Intel Atom C3858 Benchmarks
For this exercise, we are using our legacy Linux-Bench scripts which help us see cross-platform “least common denominator” results we have been using for years as well as several results from our updated Linux-Bench2 scripts. At this point, our benchmarking sessions take days to run and we are generating well over a thousand data points. We are also running workloads for software companies that want to see how their software works on the latest hardware. As a result, this is a small sample of the data we are collecting and can share publicly. Our position is always that we are happy to provide some free data but we also have services to let companies run their own workloads in our lab, such as with our DemoEval service. What we do provide is an extremely controlled environment where we know every step is exactly the same and each run is done in a real-world data center, not a test bench.
We are going to show off a few results, and highlight a number of interesting data points in this article.
Python Linux 4.4.2 Kernel Compile Benchmark
This is one of the most requested benchmarks for STH over the past few years. The task was simple, we have a standard configuration file, the Linux 4.4.2 kernel from kernel.org, and make the standard auto-generated configuration utilizing every thread in the system. We are expressing results in terms of compiles per hour to make the results easier to read:
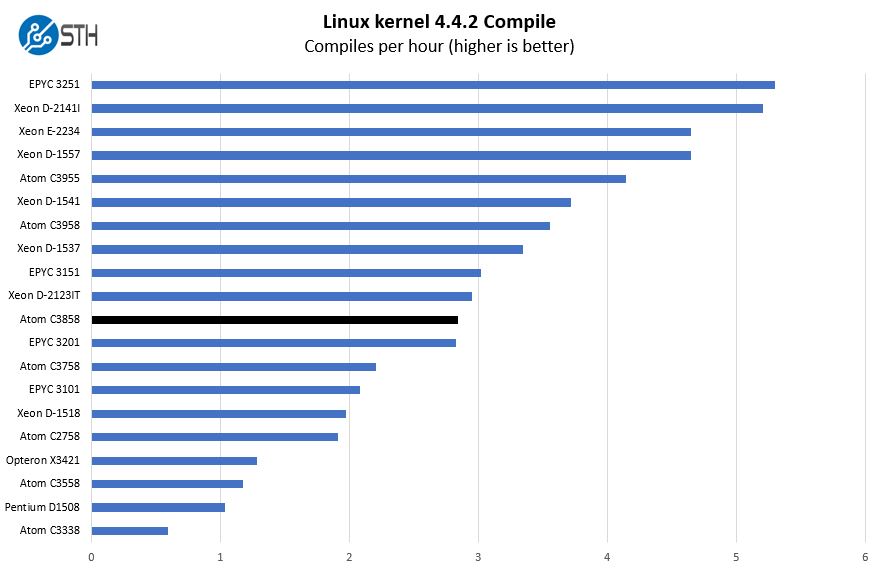
One of the key features of the Atom C3858, and the Atom C3000 line in general, is that it utilizes higher numbers of lower frequency cores to achieve performance levels at lower clock speed. This in turn drives lower TDP which is important for this segment.
c-ray 1.1 Performance
We have been using c-ray for our performance testing for years now. It is a ray tracing benchmark that is extremely popular to show differences in processors under multi-threaded workloads. We are going to use our 4K results which work well at this end of the performance spectrum.
