
Intel’s main AI chip until Falcon Shores is the Intel Gaudi 3. We got some new details at Hot Chips 2024. We have been covering this for some time (e.g., in April 2024), but it is supposed to be transferring from sampling to production through 2024.
Since this is being done live, please excuse typos. By 5PM fingers are feeling rough.
Intel Gaudi 3 for AI Training and Inference
This is the third generation of Gaudi since 2019 or so. This generation adds more compute more memory bandwidth, and capacity.
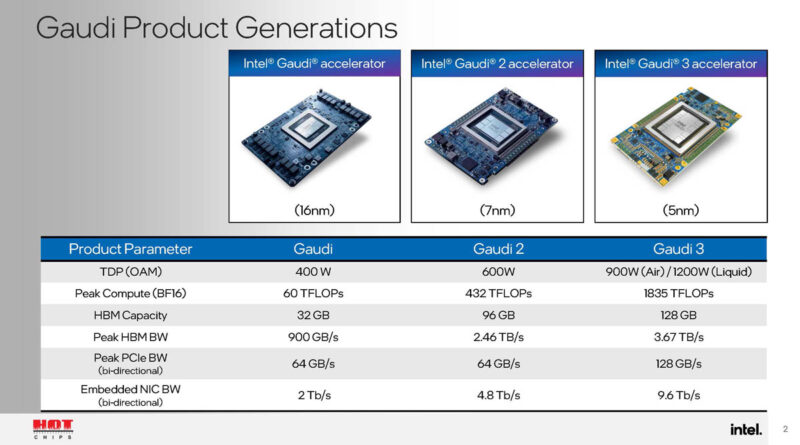
Here is the OAM module. The two interconnected compute dies are mirror images of each other.
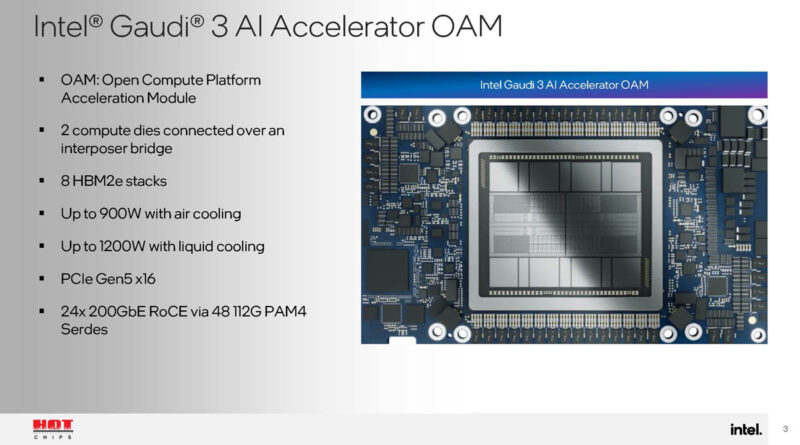
Here is the block diagram. Pretty interesting here is that there are 14 decoders for HEVC, H264, JPEG, and VP9. That is important for video inference. We also get a lot of speeds and feeds.
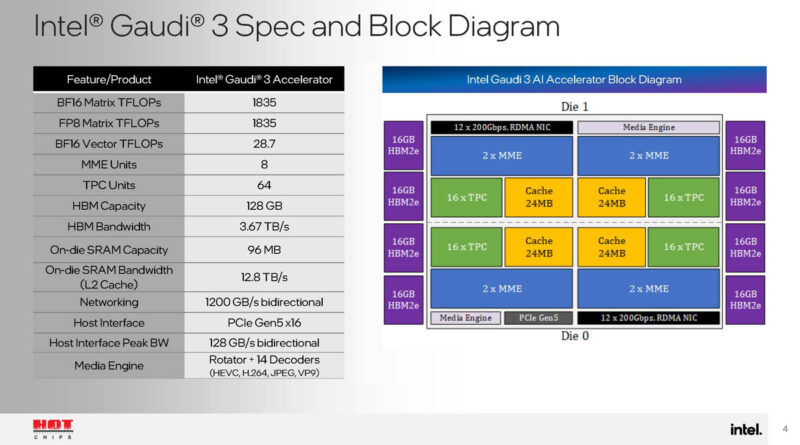
Each die has two DCOREs or deep learning cores. Each has a pair of matrix multiplication engines, and sixteen tensor processor cores, along with 24MB of cache.
