
In 2022 we are going to see a bigger push towards 100GbE networking. 25GbE is still strong, but with the 400GbE and faster switches, such as the Marvell/Innovium Teralynx 7-based 32x 400GbE switch and the 800GbE generation of switches arrive, it will become more commonplace to see 100GbE going to individual servers. With that trend starting, we wanted to get ahead of it and look at a new 100GbE option from Intel, the E810-CQDA2.
Intel E810-CQDA2 Dual-Port 100GbE NIC
The Intel E810-CQDA2 is a low-profile card and one can tell this is a newer generation part with the massive attention to heat dissipation. There is a large heatsink along with small fins on the QSFP28 cages.
The other side of the card is relatively barren. We can, however, see that this is a PCIe Gen4 x16 card.

We are showing the full-height bracket in these photos, but the NIC also has a low-profile bracket option. One can see the two QSFP28 cages on the bracket.

The physical attributes are only a part of the story with this NIC. While that is a view more of the hardware, let us get into some of the big changes with these new NICs. Specifically, this is part of Intel’s foundational NIC series. That definition is changing as the series evolves.
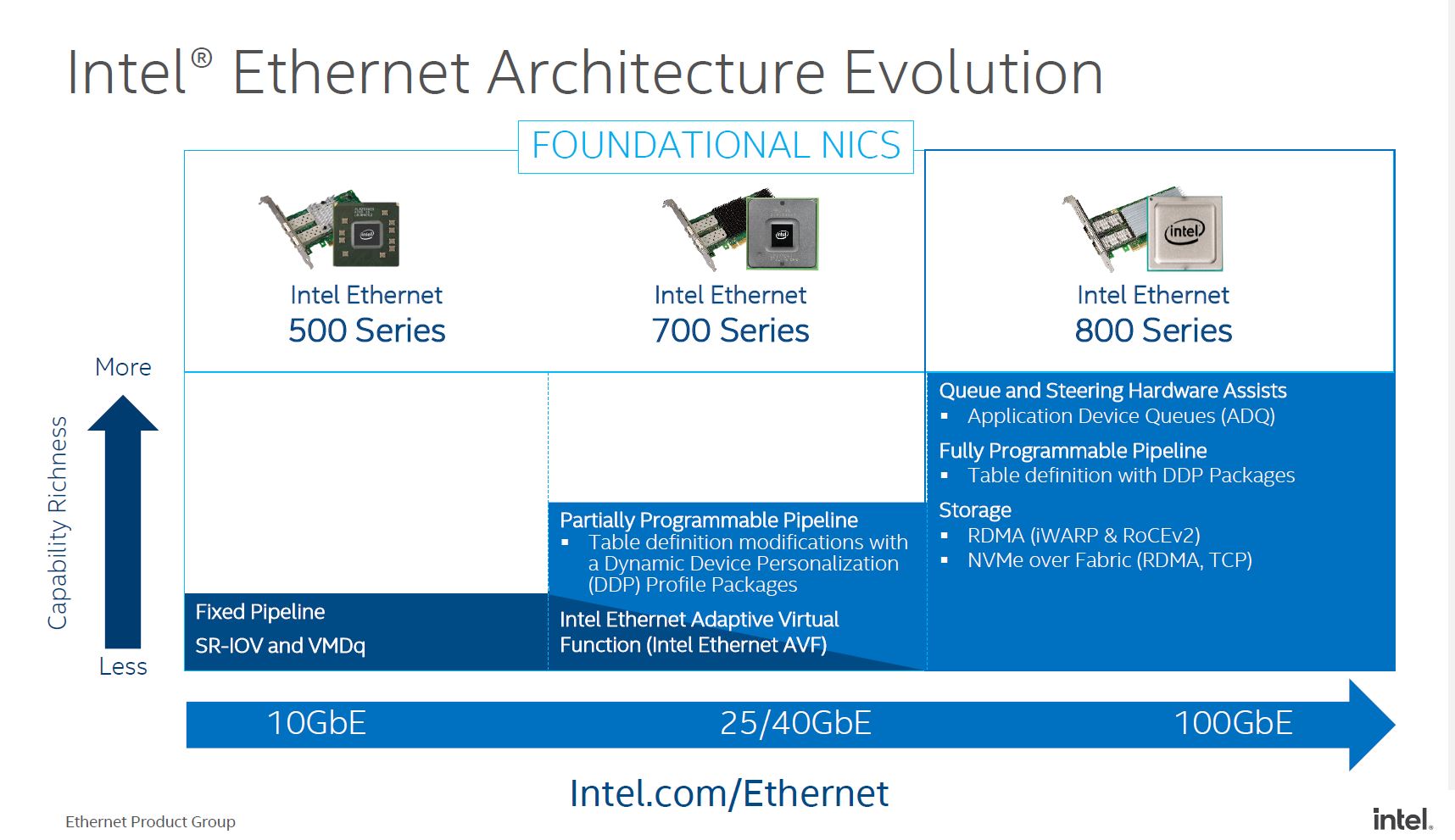
As you can see here, Intel is showing a higher-level feature set than it did in previous generations. This is not a DPU/ IPU like the Intel Mount Evans DPU IPU. Instead, it is a more basic connectivity option for adding networking to a server.