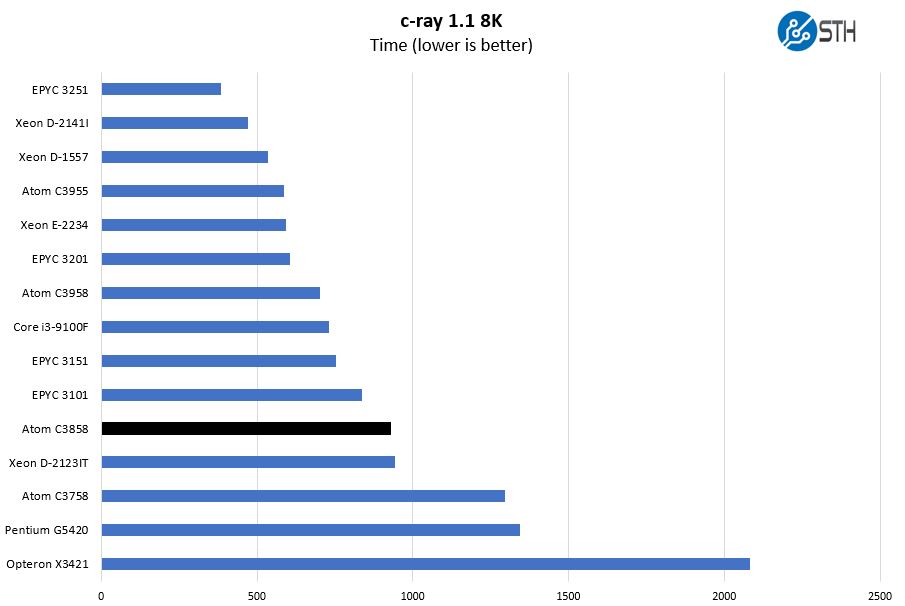
In this benchmark, the AMD architecture tends to perform well. We also see that this is one of the areas that the Atom C3000 series traditionally performs not overly well on.
7-zip Compression Performance
7-zip is a widely used compression/ decompression program that works cross-platform. We started using the program during our early days with Windows testing. It is now part of Linux-Bench.
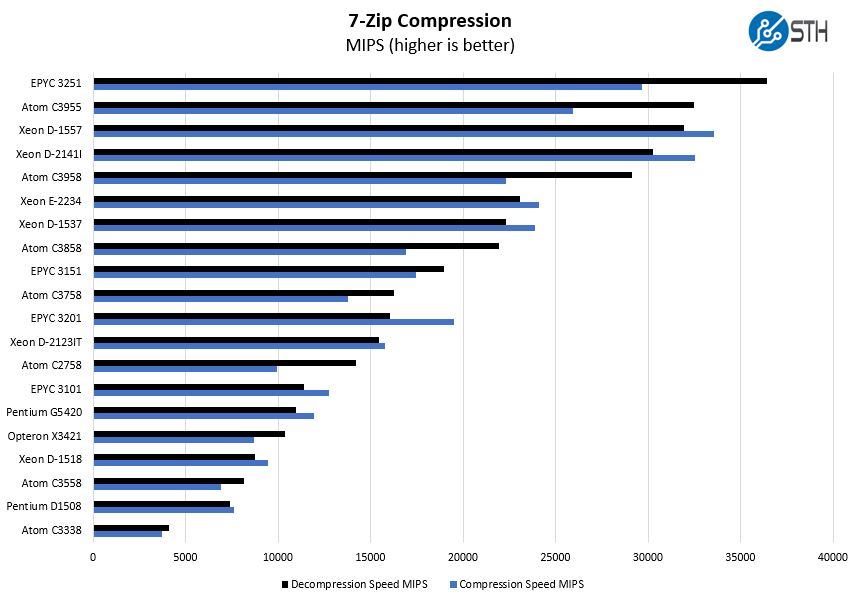
On the compression side, we again see some significant performance gains over the Intel Atom C3758. These chips have the same TDP, but one can see the Atom C3858 pulls ahead due to having 50% more cores albeit at lower clock speeds.
