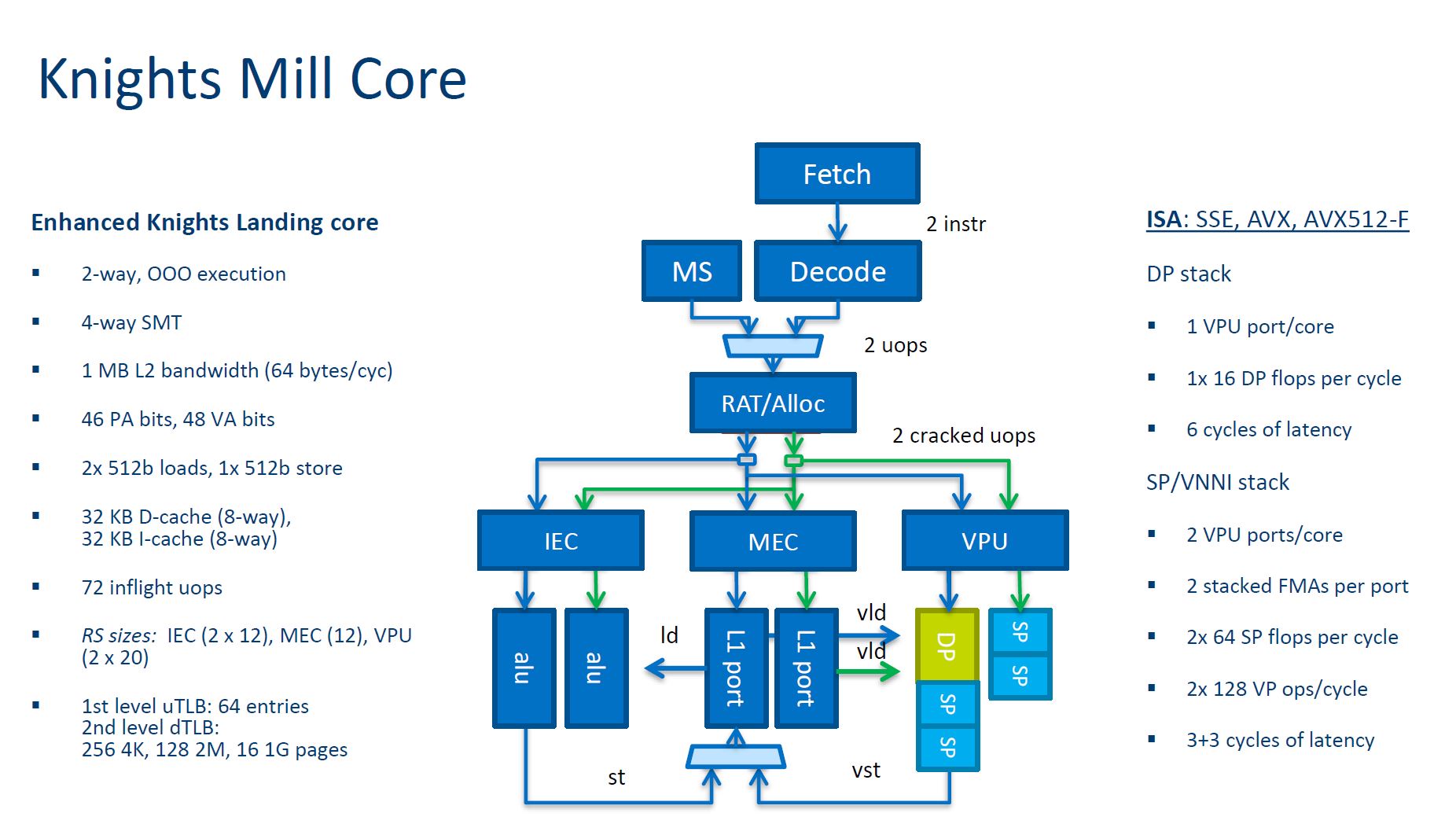
The core continues to be 4-way SMT whereas the standard Xeon CPUs are 2-way SMT (Hyper-Threading.) Here are the core details.
