Dell EMC PowerEdge MX Storage
The Dell EMC PowerEdge MX has a forward-looking storage solution as well. Each node has the ability to have some internal storage. Beyond this internal storage, the chassis has the ability to host additional storage in dedicated storage sleds. We have this section after the networking section of our review because Dell EMC has a similarly forward-looking solution here.
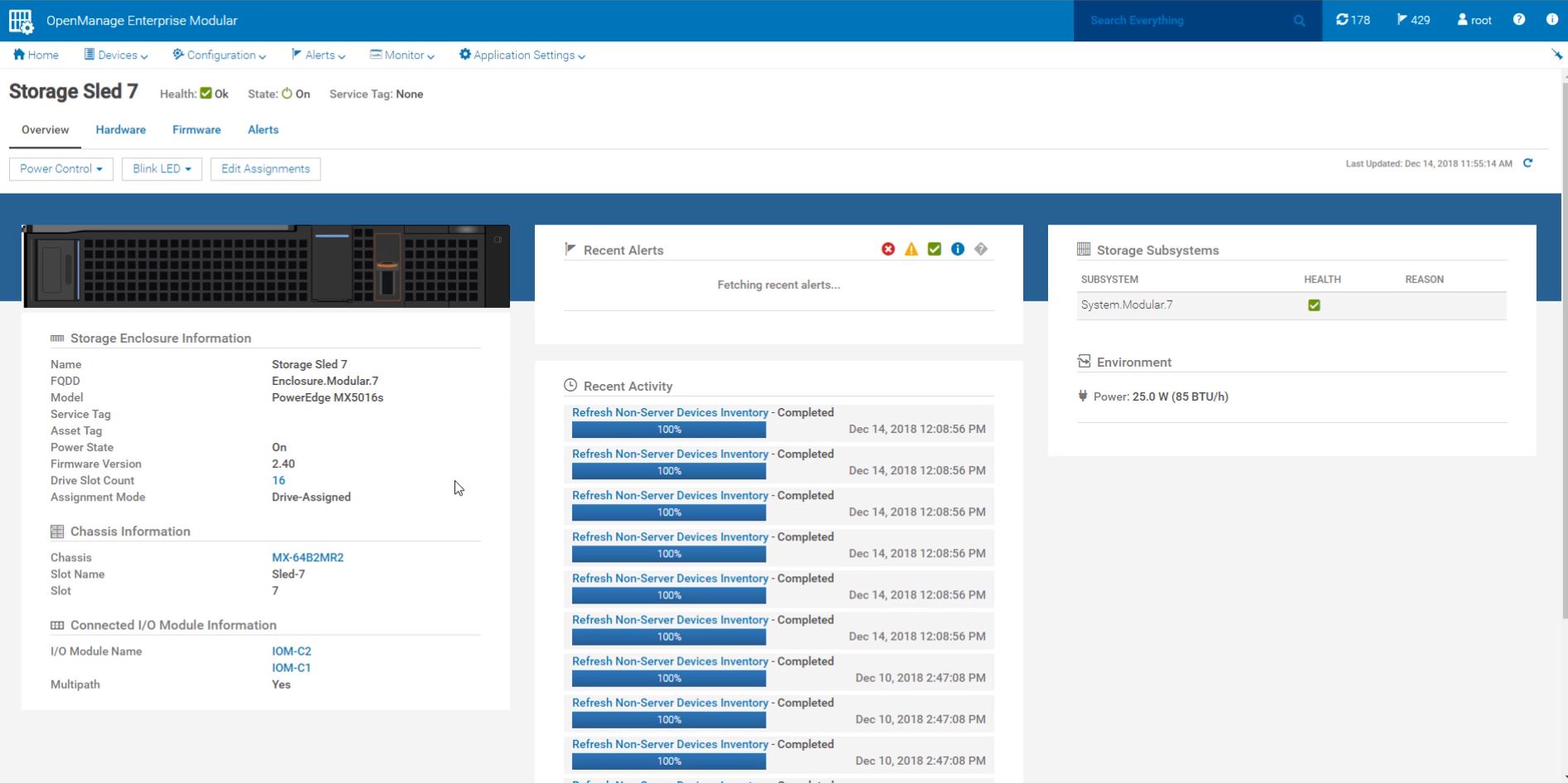
First a look at the sleds. Here is a static model of the Dell EMC PowerEdge MX5016s SAS storage sled.

The PowerEdge MX5016s sleds can be utilized in up to 7 sleds per PowerEdge MX7000 chassis for up to 7x 16 drives or 112 drives. The drives, when installed, are hot-swappable and easy to service when one pulls the sled out.

One other aspect one can see is that the SAS expanders are hot-swappable and plugged directly into the bottom of the PowerEdge MX5016s.

