
Today we have an update from Intel about its data center and AI business. We were pre-briefed on the update but will be covering the event live. Expect to hear more about Intel Xeon roadmap updates as well as new technologies, including the MCR DIMM or Multiplexer Combined Ranks DIMM that we covered recently.
Note, this is being covered live so please excuse typos.
Intel DCAI 2023 Update New Technology and Updated Xeon Roadmap
A big part of today’s event is focused on the investor community, so there is a big portion of this that is on the TAM for DCAI or market opportunity.
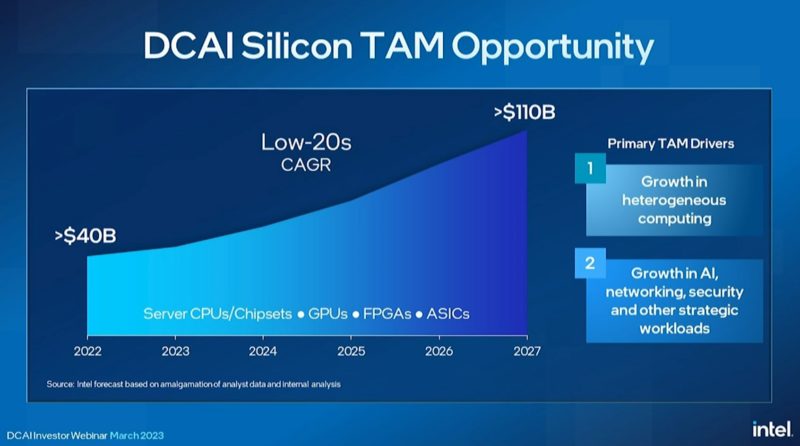
Intel said that it is going to increase cores per socket and so it expects its core growth to follow industry trends even if sockets growth is different.
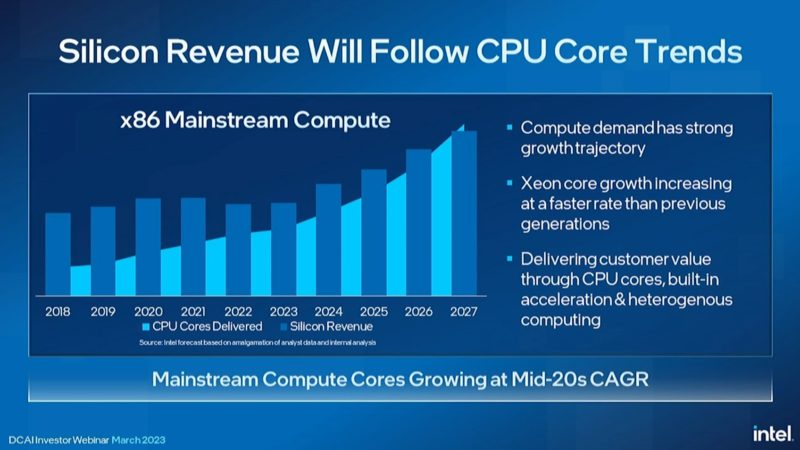
Intel says it is going to accelerate its core density faster than it had been. Here is the Updated AMD EPYC and Intel Xeon Core Counts Over Time view that we shared earlier this year.

Intel said it plans to raise ASP to capture the value of having more cores. It will also capture the value from other portfolio IP.
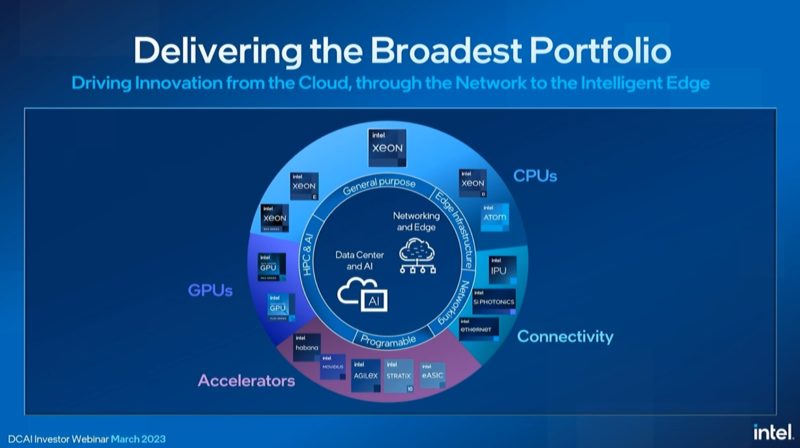
Intel says that the market has grown to support both higher-performance cores as well as lower-performance dense cores.