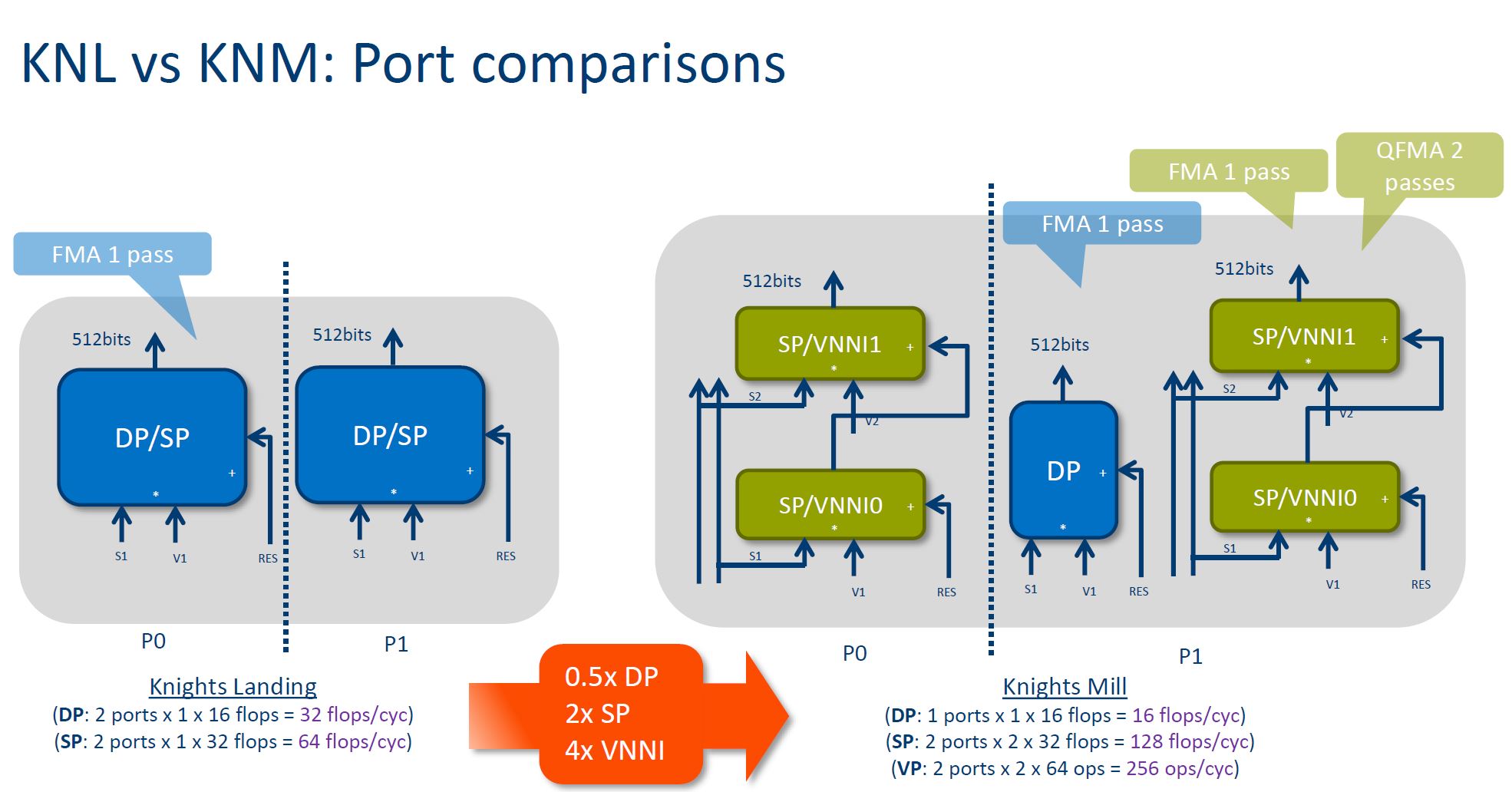
Knights Mill is based largely on Knights Landing, with some changes specifically to address scale-out deep learning