Intel Ethernet 810 Series Functionality
As we move into the 100GbE generation, NICs require more offload functionality. Dual 100GbE is not too far off from a PCIe Gen4 x16 slots bandwidth so offloads are important to keep CPU cores free. Without them, one can see eight cores in a modern system used to just push network traffic, using valuable resources. With the Ethernet 800 series, Intel needed to increase feature sets to allow systems to handle higher speeds and also to stay competitive. To do so, they primarily have three new technologies ADQ, NVMeoF, and DDP. We are going to discuss each.
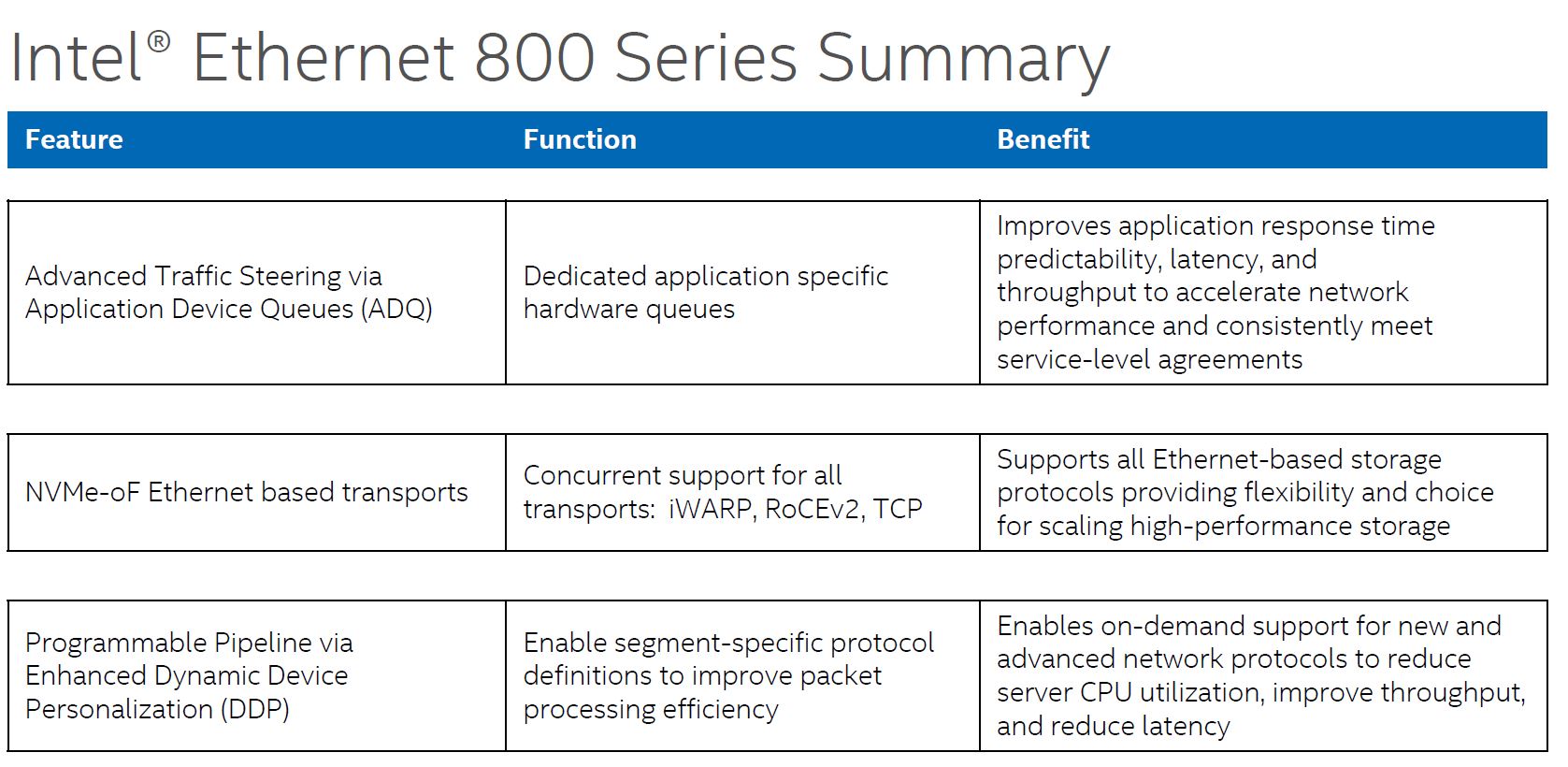
Application Device Queues (ADQ) are important on 100Gbps links. At 100GbE speeds, there are likely different types of traffic on the link. For example, there may be an internal management UI application that is OK with a 1ms delay every so often, but there can be a critical sensor network or web front-end application that needs a predictable SLA. That is the differentiated treatment that ADQ is trying to address.

Effectively, with ADQ, Intel NICs are able to prioritize network traffic based on the application.

When we looked into ADQ, one of the important aspects is that prioritization needs to be defined. That is an extra step so this is not necessarily a “free” feature since there is likely some development work. Intel has some great examples with Memcached for example, but in one server