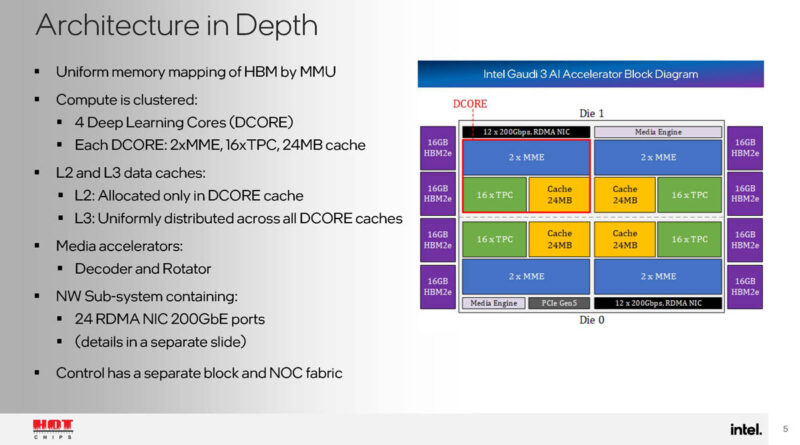
The matrix multiplication engine is the big matrix compute engine of the Gaudi 3 accelerator.
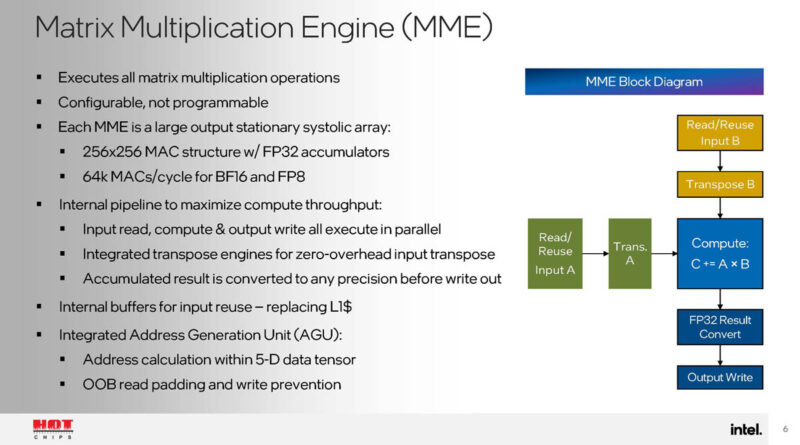
The tensor processors are for non-Matmul compute.
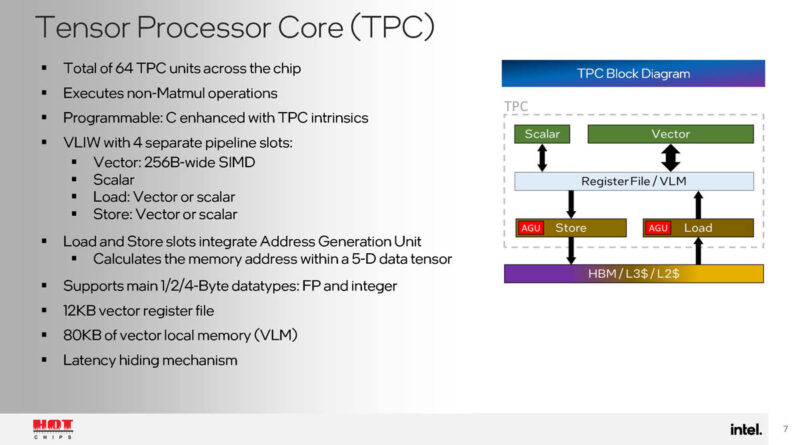
The L2, L3, and HBM are all in a unified memory space. There is also a memory context ID that allows tagging cache lines being shared. There is also a near memory compute capability to save some work for the TPC.