Intel is talking about P-core “Rapids” products and E-core “Forest” chips.

Intel says it plans to re-use I/O chiplets and memory controllers between Rapids and Forest products. Intel seems to be following AMD EPYC’s IO Die-like designs.
Intel says that it has 450+ 4th Gen Intel Xeon Scalable “Sapphire Rapids” designs, but less than half of those are currently in the market. Intel says that the crossover for SPR volume will happen mid-year. It also hopes when China comes back and when enterprises start spending less cautiously that it will help increase sales.

Intel is showing a demo using Intel AMX acceleration to show how its chips can be faster than AMD EPYC parts. You can learn more about that in: Hands-on Benchmarking with Intel Sapphire Rapids Xeon Accelerators.
Later this year is the Emerald Rapids. Here is that chip. I missed the <5 second clip of the chip close up.

Emerald Rapdis will be the 5th Gen Intel Xeon Scalable series. It is a drop-in replacement for Sapphire Rapids servers. This is different than the Ice Lake generation which was a single-generation platform.

5th Gen Xeon Scalable will be on Intel 7.
Sierra Forest in the first half of 2024. Granite Rapids shortly thereafter. Granite Rapids will be on Intel 3.

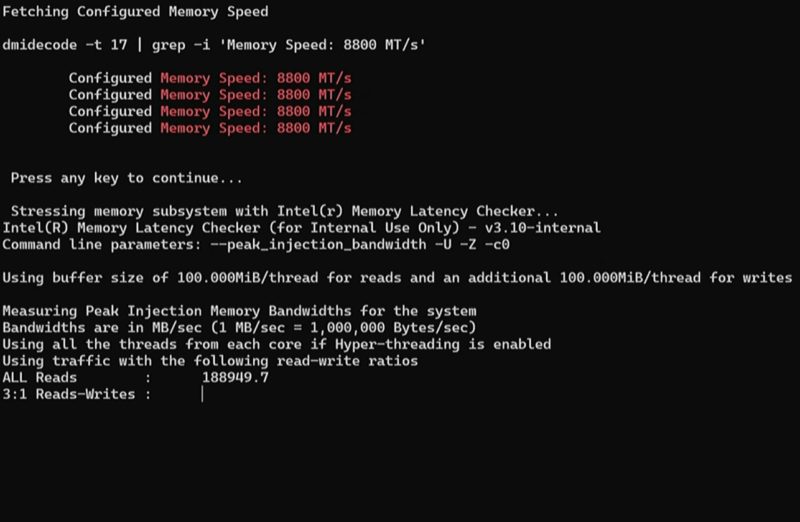
Granite Rapids will have MCR DIMMs. Those will offer 1.5TB/s of memory bandwidth in a dual-socket server.

Here is DDR5-8800 running with Intel MLC:
Intel’s Sierra Forest is expected in 1H’24. We usually expect “1H” to mean June based on previous launches. This will be an Intel 3 platform.