Memcached may be a primary application, and in another, it may be an ancillary function which means that prioritization needs to happen at the customer/ solution level. Intel is making this relatively easy, but it is an extra step.
NVMeoF is another area where there is a huge upgrade. In the Intel Ethernet 700 series, Intel focused on iWARP for its NVMeoF efforts. At the same time, some of its competitors bet on RoCE. Today, RoCEv2 has become extremely popular. Intel is supporting both iWARP and RoCEv2 in the Ethernet 800 series.

The NVMeoF feature is important since that is a major application area for 100GbE NICs. A PCIe Gen3 x4 NVMe SSD is roughly equivalent to a 25GbE port worth of bandwidth (as we saw in the Kioxia EM6 25GbE NVMe-oF SSD, so a dual 100GbE NIC provides roughly as much bandwidth as 8x NVMe SSDs in the Gen3 era. By increasing support for NVMeoF, the Intel 800 series Ethernet NICs such as the E810 series become more useful.

What is more, one can combine NVMe/TCP and ADQ to get closer to some of the iWARP and RoCEv2 performance figures.
Dynamic Device Personalization or DDP is perhaps the other big feature of this NIC. Part of Intel’s vision for its foundational NIC series is that the costs are relatively low. As such, there is only so big of an ASIC one can build to keep costs reasonable. While Mellanox tends to just add more acceleration/ offload in each generation, Intel built some logic that is customizable.
