
FPGAs are cool because they are so flexible. At the same time, there are certain functionalities that are so common that they are more efficient to harden. That is the thrust behind the Intel Agilex 7 with R Tile. Intel now has an R-tile to integrate hardened PCIe Gen5 and CXL IP over EMIB.
Intel Agilex 7 with R Tile Launched Integrated PCIe Gen5 and CXL
The Agilex product line has been out for a long time. Something that we are seeing in this line, as well as lines from AMD and others at this point is providing specific functionality via hardened IP blocks around the FPGA fabric. While flexibility is great, features like DDR interfaces are not something that everyone using a FPGA needs to build IP for every deployment.
As part of this, with the Agilex 7 line, we get a new R-Tile. This R-Tile is connected to the main FPGA fabric via EMIB. It then has hardened functionality to bring PCIe Gen5 as well as CXL functionality to the FPGA. Not having to build one’s own PCIe controller or CXL interface (or licensing IP from others) makes leveraging the functionality easier.
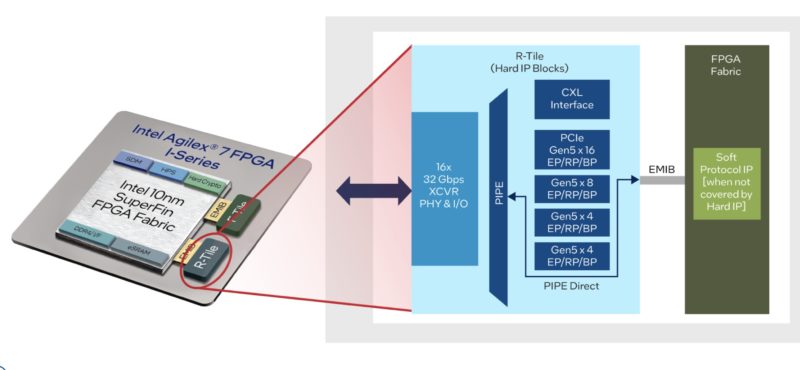
The PCIe Gen5 controller can support up to a PCIe Gen5 x16 link and can be used to create either an endpoint (e.g. when connecting the FPGA to a CPU) or a root port (e.g. when connecting another PCIe device like a NVMe SSD to the FPGA.)
On the CXL side, this is designed to support CXL 1.1 and 2.0 and pre-process CXL flits at the full data rate. Intel is also targeting CXL Type 1, Type 2, and Type 3 support. If you want to learn more about CXL, you can see our Compute Express Link or CXL What it is and Examples.
Given that we are in the early days of CXL, FPGAs like this are used to build new devices. For example, one might build a CXL device that has memory attached and performs crypto-compression to that memory.
Final Words
This is an important step to get more CXL and PCIe Gen5 devices out there. While we expect that over the coming years most PCIe Gen5/ CXL devices sold will use ASICs, having a FPGA solution with a hardened R-Tile means that prototypes can be developed much faster. Many of the CXL demos we have covered on STH over the past few months have used FPGAs to implement CXL functionality.



{kind=link}
“On the CXL side, this is designed to support CXL 1.1 and 2.0 and pre-process CXL flits at the full data rate”
What is a CXL flit? I’ve never heard of it.
I saw a Marvell interview that was very positive about CXL protocol combined with optical switching as a candidate for training the large language models.
It sounds like they are more eager to push in that direction than Intel. Are they pushing ahead faster on cxl 3.0?