NAMD Performance
NAMD is a molecular modeling benchmark developed by the Theoretical and Computational Biophysics Group in the Beckman Institute for Advanced Science and Technology at the University of Illinois at Urbana-Champaign. More information on the benchmark can be found here. Here are the comparison results for the legacy data set:
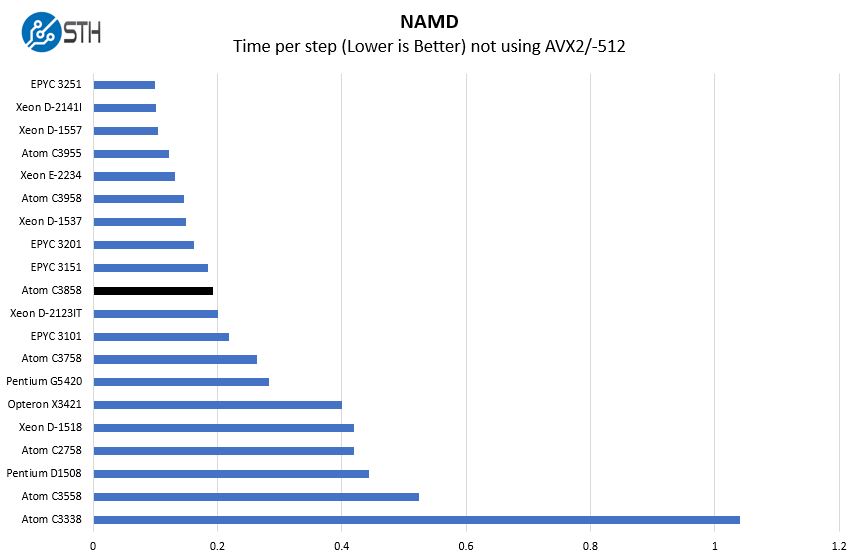
We have not discussed this much, but you will see a fairly large gap between the Atom C3858 and the AMD Opteron X3421. That Opteron X3421 was the top-end SKU for the HPE ProLiant MicroServer Gen10. The C3858 is in a different class of performance.
Sysbench CPU test
Sysbench is another one of those widely used Linux benchmarks. We specifically are using the CPU test, not the OLTP test that we use for some storage testing.
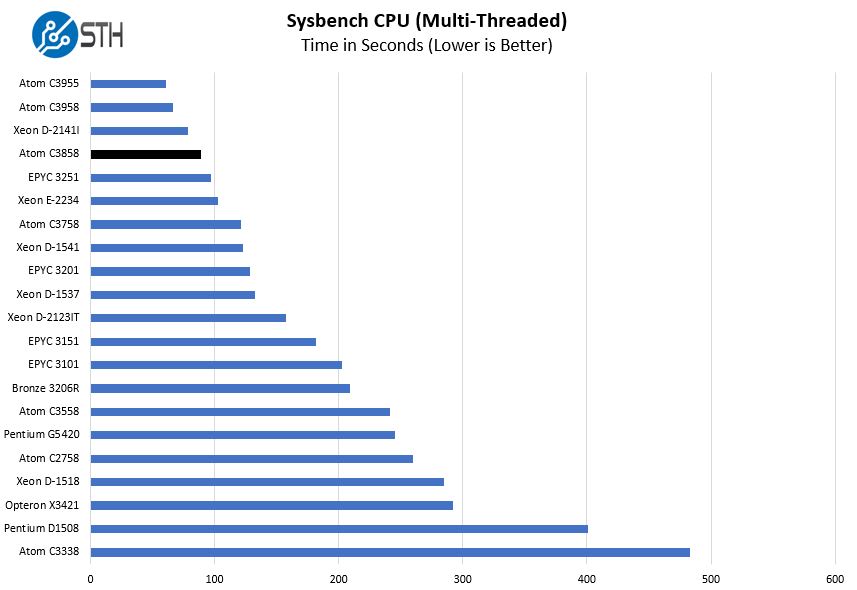
This is a test where we see the 12 low power cores able to take on some of the larger 8 core parts. In some light workloads that scale very well with core counts, we can see these small cores work well.