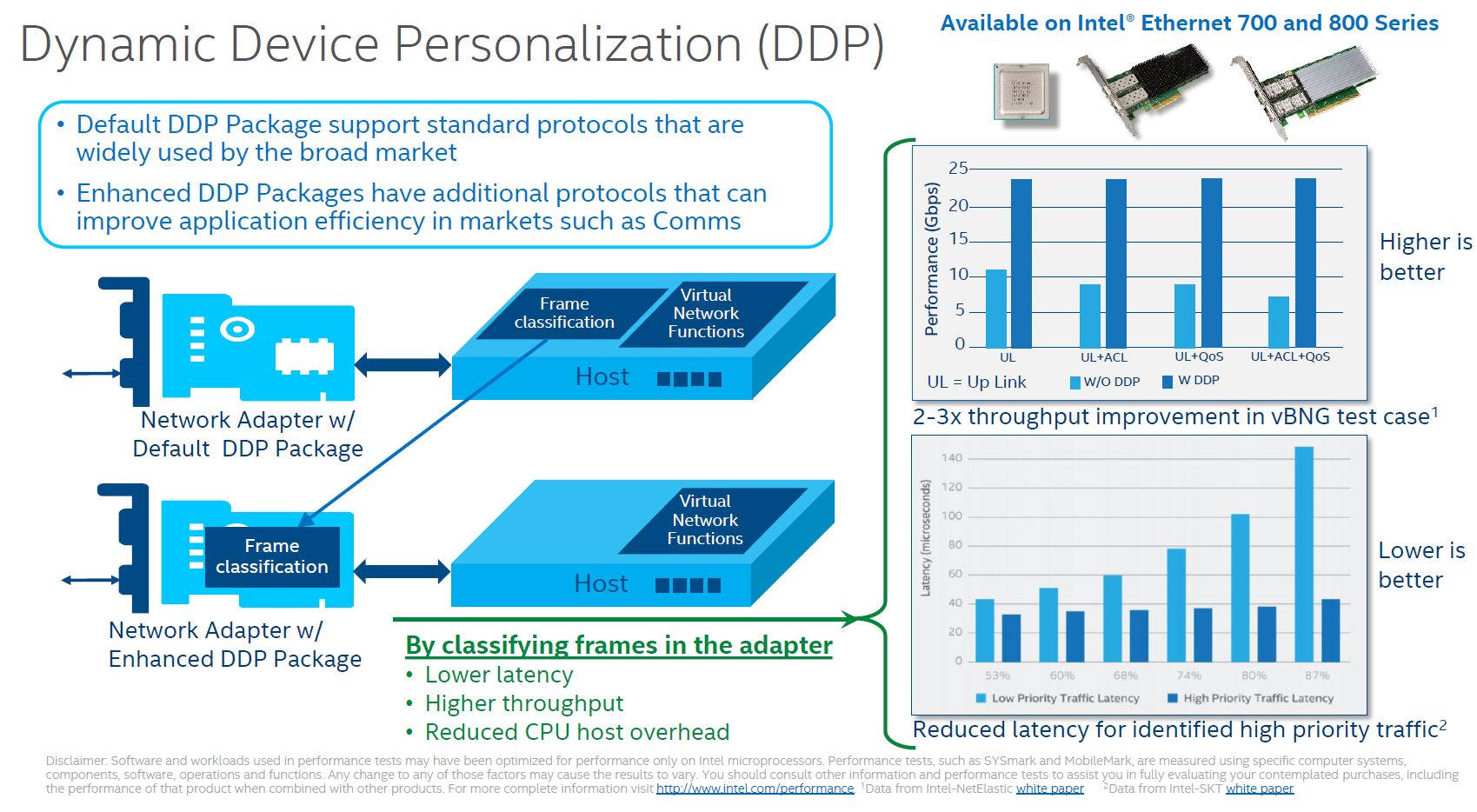
This is not a new technology. The Ethernet 700 series of Fortville adapters had the feature, however, it was limited in scope. Not only were there fewer options, but the customization was effectively limited to adding a single DDP protocol given the limited ASIC capacity.

With the Intel Ethernet 800 series, we get more capacity to load custom protocol packages in the NIC. Aside from the default package, the DDP for communications package was a very early package that was freely available from early in the process.