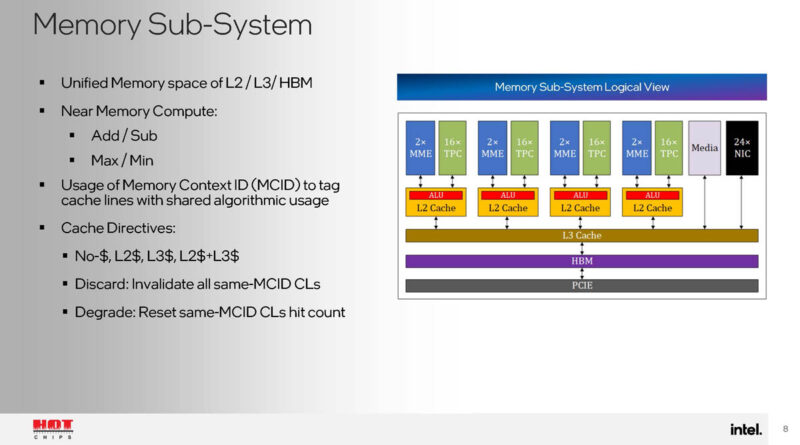
The Gaudi 3 also has a unique control path and a runtime driver.
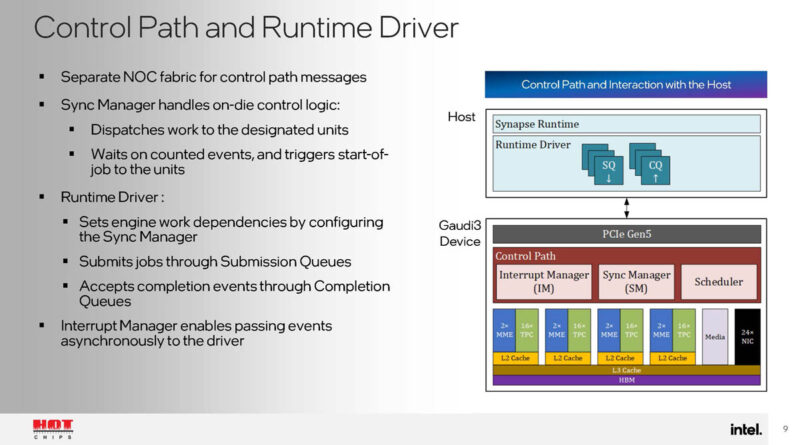
Here is a bit on the Intel Gaudi software suite. I somewhat wish that Intel had gone a step further and just talked about Gaudi suite to Falcon Shores. If Falcon Shores is 2025, it feels like that should be part of the discussion.
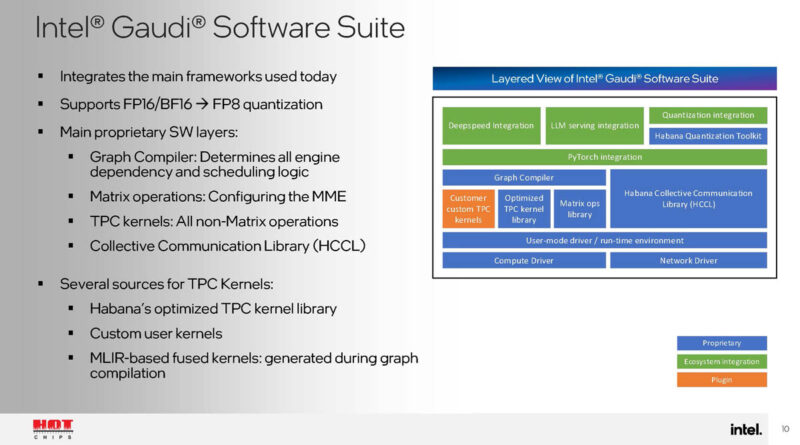
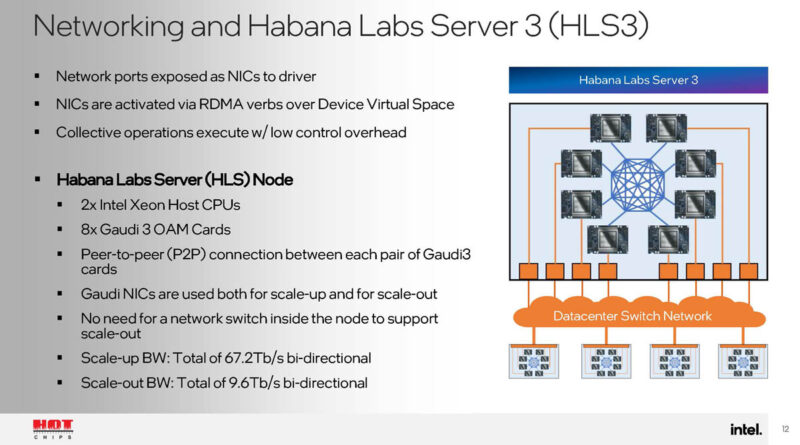
The graph compiler orchestrates how work is split among the accelerator. The NOC bandwidth was designed to support parallel MME and TPC work.