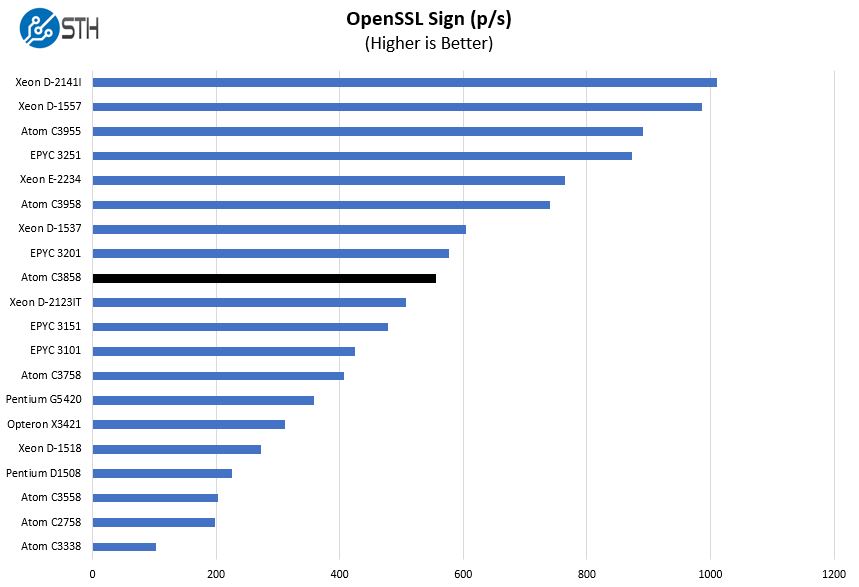
OpenSSL Performance
OpenSSL is widely used to secure communications between servers. This is an important protocol in many server stacks. We first look at our sign tests:
Here are the verify results:
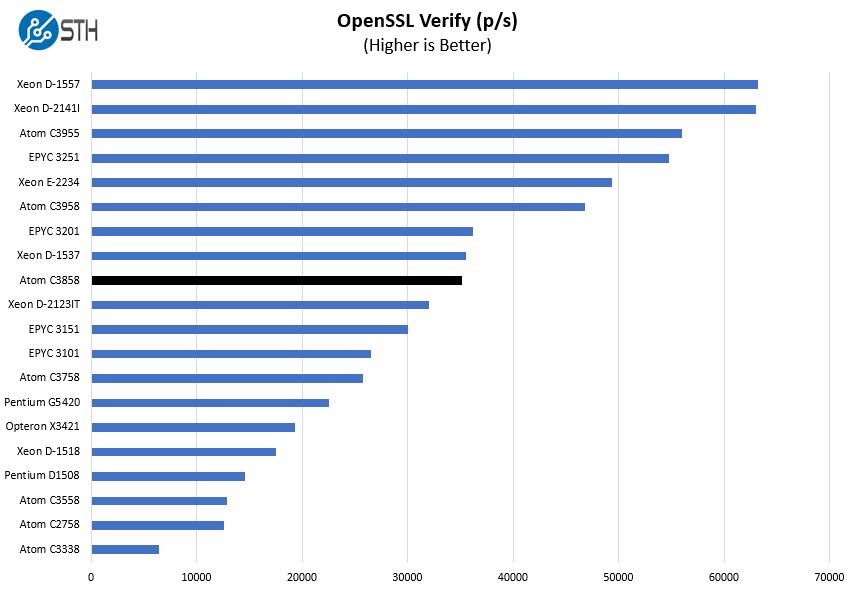
A note here, these are using the standard CPU features, not Intel QuickAssist technology. Intel QAT is an accelerator for compression and encryption that is now several generations old. More programs are now supporting QAT but it still requires explicitly declaring support rather than being a built-in feature. In some OSes, it can be difficult to even get QAT running to accelerate features like ZFS compression.
Intel needs to do a better job expanding the QAT reach to more of its SKUs so we can finally get encryption for “free” on its CPUs. If you have purpose-built hardware then this provides a lot of potential as we showed in our Intel QuickAssist at 40GbE Speeds: IPsec VPN Testing and Intel QuickAssist Technology and OpenSSL Benchmarks and Setup Tips pieces.