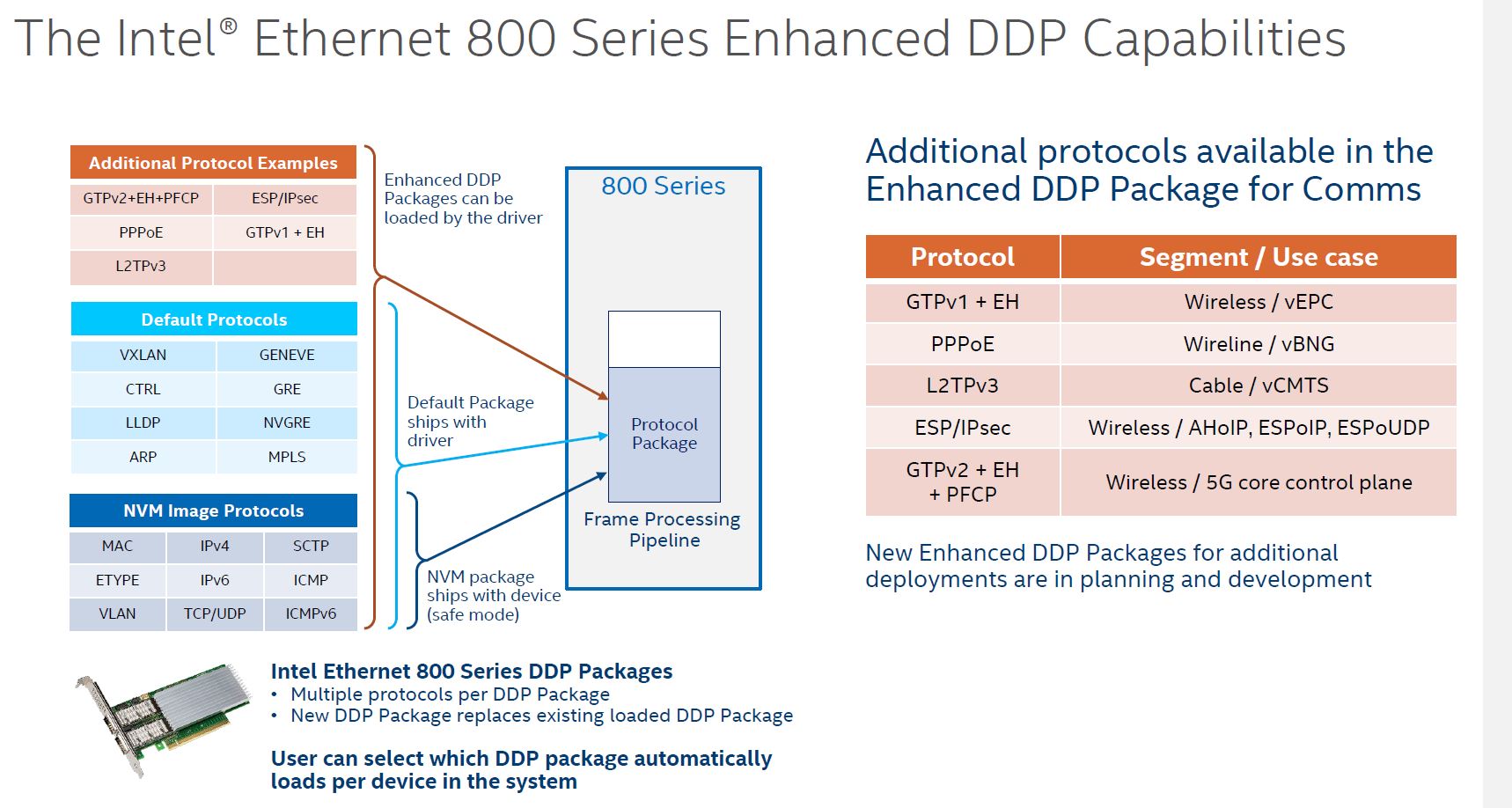
Here is a table of what one gets for protocols and packet types both by default, and added by the Comms DDP package:
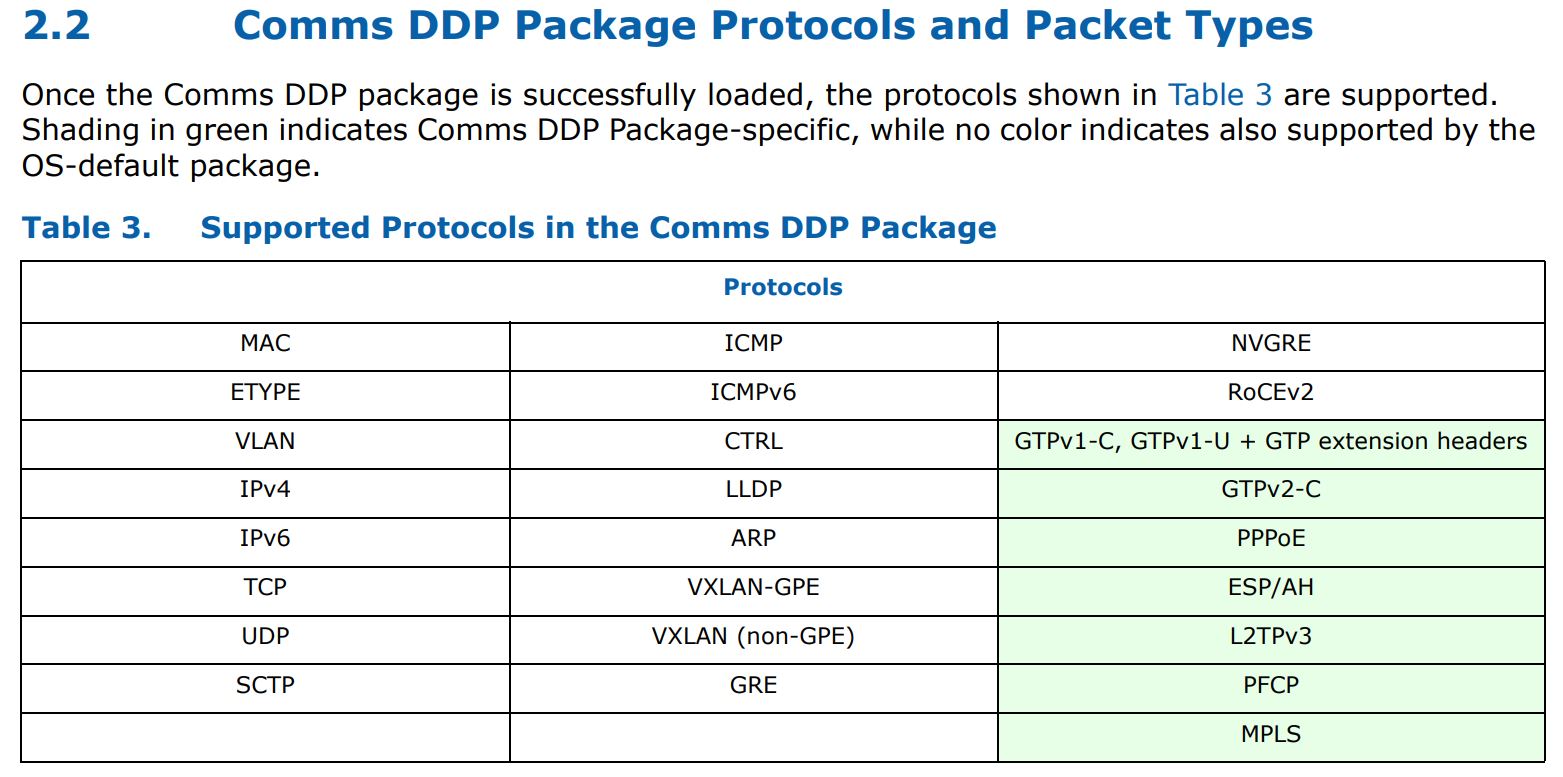
As you can see, we get features such as MPLS processing added with the Comms package. These DDP portions can be customized as well so one can use the set of protocols that matter and have them load at boot time while trimming extraneous functionality.
Next, we are going to take a quick look at some of our experience with the NIC including driver, performance, and power consumption before getting to our final words.



{kind=link}
When one gets to 100 Gbit with multiple types of hardware offload, the quality of the device driver available in the OS becomes more and more important (similar to what happened with all those GPUs).
Moving forward it would be nice to measure actual performance for the same suite of tests under Linux, FreeBSD and Windows for comparison. If there are significant differences, that would be important, because customers are often locked to the operating system more than any particular network card.
the fine print on their datasheets is not very clear. There are a few different skus for these 100G cards. specifically, there is the e810-2cqda2 and the e810-cqda2 which this article references. the 2 in the first sku refers to 2 controllers on a single card (that is my assumption.) It seems like the card in this article is only capable of 100Gbps FD not 200Gbps FD. Once again, this is not clear (at least to me) from reading the intel docs.