Sierra Forest is 144 cores and is booting OSes and running stress-ng.
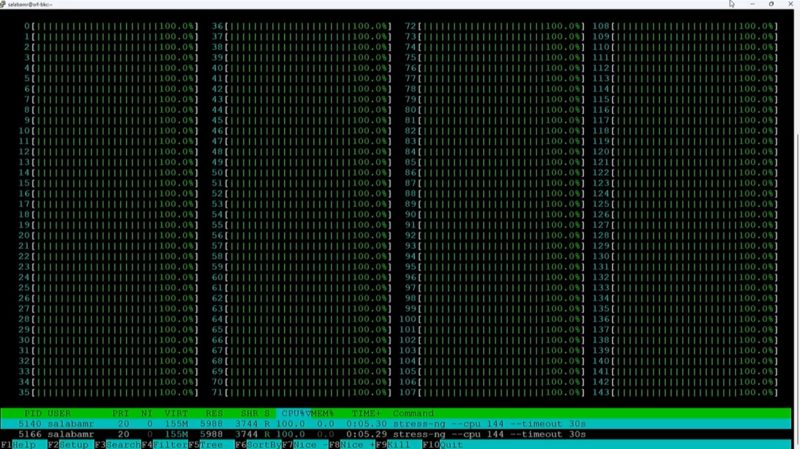
Clearwater Forest in Intel 18A in 2025. This is the next E-core design.
Here is the Xeon roadmap between now and 2025.

Here is the DCAI Roadmap including other products. I asked about the lack of HBM accelerators. Intel told me that they will be addressing higher performance memory updates in the future.
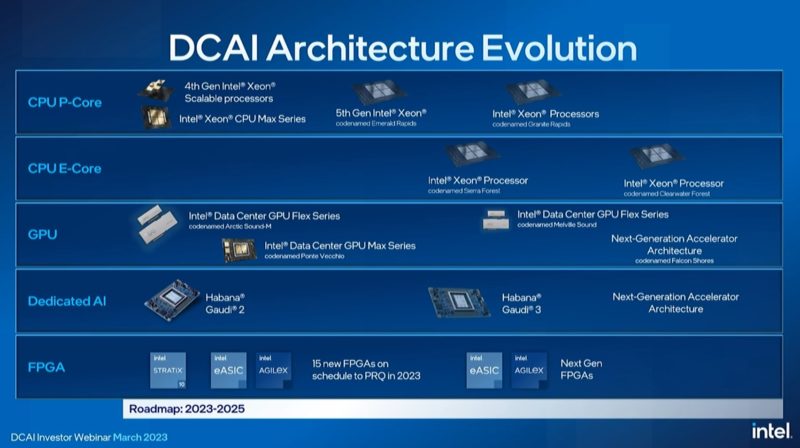
Something to note here is that the GPU, Habana Gaudi AI accelerator and FPGAs are continuing. 15 new FPGAs in 2023 is a lot.
Here is Intel’s AI Accelerator TAM:

Intel is talking about OneAPI and SYCL. The pace of this is fast enough that we are going to leave most of that for others since there is not as much being announced here and seems like it is more of a recap.
More to come as the event progresses.
Final Words
There is a lot in here. The P-core versus E-core mix is something we are really interested in at STH. Intel gave us a wide range of the expected future mix of P-cores versus E-cores that it could be shipping in a few years. To be frank, I am much more excited about Sierra Forest than Emerald Rapids at this point. As we increase the number of dedicated accelerators in the ecosystem, having E-cores alongside accelerators may make sense. Also, there are many servers simply running nginx serving web pages that do not need optimizations for high-performance computing.

I asked about what the IO Die or Tile will be called. Intel told me that the exact name is not finalized.