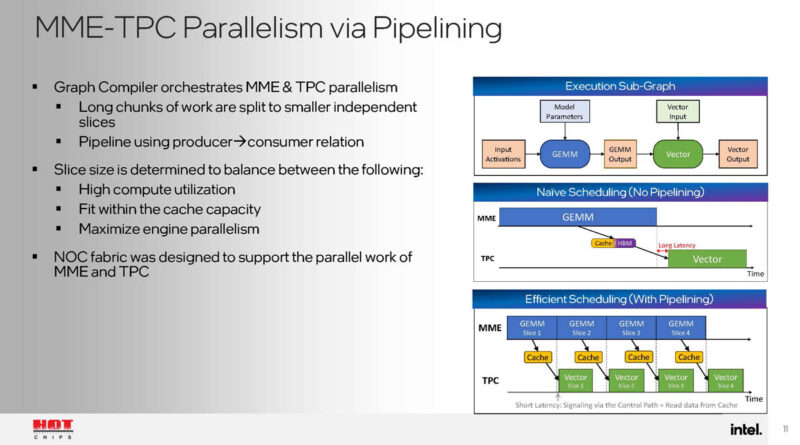
One of the cool things that Habana Labs has done since we saw them at Hot Chips 31 in 2019 when Hot Chips was last in the Stanford Memorial Theater. Habana uses RDMA Ethernet networking from the accelerators to connect each accelerator with each other, and then to larger topologies.
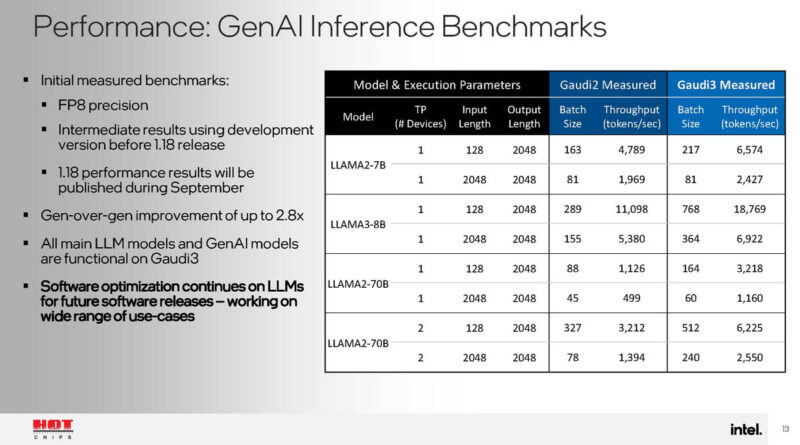
Here are some performance benchmarks. Scaling is happening, but it looks like the Llama3-8B is still being optimized.
With the Ethernet network, Gaudi 3 is designed to be scaled out easily using standard networking.

At the same time, the question is whether it is on “any Scale” or if they have practically tested to 65,000 or 100,000+ accelerators like on a high-end system.
Final Words
This is a chip that is ramping production so we should see more of them soon. We first showed the Gaudi 3 UBB earlier this year after showing the Gaudi 2 in the Intel Developer Cloud last year.
We also showed the Supermicro Gaudi 3 box in April 2024 as well.

We have lots here. Now we want to see these deployed at scale.



{kind=link}