training. Here is the FMA port difference for example:
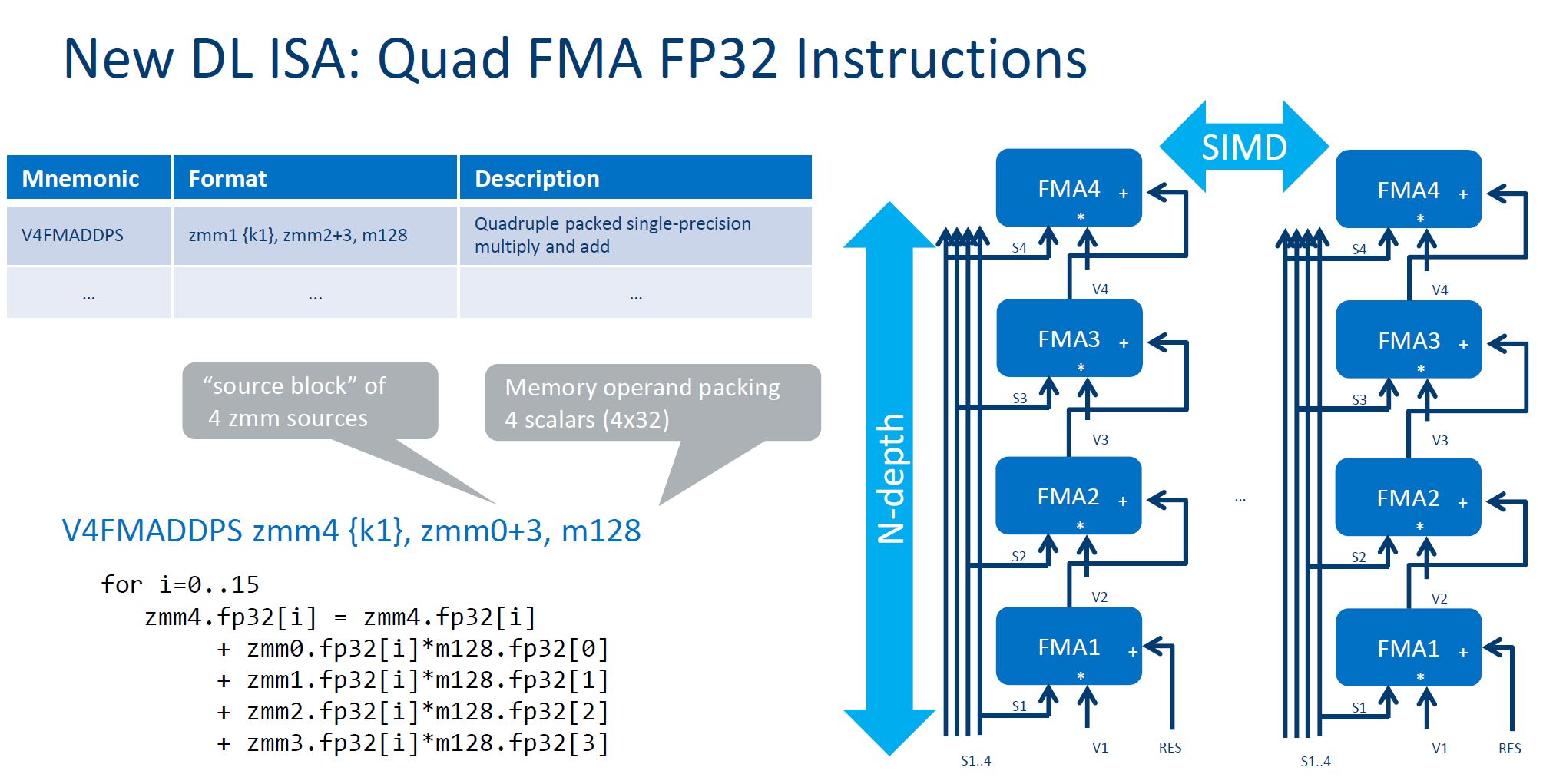
Here is the benefit slide:
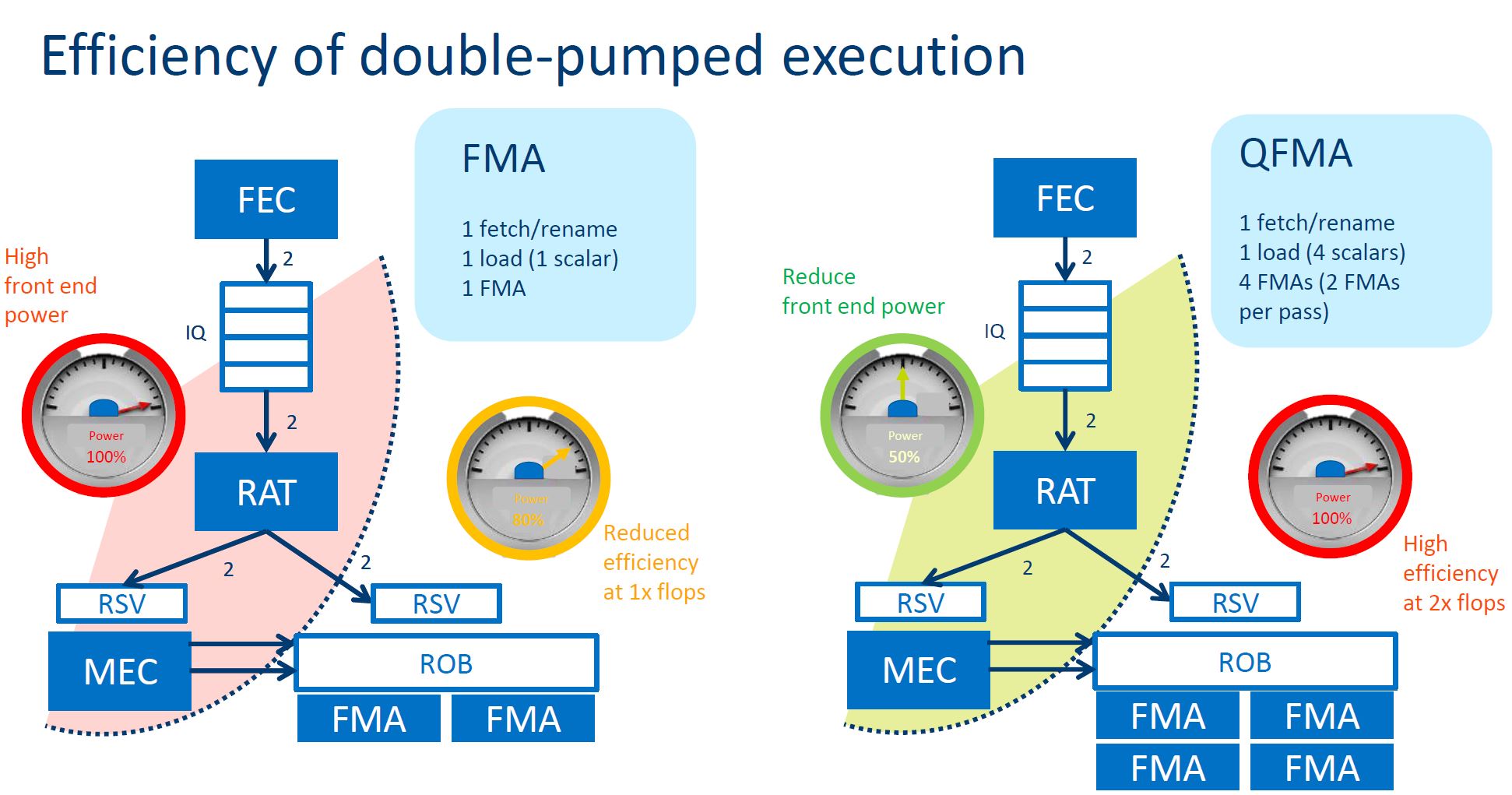
One of the more eyebrow-raising parts of the talk was that Intel is advocating Variable precision, VNNI-16. This uses integer math for neural network training.