The design allows for one to quickly service the expanders. As of our review’s publication date, this is the only sled publicly available. We have a strong suspicion that there will be an NVMe storage solution implemented in the PowerEdge MX using PCIe switches and NVMe SSDs at some point in the future.
Instead of utilizing cabling or a storage midplane, the PowerEdge MX utilizes a fabric module. On one hand, this may seem like a simple solution, but the impact is profound, much like with the networking backplane. We are currently in the midst of a transition. Yesterday’s storage of SAS is giving way to NVMe and NVMe over Fabric (NVMeoF.) Next generation storage may be connected to something different.
Utilizing a fabric module here, without a midplane makes a lot of sense, not just for the distant future. In 2019, we will see PCIe begin to transition from PCIe Gen3 to Gen4, effectively doubling the per-lane bandwidth. Not long after, we will see a transition from PCIe Gen4 to Gen5. That doubling of bandwidth is a great thing for storage and networking peripherals. On the other hand, it is not something that will work well with traditional midplanes.

As signaling speeds go up over interfaces like PCIe, PCB trace lengths are coming under intense pressure. As we move from PCIe Gen3 to Gen4 in servers, even platforms like the AMD EPYC 7000 will see many motherboard PCB’s reworked with higher-quality (and cost) PCB to allow for Gen4 signaling in the same chassis. In a larger blade chassis, using a PCB midplane creates challenges as signaling tolerances increase. By utilizing a fabric module, the Dell EMC PowerEdge can keep the back-end fabric, plus any necessary elements such as PCIe expanders, SAS expanders, on a single module. That is significantly easier to upgrade over the longer term.
Like other aspects of the Dell EMC PowerEdge MX, the storage fabric and drive sleds are manageable over the company’s management interface.
The parting thought after poking and prodding the Dell EMC PowerEdge MX storage subsystem is that it truly is built for future generations. If NVMeoF becomes dominant, then one can switch the storage module and mezzanine cards and run that in the PowerEdge MX. Likewise, if the market moves where we have something akin to Intel Optane or another persistent memory running over Gen-Z, in theory, the Dell EMC PowerEdge MX is built to handle that. Again, that is a hypothetical, but the design of the PowerEdge MX is such that Dell EMC could deliver that in today’s chassis if that is where the market develops in a few years. Since customers are buying into the PowerEdge MX platform for years to come, this is a serious consideration.



{kind=link}
Ya’ll are on some next level reviews. I was expecting a paragraph or two and instead got 7 pages and a zillion pictures — ok I didn’t count.
I think Dell needs to release more modules. AMD EPYC support? I’m sure they can. Are they going to have Cascade Lake-AP? I’m sure Ice Lake right?
“we now call the PowerEdge MX the “WowerEdge.”
Please don’t.
Can you guys do a piece on Gen-Z? I’d like to know more about that.
It’s funny. I’d seen the PowerEdge MX design, but I hadn’t seen how it works. The connector system has another profound impact you’re overlooking. There’s nothing stopping Dell from introducing a new edge connector in that footprint that can carry more data. It can also design motherboards with high-density x16 connectors and build-in a PCIe 4.0 fabric next year.
Really thorough review @STH
I’d like to see a roadmap of at least 2019 fabric options. Infiniband? They’ll need that for parity with HPE. It’s early in the cycle and I’d want to see this review in a year.
Of course STH finds fabric modules that aren’t on the product page… I thought ya’ll were crazy, buy the you have a picture of them. Only here
Give me EPYC blades, Dell!
Fabric B cannot be FC, it has to be fabric C, A and B are networking (FCOE) only.
“Each fabric can be different, for example, one can have fabric A be 25GbE while fabric B is fibre channel. Since the fabric cards are dual port, each fabric can have two I/O modules for redundancy (four in total.)”
what a GREAT REVIEW as usual patrick. Ofcourse, ONLY someone who has seen/used the cool HW that STH/pk over the years would give this system a 9.6! (and not a 10!) ha. Still my favorite STH review of all time is the dell 740xd.
btw, i think you may be surprised how many views/likes you would get on that raw 37min screen capture you made, posted to your sth youtube channel.
I know i for one would watch all 37min of it! Its a screen capture/video that many of us only dream of seeing/working on. Thanks again pk, 1st class as always.
you didnt mention that this design does not provide nearly the density of the m1000e. going from 16 blades in 10 ru to 8 blades in 7ru… to get 16 blades I would now be using 14 RU. Not to mention that 40GB links have been basically standard on the m1000e for what 8 years? and this is 25 as the default? Come ON!
Hey Salty you misunderstood that. The external uplinks have 4x25Gb / 100Gb at least for each connector. Fabric links have even 200Gb for each connector (most of them are these) on the switches. ATM this is the fastest shit out there.
How are the drives “how-swappable” if the storage sleds have to be pulled out? Am I missing something?
Higher-end gear has internal cable management that allows one to pull out sleds and still maintain drive connectivity. On compute nodes, there are also traditional front hot-swap bays.
400Gbps/ 25Gbps = 8 is a mistake. When NIC with dual ports are used, only one uplink from MX7116n fabric extender is connected 8x25G = 200G. The second 2x100G is used only for Quad port NIC.
Good review, Patrick! I was just wondering if that Fabric C, the SAS sled that you have on the test unit, can be used to connect external devices such as a JBOD via SAS cables? It’s not clear on the datasheets and other information provided by Dell if that’s possible, and the Dell reps don’t seem to be very knowledgeable on this either. Thanks!
I don’t have more money. Can I use 1 switch MX508n and 1 switch MXG610s?