{kind=link}
What kind of “accelerators” does Sierra Forest have? I guess not AMX.
BTW the AMX demo was a joke with weird core count comparisons and still refusing to compare to low end GPUs like A10 or L40. Power and performance are so much better on those and they don’t block the cores from doing other tasks while doing inference. Who is really using AMX? Next to no one.
It’s confusing how Intel thinks it can raise ASPs based on their IP. Intel is currently coming from a position of weakness and should price its products as such until it catches up.
Who’s sitting around throwing cash at Intel for IAA or other accelerators? It’s niche silicon for niche markets. Intel’s accelerator play is a hard sell for the majority of the market and the fact that they’re really running with this is bewildering.
@ssnseawolf
This was an investor event.
It was meant to sell this to investors, not customers. They have to price their products at whatever price the market deems appropriate.
“Intel seems to be following AMD EPYC’s IO Die-like designs.”
I believe SPR put separate 2 channel memory controllers on each of the 4 compute tiles …
I would guess Intel’s new designs will more likely move to the Foveros stacked compute over IO. What in the presentation gave you the idea that they will use something like the sprawling 2d layout of the EPIC designs?
JayN – they are moving to an I/O die/ tile setup with memory controllers and PCIe/CXL like AMD did. I did not say they are going to implement it exactly as it is today, nor do I think AMD in 2025 will have the same setup as they do today.
Decoupling the I/O die/tile will allow AMD to re-use the Genoa IOD this year for Zen 4c based Bergamo. Intel will also have a solution to allow it to validate the I/O die/ tile and then use it in multiple parts as they get into the Sierra era.
PVC had TLB, PCIE, Fabric in the base tile, as well as 288MB of SRAM. I expect to see this design move to their CPUs.
https://www.hpcuserforum.com/wp-content/uploads/2021/05/Gomes_Intel_Ponte-Vecchio_Mar2022-HPC-UF.pdf
One thing was a surprise … the EMR chip appeared to be 2 tiles. Was that an AP part or did they drop the 4 EMIB connected tiles of SPR?
“Intel will also have a solution to allow it to validate the I/O die/ tile and then use it in multiple parts …”
I don’t think the 3D stacking will allow Intel to re-use many base tile designs. It is too much tied to the placement of connections between base tile and compute tile. I suspect the PowerVIA use complicates this further.
Anandtech shows a slide of a Granite Rapids with what appears to be compute tiles in the center and io tiles around it … not on a base tile. They also commented that Sierra Forest and Granite Rapids will share a platform and IO tiles, with only the compute tiles being E or P.
Can we infer that Sierra Forest will also support the MCR DIMMS?
@Lasertoe
It would have been really useful information to compare SPR against A100 on BF16 ResNet/Transformer inference. To run inference on transformers with 300B parameters, you can get an SPR CPU and equip it with 384GB of DRAM, or buy 4xA100 80GB. The value is there.
SPR has a peak AMX of around 120~170T BF16 tensor, A100 is 312T BF16 tensor. But SPR is way weaker on vector workloads, maybe RTX2060-tier. so we have to see a real world head-to-head comparison.
@grrr
1. You don’t need 4xA100 just because of the DRAM. One A100 can reload data when needed. It’s not like SPRs memory interface comes close to saturating the cores with data. There is no real value for AMX in SPR.
2. Your SPR AMX performance numbers are completely off. You seem to think that AMX can do one TMUL every cycle (That would come to 120 TFLOPs at 2 GHz for 60c when executed every cycle).
According to the “Intel® 64 and IA-32 Architectures Optimization Reference Manual” all TDP/* (like TDPBF16PS for BF16) operations can be executed only every 16 cycles (and 52 cycles Latency). This results in a fraction of the performance of A10 or L4. AMX is a joke. Your confusion is the result of Intel’s absurd marketing.
Forget about my last post or delete it. i didn’t account for the max 16 columns.
on the topic of SPR AMX performance …
the tomshardware coverage of the live DCAI event includes a slide that I don’t recall seeing in the video. Perhaps it came from the slide deck.
https://cdn.mos.cms.futurecdn.net/QWFiW7YGZKQMfHceGEXe6L.png
It shows SPR AMX performance vs Genoa of over 5x on the BERT large model. So, doesn’t seem to be a joke.
Hi JayN. Intel did an AMX demo. It said that having AMX onboard was faster than having no-AMX because they wanted to capitalize on the AI buzz and saying they have the feature in their chip. Since we did not get any other performance numbers, and the only thing shown was the new AMX feature, we omitted that portion.