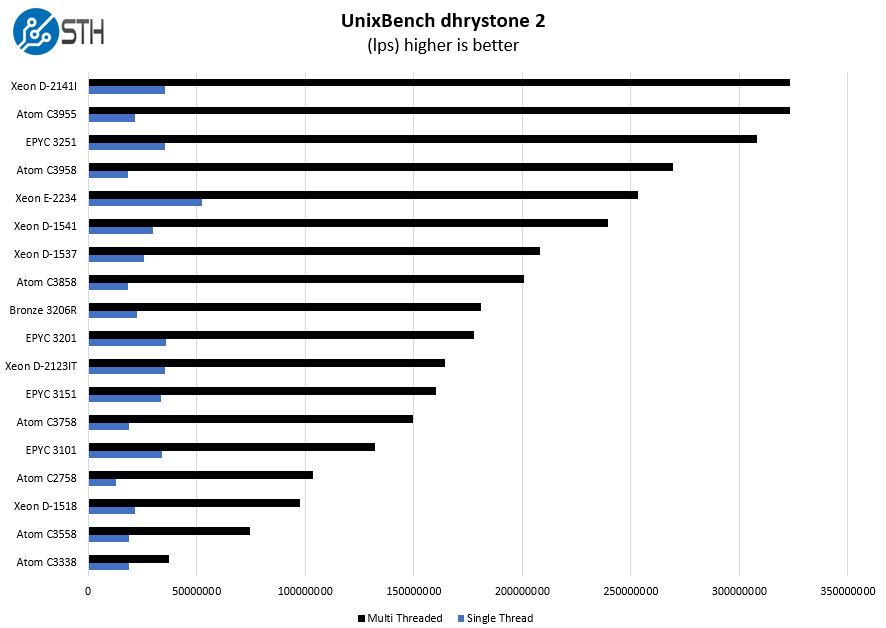
UnixBench Dhrystone 2 and Whetstone Benchmarks
Some of the longest-running tests at STH are the venerable UnixBench 5.1.3 Dhrystone 2 and Whetstone results. They are certainly aging, however, we constantly get requests for them, and many angry notes when we leave them out. UnixBench is widely used so we are including it in this data set. Here are the Dhrystone 2 results:
Here are the whetstone results:
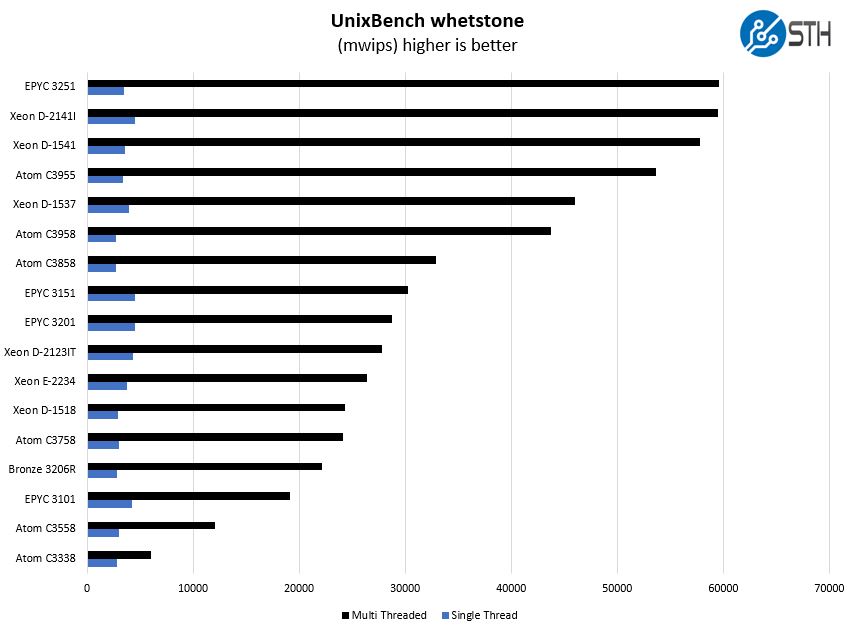
Per-thread performance is not necessarily the best, however, one can clearly see that having many cores helps. Generally, we see the 12-core Atom C3858 fall between the performance levels we would see from four or eight-core chips based on larger more robust microarchitectures from Intel and AMD.
