Inspur NF5488M5 GPU Baseboard Assembly
The GPU baseboard assembly slides out from the main 4U server chassis.

It actually has its own cover, and own sliding rail system internally. There are even side latches to keep the entire assembly secure. In effect, this is like a smaller version of a server rail kit, just found inside this single-node 4U server.

Taking the cover off, we can see the large hard airflow guide that runs through this section. Airflow is a key design consideration in this chassis, and therefore this is a very heavy duty airflow guide.

Removing that cover, let us work our way through the GPU baseboard. PCIe passes from the CPUs, to the motherboard, to PCIe cables, then to those Broadcom PEX9797 PCIe switches, then through the high-density PCIe connectors and then to the GPU baseboard where it is distributed to each GPU.

There are a total of eight NVIDIA Tesla V100 32GB SXM3 in our system ready for “Volta Next” GPUs in this system. SXM3 GPUs like this are designed to run in this 54VDC system and have 350-400W TDP. Our test system had caps set for 350W and we saw idle on each SXM3 GPU of around 50W as measured by nvidia-smi.
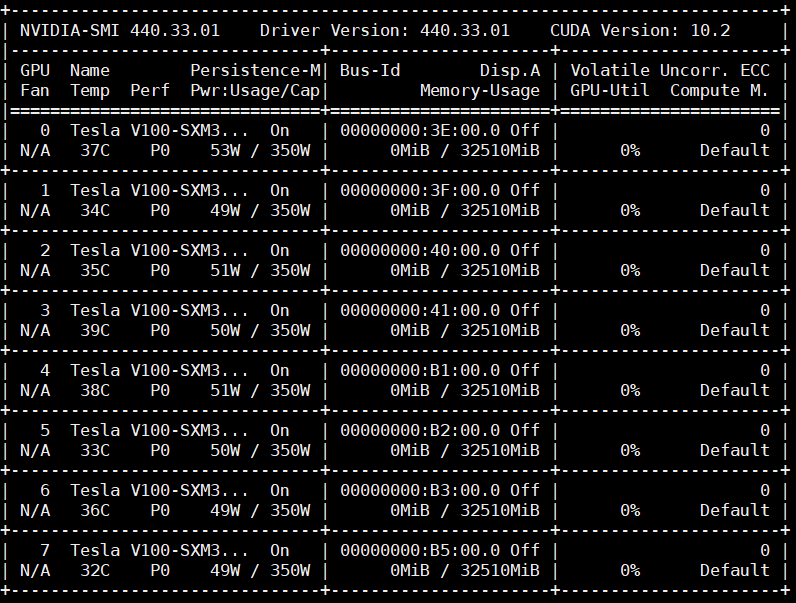
That is higher than the PCIe, and SXM2 versions of the Tesla V100. While all are called “Tesla V100” GPUs, there is a significant gap in capabilities.

Each GPU has its own heatsink covered in an NVIDIA shroud. The whole assembly looks very impressive.

The other key feature of the Inspur Systems NF5488M5 is the interconnect on this board. Years ago, NVIDIA innovated well beyond simply using PCIe for inter-GPU communication. With the Pascal (Tesla P100) generation, NVIDIA introduced NVLink in the SXM2 modules. We actually have a guide on How to Install NVIDIA Tesla SXM2 GPUs using Tesla P100’s. SXM2 systems generally rely on direct attach GPU-to-GPU topologies which limits their scale. The NF5488M5 is a SXM3 system with NVswitch. At STH, we covered NVIDIA NVSwitch details during Hot Chips 30 when the company went into detail around how they work.

There are a total of six NVSwitches on the GPU PCB. By connecting GPUs into this switched fabric, NVIDIA can provide full 300GB/s bandwidth from one GPU to another. With eight GPUs making memory transactions over NVLink, that effectively turns this into a large GPU set with 256GB of HBM2.

These NVSwitch modules require their own heat pipe coolers which you can see in these photos. In the Inspur NG5488M5, they are not being used to their full 16/18 port capacity (2 reserved in the NVSwitch design.)

One may notice the large high-density connectors on the right side of the photo above. These are facing out towards the front of the chassis and are not being used here. By doing some investigation, we found out why. Looking into the forest of GPUs, we found a NVIDIA logo also screened on the GPU baseboard PCB.
We also found this label. The GPU baseboard is actually an NVIDIA HGX-2 baseboard. While NVIDIA sells its DGX-2 16-GPU machine, partners such as Inspur and others have their takes on the partner-oriented NVIDIA HGX-2. The Inspur 16-GPU offering they call the Inspur AGX-5. NVIDIA can bundle the HGX-2 baseboard along with the GPUs and NVSwitches for partners who can then innovate around that platform. While most have used the HGX-2 to provide DGX-2 alternatives with sixteen GPUs, the NF5488M5 is something different on the market with a single HGX-2 baseboard.

Those high-density connectors we see in the front of the board are designed for bridges that extend the NVSwitch fabric between two HGX-2 baseboards in the sixteen GPU designs. This is very innovative making a system with only a single HGX-2 baseboard as the HGX-2 is too dense for many data center rack environments.
Next, we are going to look at some final chassis bits and show the system topologies which are important in a server like this.



{kind=link}
That’s a nice (and I bet really expensive) server for AI workloads!
The idle consumption, as shown in the nvidia-smi terminal, of the V100s is a bit higher than what I’d have expected. It seems weird that the cards stay at the p0 power state (max freq.). In my experience (which is not with v100s, to be fair), just about half a minute after setting the persistence mode to on, the power state reaches p8 and the consumption is way lower (~10W). It may very well be the default power management for these cards, IDK. I don’t think that’s a concern for any purchaser of that server, though, since I don’t think they will keep it idling for just a second…
Thank you for the great review Patrick! Is there any chance that you’d at some point be able to test some non-standard AI accelerators such as Groq’s tensor streaming processor, Habana’s Gaudi etc. in the same fashion?
What’re the advantages (if any) of this Inspur server vs Supermicro 9029GP-TNVRT (which is expandable to 16GPU and even then cost under 250K$ fully configured – and price is <150K$ with 8 V100 32GB SXM3 GPUs, RAM, NVMe etc)?
While usually 4U is much better than 10U I don't think it's really important in this case.
Igor – different companies supporting so you would next look to the software and services portfolio beyond the box itself. You are right that this would be 8 GPU in 4U while you are discussing 8 GPU in 10U for the Supermicro half-configured box. Inspur’s alternative to the Supermicro 9029GP-TNVRT is the 16x GPU AGX-5 which fits in 8U if you wanted 16x GPUs in a HGX-2 platform in a denser configuration.
L.P. – hopefully, that will start late this year.