When you use quad FMA and VNNI Intel calls it QVNNI:
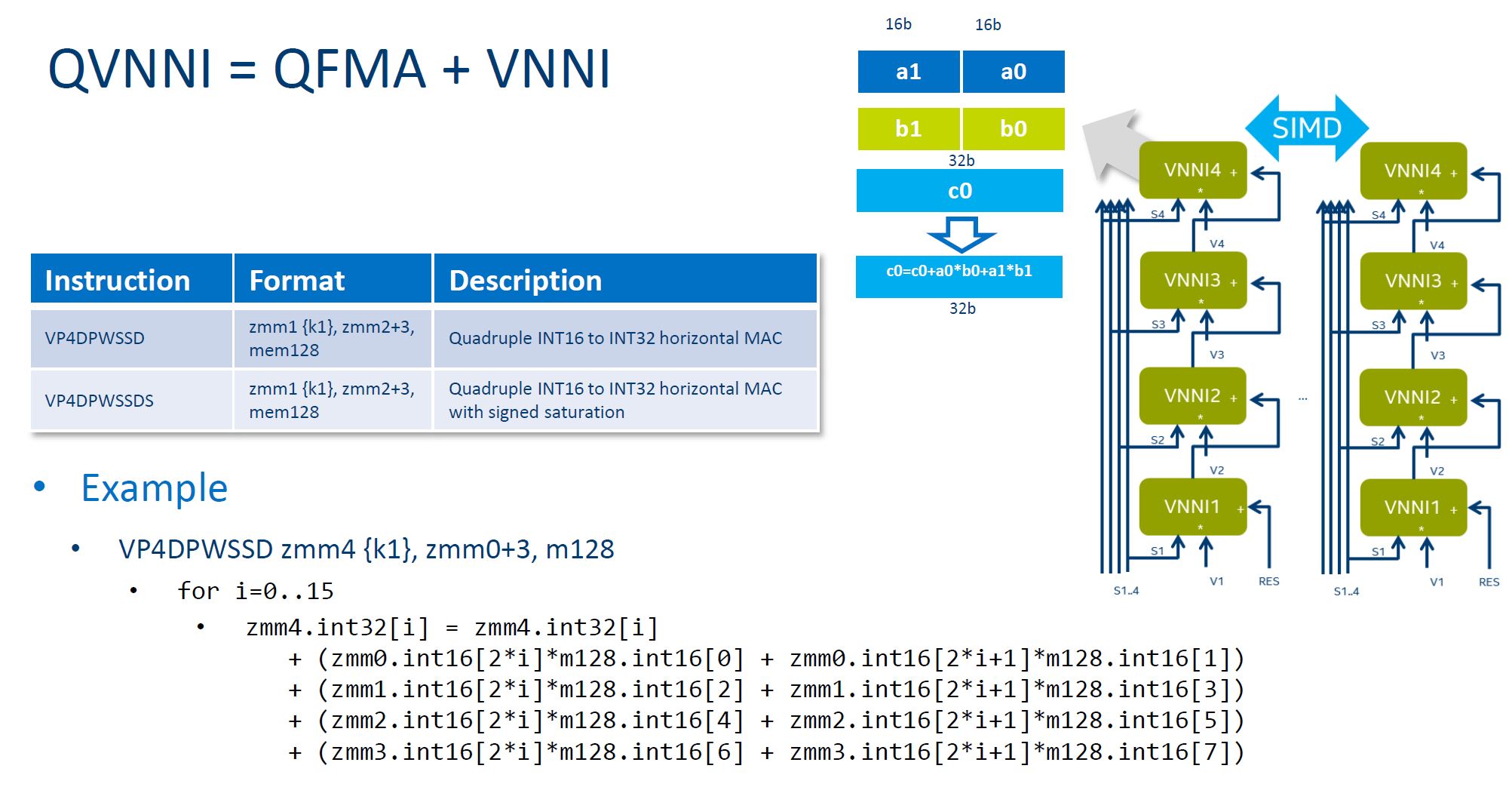
That is how Intel is claiming a 4x speed up in performance with Knights Mill.
Final Words
Overall the Intel Xeon Phi Knights Mill is interesting. First off, Intel is going to get more competitive in the deep learning space. What will make this more interesting is that Intel will have the ability to add Omni-Path to the SKUs, like in the Intel Xeon Scalable and Intel Xeon Phi x200 (Knights Landing.) Main supercomputing centers for deep learning yet the overall software ecosystem is heavily floating point. As a result Intel is releasing updates to MKL and other libraries to help its customers utilize these new chips with existing frameworks.



{kind=link}
Never understood the point of these since they can’t run the popular libraries faster then a GPU. Why would anyone buy one of these?