Chess Benchmarking
Chess is an interesting use case since it has almost unlimited complexity. Over the years, we have received a number of requests to bring back chess benchmarking. We have been profiling systems and are ready to start sharing results:
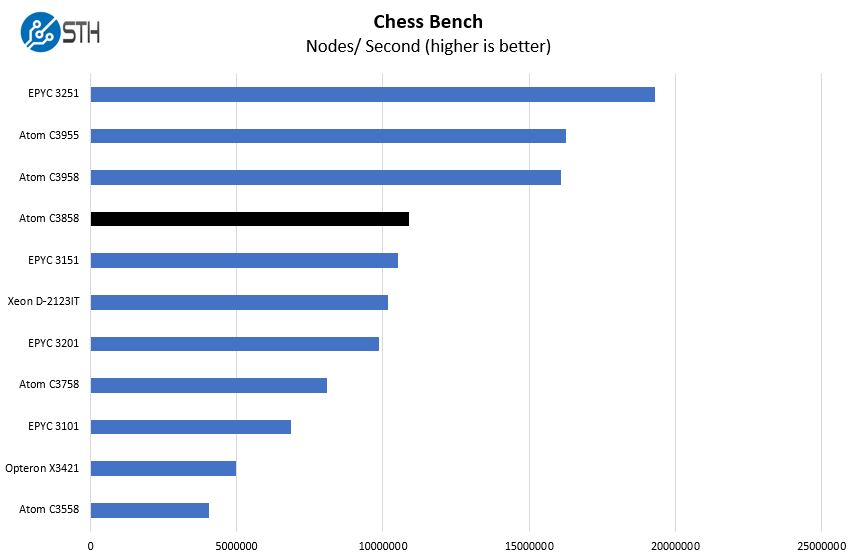
On the chess benchmarking side, the Atom C3858 performs well, and in the 4-8 core range of more robust microarchitectures. Here, features such as the lack of bmi2 instruction support can make for lower performance than we see on higher-end chips.
Next, we are going to have market positioning and our final words.



{kind=link}
I’ve had an issue twice that needed rma for the sfp+ stopped working. One after another when plugged into a Cisco sg500x switch using DAC cables. I’m now using 10gbase-t with transceivers on the switch side.
A server chip similar to renoir could absolutely rock this segment. AMD currently has to focus on the bigger picture, but no doubt as their market share and margins increase, they will have to compete in this segment as well.
@Thomas – totally agree; Renoir’s performance is stunning for the envelope it operates in. Rome definitely pays a power, cost, and density tax for the I/O and memory bandwidth it offers when it tries to compete at lower core counts.
How doe is compare to i3? What is is power consumption?
As others have already sorta touched on, its a bit sad we have been seeing so much movement in the market with Epyc’s release 3 years ago and yet this is the first major release in the segment in quite a while from Intel because AMD has very little pressure here.
One can only hope– It just stinks having to spend so much money relative to the desktop space to hit these performance numbers in these power envelops.
All this tells me is… Buy the Epyc 3251.
I would greatly appreciate further details regarding the RAM that was used for this test. According to the Supermicro website, only one specific 16 GB ECC SODIMM (at 2666 MHz) has been verified to be compatible, but it’s impossible to get hold of. I have tested two different alternatives from Kingston (dual rank and single rank, both 2666 MHz). None worked (systems doesn’t boot).