When looking at the e810-cqda2:
Using EPCT, the Intel® Ethernet Network Adapter E810 (Dual or Single Port), can be programmed
to act as many different physical network adapters, with a maximum throughput of 100Gbps
Then looking at the e810-2cqda2:
The Intel® Ethernet Network Adapter E810-2CQDA2 delivers up to 200Gbps of total bandwidth in PCIe
4.0-compliant systems¹. Each QSFP28 port supports up to 100Gbps, providing the functionality and throughput
of two 100Gbps adapters in a single bifurcated PCIe 4.0 x16 slot.
Can someone clarify if the card in this article (e810-cqda2) is capable of 200Gbps FD?
thanks,
jp
This is the 100G version. That’s probably why they say they hit 100G on it.
My question is regarding the 2 ports of 100G. It is not clear if the whole card can only generate 100G at the same time or can it generate 200G? The data sheets make it seem like only the card with 2 controllers can generate a combined 200G.
This is only a 100Gb card since it’s not the 2 card like jp mentioned.
It’s the same for the other types of cards like this one they reviewed https://www.servethehome.com/supermicro-aoc-s100gc-i2c-100gbe-intel-800-series-nic-review/
So are you saying this “dual 100 Gbps” card is only capable of running a *total* of 100 Gbps? i.e. at full load you can only pump 50 Gbps through both ports at the same time?
That doesn’t seem right, because PCIe 3.0 x16 has a bandwidth of 150 Gbps so if the combined speed was only 100 Gbps, they wouldn’t have had to move to PCIe 4.0.
PCIe 4.0 can do 150 Gbps in a x8 slot, with a x16 providing 300 Gbps, so the only reason they’d need both PCIe 4.0 and an x16 slot is to exceed 150 Gbps.
So it would seem they moved to PCIe 4.0 to make it possible to run both ports at 100 Gbps at the same time.
However how does this work with full duplex? Does 100 Gbps per port mean if you saturate a single port in both directions, you will only get 50 Gbps incoming and 50 Gbps outgoing?
Most full duplex cards let you transmit and receive at full line speed at the same time, however that would mean this card would need 400 Gbps of PCIe bandwidth, in order to transmit 2x 100 Gbps and receive 2x 100 Gbps at the same time. PCIe 5.0 x16 or PCIe 6.0 x8 would be required to reach those speeds, PCIe 4.0 is too slow.
Or does it just mean the PCIe 4.0 x16 bandwidth of 300 Gbps is the limit, and each port can run 100G up and 100G down at the same time, but the card overall is limited to 300G?
I guess it would be really useful to see some more detailed speed tests of each configuration.
Let me try and explain another way. I have several mellanox connectx-5 516a-cdat (the “d” in cdat means that it is pcie 4.0) Those cards are dual port 100GE. If I run a test with both ports connected b2b with a dac cable and run a bidirectional test, I get appox 200Gbps. My question is will the intel cards do the same? It seems like only the e810-2cqda2 will do that but the e810-cqda2 will only do 100Gbps. Can anyone confirm?
and just for clarification on bw/data rates:
Unidirectional Bandwidth: PCIe 3.0 vs. PCIe 4.0
PCIe Generation x1 x4 x8 x16
PCIe 3.0 1 GB/s 4 GB/s 8 GB/s 16 GB/s
PCIe 4.0 2 GB/s 8 GB/s 16 GB/s 32 GB/s
and also yes, the specs support FD so the max throughput for pcie 4.0 x16 would be 256Gbps unidirectional and 512Gbps bidirectional.
that is why a dual port 100GE nic needs to use pcie 4.0 x16 or else it would be limited by the pcie 3.0 x16 bus (only 128Gbps not the 200Gbps that would be needed at full rate.)
@jp When you say “Those cards are dual port 100GE. If I run a test with both ports connected b2b with a dac cable and run a bidirectional test, I get appox 200Gbps” – what happens if you run the bidirectional test on one port? You should get 200 Gbps as well (100G in and 100G out), right?
From your explanation it sounds like you’re running both ports bidirectionally at the same time (2x 100G up, 2x 100G down) but you’re only getting 200 G overall, whereas I would’ve expected you to top out closer to 320 G overall since that’s the PCIe 4.0 limit. Obviously you wouldn’t get the full 400 G because the PCIe bus isn’t fast enough for that.
It would be interesting to see what the bidirectional/full duplex speed tests are for just a single 100G port vs running both ports at the same time.
Interesting how Omnipath was a way to sell cores, but now offload is Intel’s schtick. Wonder why…
@Malvineous, PCIe is full duplex, so even with fully loaded dual 100GB Ethernet (up and down) the traffic cannot saturate a x16 PCIe4 link.
@Nikolay, it is correct, PCIe is full duplex symmetrical bidirectional, it was one of the major selling point of PCIe against AGP
Ah, thanks all, you’re right, I was reading the PCIe speeds as total but PCIe 4.0 x16 being 300 Gbps is 600 Gbps total, 300 G in each direction.
This means PCIe 4.0 x16 is enough to handle 3x 100G up and 3x 100G down, at the same time (not taking any overheads into account) so the PCIe bandwidth won’t be the limiting factor in a dual port 100G card.
@Malvineous, no it won’t. I don’t know where you get your numbers from but x16 PCIe 4.0 can handle slightly less than 32GB/s in each direction (31.5 according to Wikipedia). Multiply by 8 to arrive at ~250Gb/s. Furthermore, since PCie is a packet switched network it has protocol overhead for each packet. For the smallest supported size mandated by the standard – 128 bytes – the overhead is around 20% that you need to subtract from the figure above. If your root complex and device support it, you can jack this up to either 256 or 512 bytes (it can go up to 4096 but support for such sizes is not common) so the overhead gets down to 10% or 5%. Sure, Ethernet also has protocol overhead but the packet size is bigger even in the common case (1500B) and I guess such NICs support jumbo frames so the protocol overhead can become negligible. 2x100GB is a perfect match.
BTW, by default the Linux kernel sets the MaxPayloadSize to 128 bytes regardless of the actual topology. You have to use the pci=pcie_bus_perf kernel parameter to instruct it to set the MPS values for max performance.
@Nikolay, I was using rough figures from Wikipedia too. To be precise, it says that PCI-e 4.0 x16 has a bandwidth of 31.508 gigabytes/sec. 100 Gbps is 100,000,000,000 bits/sec since network devices use the same silly marketing multiples that hard disk manufacturers use, so that works out to 11.641 gigabytes/sec.
So at 24.28 GB/sec in each direction for 2x 100 Gbps, that fits well within PCI-e’s 31.5 GB/sec, even accounting for the overheads you mention. I don’t think the overheads apply to Ethernet though because my understanding is that the Ethernet protocol overhead is included in the 100 Gbps speed (i.e. your usable bandwidth will be slightly under 100 G). But I am not familiar enough to know whether the Ethernet overheads are handled in software (and need to travel over the PCI-e bus) or whether the card handles them in hardware (so you would never be sending the full 100 G over the PCI-e bus).
You are right that there is not quite enough bandwidth available for 300 Gbps (34.92 GB/sec). I was thinking it would just scrape through if PCI-e was 31.5 GB/sec but if the PCI-e overheads are as high as you say, then this is probably not the case – which is why I said “not taking any overheads into account” :)
Generic question. For running at different speeds on a port, can 2 ports run at different speeds. Like having 2 different SFPs to support different speeds ?
e810-cqda2 cabled with 2x100G will not be able to saturate both connections, actually total bandwidth supposedly is limited at 100G for BOTH ports together
e810-2cqda2 basically is 2 singleport NICs on one card and that would in total provide 200G, i.e. 2x100G in bandwidth.
It would really help if intel would document that in their ARK in a way that it cannot only be figured out when you know what limitation you are looking for.
All in all, the intel 810 seems unable to work as a DropInReplacement for any dual port 100G NICs from Mellanox, Broadcom etc